Домены и профили
В базе данных Pfam был выбран домен Carbohydrate binding module 77, удовлетворяющий выставленным критериям:
Число последовательностей в full - 96 ; Средняя длина домена - 108.1 (менее 150); Среднее сходство (identity) - 42%; Средний процент покрытия последовательности белка доменом (coverage) составляет 11.82%; Число доменных архитектур - 22.
Число белков с данным доменом в full, seed, Uniprot составляет 96, 13 и 412 соответственно. Длина HMM-профиля - 109.
Для выполнения задания была выбрана архитектура: Pectate_lyase_4, CBM77-доменами (41 последовательность)

Я скачала последовательность семейства, сохранила в отдельный файл их AC, проверила наличие дубликатов в excel посредством условного форматирования (в итоге, оказались три пары дубликатов: A0A1Y6C4C1_9ALTE, A0A2G5L0T8_9BACT, A0A1I0QZE8_9FIRM), редактируем файл с последовательностями и AC всех белков, оставляя по одной последовательности из дубликата. АС последовательностей белков внутри одной архитектуры нашла на Pfam, вставила их в промежуточный файл raw_protAC.txt. Затем необходимо было получить нормальный список. Все манипуляции были проделаны с помощью скрипта
Далее получим последовательности белков с выбранной архитектурой с помощью bash и EMBOSS, предварительно поработав с АС белков, чтобы EMBOSS не ругался (питоновский скрипт написан выше). Их получилось 39 из 41, потому что двух последовательностей (A0A4R6MMW4_9BACL, A0A561Q094_9BACL) нет в Uniprot. Поэтому их скопируем из full.fasta и добавим в файл. Программы для скачивания последовательностей: for i in $(cat AC_for_emboss.txt); do seqret -filter "uniprot:$i" | cat >> domain.fasta; done и информации о длине последовательностей из full.fasta for i in $(cat AC_domain_emboss.txt); do echo "$i" >> len.txt; infoseq "uniprot:$i" -filter -only -length | cat >> len.txt; done (для удобства работы в excel с помощью скрипта(ссылка на который представлена выше) были получены списки АС со соответствующими длинами):
Построим выравнивание в Jalview с помощью алгоритма muscle. Согласно данным Pfam, координаты первого домена (Pectate_lyase_4) - 284:472, а второго (CBM77) - 661:767. Исходя из этого в нашем выравнивании обрезали участки перед первым и после второго домена, затем убрали несколько последовательностей, которые плохо выровнялись и которые имели 99-100% сходство. fasta файл с новым выравниванием.
Построим HMM-профиль нашей двух-доменной архитектуры с помощью hmm2build: hmm2build HMM_profile new_aln.fa, откалибруем (нормируем вес): hmm2calibrate HMM_profile, проведём поиск профиля по последовательностям из full.fasta, получив файл, который используем для таблицы: hmm2search -E 0.1 --cpu=1 HMM_profile full.fasta > hmm.txt
Результаты:
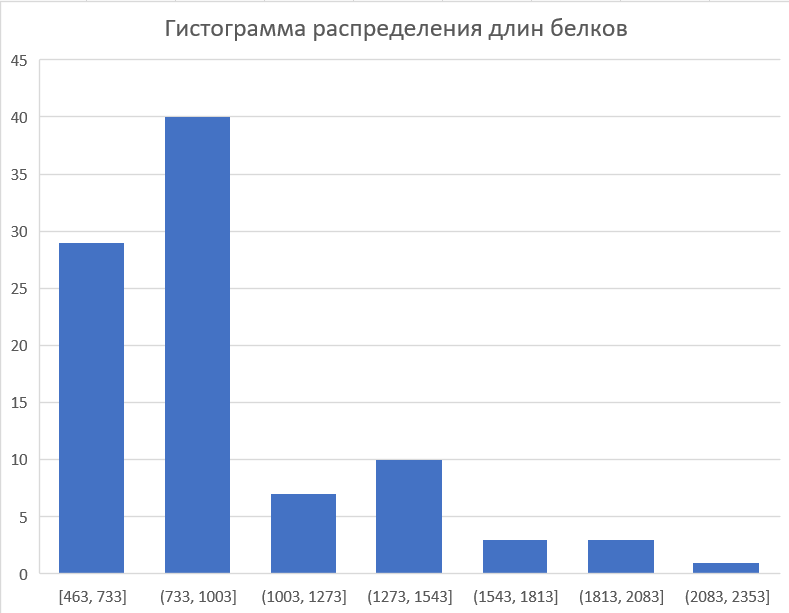
Видно, что для белков из исследуемого домена характерна длина в диапазоне 733-1003. Использовались длины последовательностей домена из полного набора.
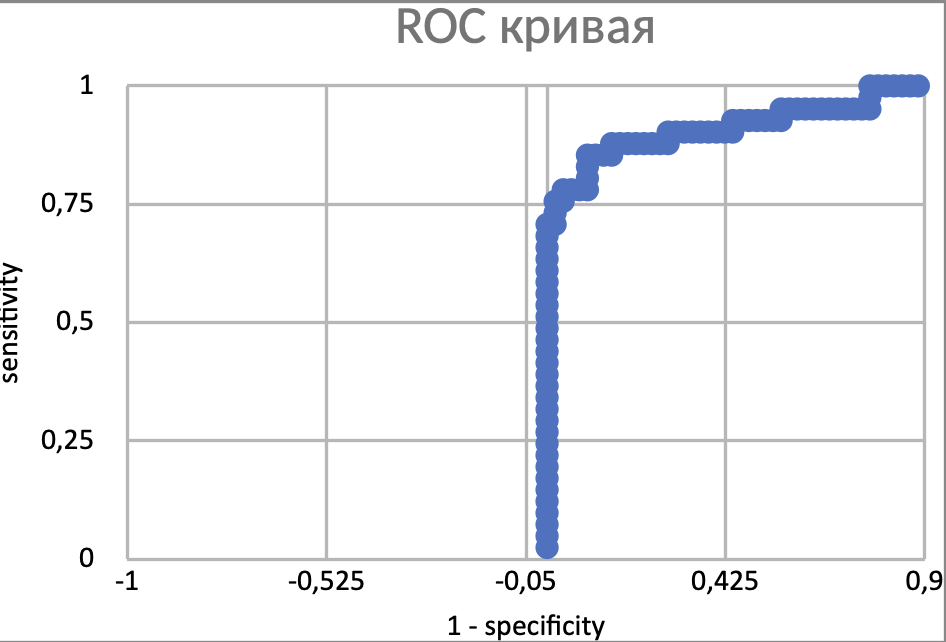
По RОС-кривой мы можем определить порог: для этого измерим наибольшее расстояние от ROC-кривой до диагонали, соединяющей начало и конец. Здесь эта точка, примерно, с координатами (-0.865384615;0.853658537) и весом 552,90

График F1: при миниальных значениях чувствительности линия плавная, затем растёт, достигает пика и убывает; локальный минимум в точке (618.90;0.820512821).