NGS: de-novo сборка генома
Сборка генома и его анализ
Архив с чтениями был получен с помощи команды wget.
wget ftp://ftp.sra.ebi.ac.uk/vol1/fastq/SRR424/009/SRR4240359/SRR4240359.fastq.gz
Далее был создан файл с адаптерами для их дальнейшего удаления.
cat /mnt/scratch/NGS/adapters/* > adapters.fa
Потом из чтений сначала удалялись адаптеры, а потом чтения с качеством ниже 20 и длиной меньше 32.
-
TrimmomaticSE -phred33 SRR4240359.fastq.gz SRR4240359_trimmed.fastq.gz ILLUMINACLIP:adapters.fa:2:7:7 -threads 15 -trimlog trimmomatic.log -
TrimmomaticSE -phred33 SRR4240359_trimmed.fastq.gz SRR4240359_filtered_trimmed.fastq.gz TRAILING:20 MINLEN:32 -threads 15 -trimlog trimmomatic.log
Изначально было 13 557 938 чтений. В результате первой программы осталось 13 502 066 последовательностей (99.59%). Потом фильтрация уменьшила число до 12 184 080 чтений (89.87% от изначального числа). Размер файла сократился сначала с 445 MB до 443 MB, а потом после фильтрации до 385 MB.
Поскольку чтения теперь не короче 30 нуклеотидов, минимальной длиной k-мера для построения графа выберем 31. Для сборки будем использовать пакет программ velvet, а конкретно для этого программу velveth (-short указывает на короткие непарные чтения, а velvet — название папки).
velveth velvet 31 -short -fastq.gz SRR4240359_filtered_trimmed.fastq.gz
Теперь воспользуемся программой velvetg для сборки генома.
velvetg velvet
Из Log файла внутри папки velvet можно узнать, что N50 = 70 607. В файле stats.txt найдем три самых длинных контига и их покрытие (Табл. 1).
| ID | Длина | Покрытие |
|---|---|---|
| 11 | 125 674 | 44.55 |
| 1 | 108 447 | 42.01 |
| 14 | 71 403 | 39.41 |
Все контиги с аномально большими или аномально малыми покрытиями имееют длину меньше k (в нашем случае 31). Такие контиги не попадут в файл contigs.fa, потому что в него попадают только контиги длиной больше или равной максимальной длине k-меров. При помощи grep удалось узнать, что таких 285.
grep '>' contigs.fa | wc -l
Анализ контигов с помощью megablast
Три самых больших контига были картированы на хромосому Buchnera aphidicola (всегда по оси Y, GenBank/EMBL AC — CP009253): контиг 1 (рис. 1), контиг 11 (рис. 2) и контиг 14 (рис. 3). Под каждым дотплотом находится таблица со сводной статистикой по выравниванию (коорднаты выровненного участка, количество совпавших на нем нуклеотидов и количество гэпов).
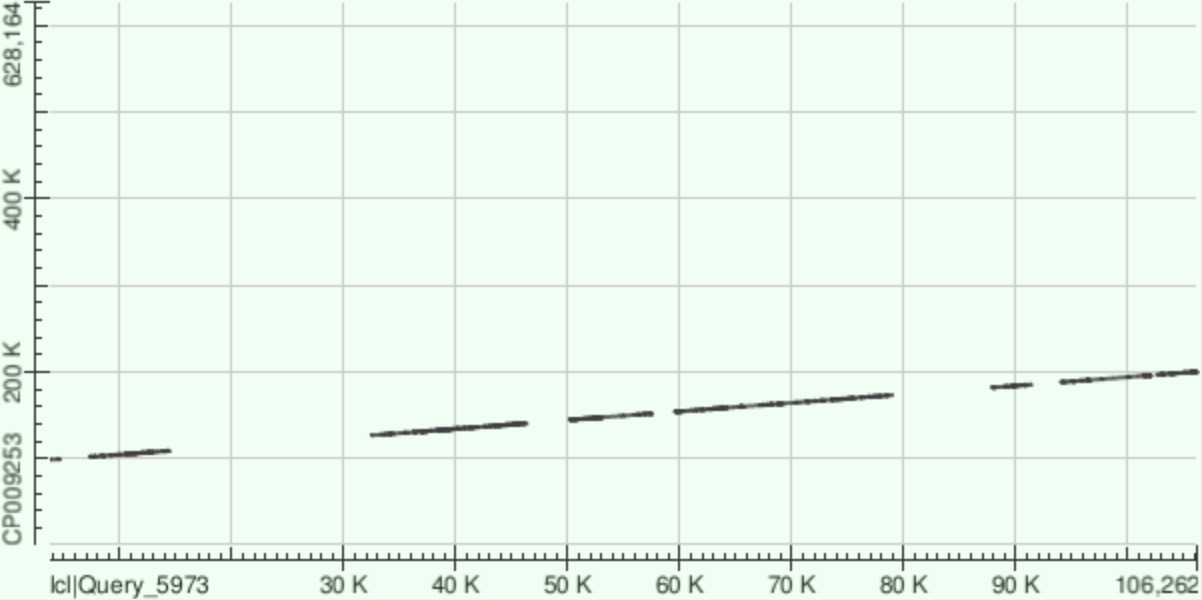
| Участок | Идентичные нуклеотиды | Гэпы |
|---|---|---|
| 153 752 — 161 738 | 6355/8168 (78%) | 264/8168 (3%) |
| 144 368 — 151 796 | 5859/7536 (78%) | 243/7536 (3%) |
| 187 938 — 192 665 | 3840/4801 (80%) | 99/4801 (2%) |
| 161 898 — 166 752 | 3911/4914 (80%) | 112/4914 (2%) |
| 166 750 — 173 180 | 4967/6517(76%) | 159/6517 (2%) |
| 181 712 — 185 289 | 2778/3652 (76%) | 110/3652 (3%) |
| 194 042 — 196 061 | 1640/2070 (79%) | 78/2070 (3%) |
| 192 777 — 193 984 | 985/1209 (81%) | 4/1209 (0%) |
| 196 373 — 198 260 | 1461/1910 (76%) | 73/1910 (3%) |
| 198 467 — 199 381 | 724/922 (79%) | 17/922 (1%) |
| 199 545 — 200 246 | 551/730 (75%) | 52/730 (7%) |
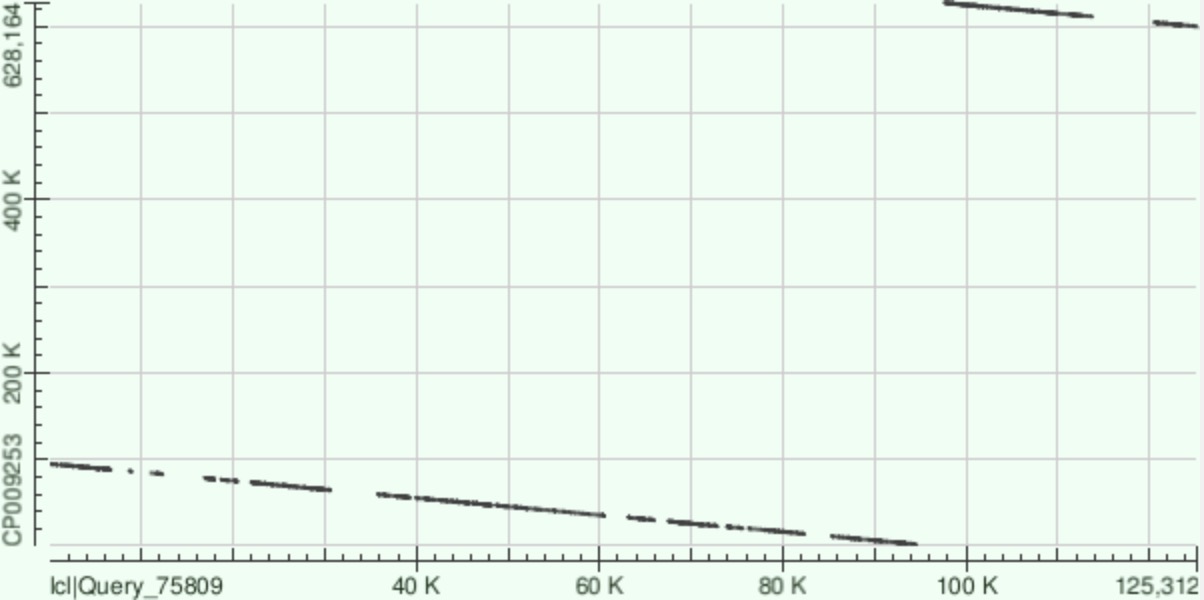
| Участок | Идентичные нуклеотиды | Гэпы |
|---|---|---|
| 2004 — 11103 | 7229/9223 (78%) | 256/9223 (2%) |
| 613658 — 620926 | 5845/7379 (79%) | 184/7379 (2%) |
| 599832 — 604795 | 3946/5046 (78%) | 170/5046 (3%) |
| 621055 — 627104 | 4678/6173 (76%) | 248/6173 (4%) |
| 23067 — 28363 | 4159/5433 (77%) | 219/5433 (4%) |
| 17962 — 20182 | 1902/2231 (85%) | 30/2231 (1%) |
| 14727 — 17919 | 2451/3226 (76%) | 88/3226 (2%) |
| 30013 — 32745 | 2150/2777 (77%) | 84/2777 (3) |
| 20358 — 22183 | 1509/1851 (82%) | 51/1851 (2%) |
| 611633 — 613671 | 1625/2086 (78%) | 66/2086 (3%) |
| 13994 — 14465 | 393/478 (82%) | 9/478 (1%) |
| 611229 — 611524 | 236/297 (79%) | 2/297 (0%) |
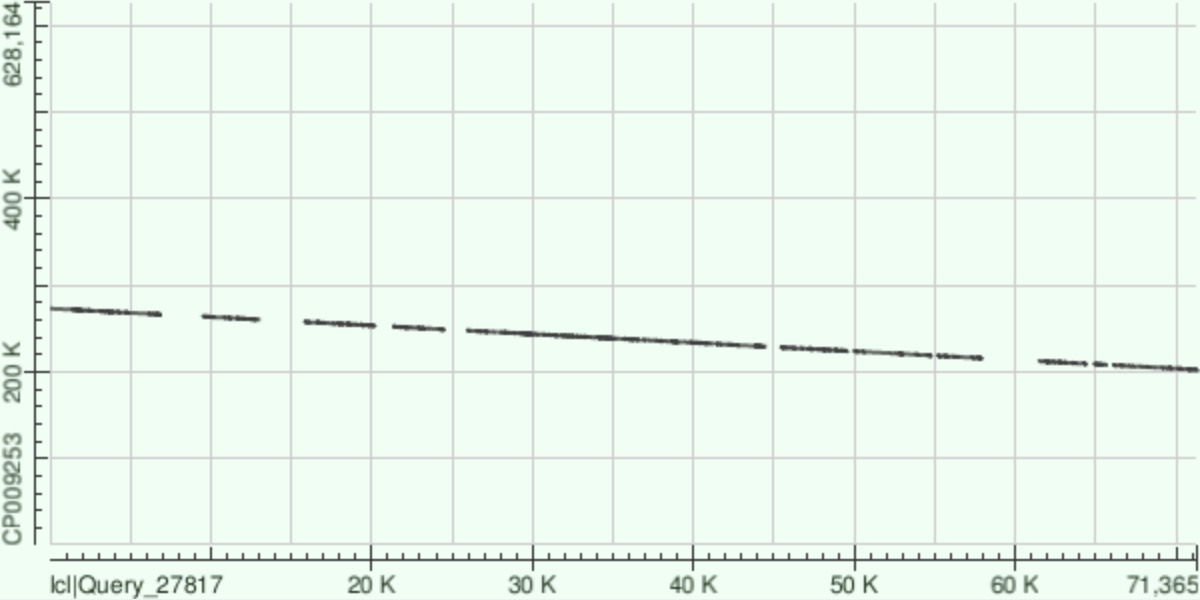
| Участок | Идентичные нуклеотиды | Гэпы |
|---|---|---|
| 236918 — 247596 | 8178/10884 (75%) | 389/10884 (3%) |
| 202390 — 207661 | 4183/5329 (78%) | 137/5329 (2%) |
| 219625 — 223720 | 3342/4130 (81%) | 61/4130 (1%) |
| 224057 — 228137 | 43218/4178 (77%) | 163/4178 (3%) |
| 232358 — 236859 | 3468/4583 (76%) | 134/4583 (2%) |
| 228944 — 232057 | 2499/3165 (79%) | 95/3165 (3%) |
| 260224 — 263784 | 2788/3617 (77%) | 101/3617 (2%) |
| 248967 — 252161 | 2523/3245 (78%) | 92/3245 (2%) |
| 215717 — 218384 | 2145/2713 (79%) | 72/2713 (2%) |
| 209294 — 212243 | 2302/3007 (77%) | 104/3007 (3%) |
| 253223 — 257546 | 3245/4421 (73%) | 195/4421 (4%) |
| 208017 — 208904 | 692/902 (77%) | 25/902 (2%) |
| 218821 — 219491 | 515/676 (76%) | 20/676 (2%) |