PFAM
В качестве домена я выбрал CD4-extracel (PF09191), который содержится в рецепторе CD4, являющимся корецептором для TCR (T-клеточного рецептора). Имеется на поверхности различных иммунных клеток. Этот домен удовлетворяет всем требованиям: 20 последовательностей seed, 171 последовательностей full, 108 средняя длина домена (HMM - 107), 50% сходства, 24% покрытия (оставляет много места для других доменов). Доменная архитектура из 16 возможных была выбрана в разделе Domain organization и наиболее подходящим является структура (A0A663F4F2_AQUCH) совместно с Tcell_CD4_C (PF12104). Такая архитектура свойственна 25 последовательностям (что удовлетворяет условиям меньше половины и больше 20), а также содержит только два домена. Сначала идет домен CD4_extracel, а затем Tcell_CD4_C.
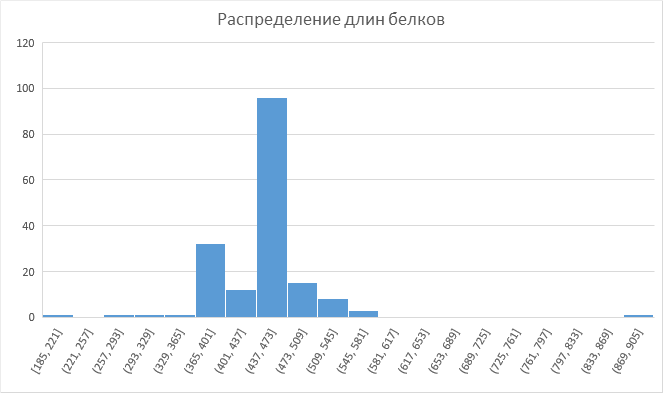
В разделе Alignments я скачал FASTA-файл со всеми белками с данным доменом. Затем из раздела с архитектурой я скопировал все AC в отдельный файл и с помощью скриптаполучил следующий файл. Также была получена гистограмма распределения длины белков семейства, содержащих этот домен, которую я построил в таблице на странице "hist". По гистограмме видно, что преимущественно длина белков лежит в пределах от 437 до 473 АК.
Далее задача заключалась в выравнивании всех белков. Я прибегнул к помощи Jalview, выгрузил туда последовательности и запустил muscle со стандартными параметрами.
Выравнивание можно посмотреть здесь. Процедура очистки заключалась в удалении хвостов (в Pfam посмотрел какие положения занимают домены, затем посмотрел последовательности участков в разделе alignment для каждого из доменов). Также отбраковал белки с уровнем гомологичности свыше 99%. Файл с итоговым выравниванием.Построение HMM профиля
Для постройки HMM профиля я выгрузил выравнивание и с помощью последовательно трех выполненных команд получил профиль:
- hmm2build HMMprof cd4cd4.fasta
- hmm2calibrate HMMprof
- hmm2search -E 0.1 --cpu 1 HMMprof full.fasta > hmmprof.txt
По результатам этих действий был получен профиль длиной 255 и файл, содержащий в себе информацию о весе, E-value и прочих показателях. Таблица на странице "ROC" со всеми данными содержит основную информацию из него. Столбец true включает в себя значение yes, если белок содержит два домена из архитектура и no, если не содержит. Столбец 1-spec и sensetivity показывают специфичность и чувствительность предсказания принадлежности к двухдоменной архитектуре. По этим двум параметрам я построил ROC-кривую (Рис.2), но, к большому сожалению, из-за сильной несбалансированности выборки (25 yes, 121 no) ROC-кривая не является в данном случае достоверным показателем.
Помимо ROC-кривой был построен график падения Score'а (Рис. 3), который может быть использован для определения порога по месту начала падения. Также был построен график функции F1 (Рис. 4)- среднего гармонического специфичности и чувствительности.
По графику падения Score можно увидеть, что спад приходится где-то на 618 (ступенька) и локальный максимум на F1 приходится также на это значение. Соответственно, можно принять, что порог будет именно 618 (к сожалению, проанализировать ROC-кривую не представляется возможным). И визуально проанализировав также можно увидеть, что все белки с двухдоменной организацией находятся выше этого порога и только один из них не является таковым.

