Практикум 9
Мотивы в промоторах Serpentinimonas maccroryi
Поиск оперонов
При помощи сервиса Operon-mapper, загрузив в него файл с последовательностью хромосомы S. maccroryi и координаты генов в ней, я разметила опероны на хромосоме. Полученный файл с координатами и другой информацией можно скачать по ссылке.
После я достала из последовательности хромосомы последовательности по 100 п.н. перед оперонами. Я выбрала из них 50 случайных последовательностей для обучения MEME, оставшиеся последовательности сохранила для теста. Сет последовательностей для обучения и тестовый сет можно скачать по соответствующим ссылкам. После я взяла из случайных мест генома столько же последовательностей длиной 100, сколько в тестовом сете. Этот сет для отрицательного контроля можно скачать по ссылке.
Код, который я написала для выполнения этого практикума, можно найти в колабе по ссылке.
Поиск мотивов при помощи MEME
Я запустила программму MEME на kodomo со следующими параметрами:
meme for_MEME.txt -dna -nmotifs 3 -minw 6
Результаты MEME можно скачать по ссылке.
MEME нашел 3 мотива, но только один из них был с адекватным e-value. Мотивы и e-value можно видеть на рис. 1, 2 и 3 и подписях к ним.

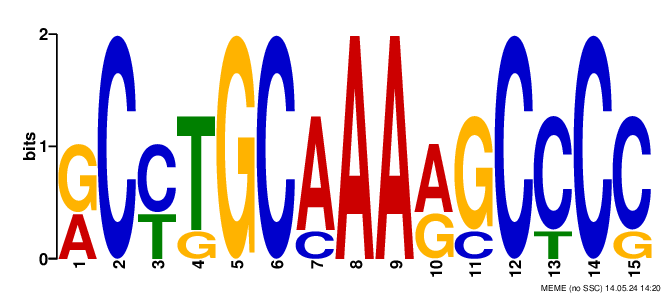
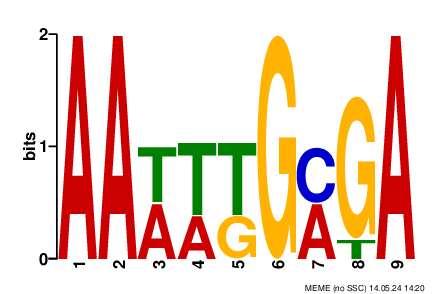
Поиск мотивов из MEME в FIMO
Я запустила поиск этих трех мотивов в тестовом сете и сете отрицательного контроля, используя веб-сервис FIMO с порогом на e-value 0,01 и поиском только по одной цепи. Реузльтаты для тестового сета и для сета отрицательного контроля можно скачать по соответствующим ссылкам.
В таблице 1 можно видеть число находок для каждого из этих паттернов для обоих сетов.
| MEME-1 | MEME-2 | MEME-3 | |
|---|---|---|---|
| Тестовый сет | 320 | 2588 | 576 |
| Сет отрицательного контроля | 91 | 2738 | 336 |
Еще есть смысл смотреть на количество находок, у которых q-value меньше какого-то порога (мы так найдем меньше совпадений, но зато они с меньшей вероятностью будут просто случайными). Результаты для q-value < 0,05 можно видеть в табл. 2.
| MEME-1 | MEME-2 | MEME-3 | |
|---|---|---|---|
| Тестовый сет | 0 | 6 | 0 |
| Сет отрицательного контроля | 0 | 0 | 0 |
Для второго мотива (MEME-2) статистически значимые находки (с q-value < 0,05) находились чаще в первом сете (p = 0,016, односторонний биномиальный тест).
Если рассматривать только количество находок, то для тестового сета оно статистически значимо больше для первого и третьего мотива (p = 2,91 * 10-31 и p = 8,62 * 10-16 соответственно), но меньше для второго мотива.
Я полагаю, что MEME-1 и MEME-3 — действительно какие-то мотивы, с которыми связываются нужные для транскрипции белки (понять, что это за белки, довольно сложно). Думаю, что из-за большого количества находок и малой длины q-value у находок был большой и они не были учтены как значимые. А вот MEME-2, наверное, просто был найден по случайности.