Работа с пангеномами с помощью NPG Explorer
В данном практикуме представлены задания, направленные на освоение программы NPG Explorer.
Подготовка к работе
Для работы были выбраны геномы 5 штаммов архей вида Methanosarcina mazei. Ознакомиться с выбранными штаммами и записями об их сборке генома можно по таблице ниже.
| Выбранный штамм | Число хромосом | AC сборки в EMBL-EBI | AC сиквенса в EMBL-EBI |
|---|---|---|---|
| M. mazei Go1 | 1 | GCA_000007065.1 | AE008384.1 |
| M. mazei SarPi | 1 | GCA_000970185.1 | CP009511.1 |
| M. mazei WWM610 | 1 | GCA_000970165.1 | CP009509.1 |
| M. mazei LYC | 1 | GCA_000970225.1 | CP009513.1 |
| M. mazei C16 | 1 | GCA_000970245.1 | CP009514.1 |
Выбор оказался довольно удачным, так как все штаммы содержат по 1 хромосоме и не содержат последовательностей для крупных плазмид.
Запуск программы NPGE
Для запуска был подготовлен файл с необходимой информацией о выбранных сборках (genomes.tsv). Был запущен следующий набор операций:
npge -g npge.conf
npge Prepare
npge Examine
Оценка сходства геномов: файл
Исправленные параметры: WORKERS = 1, MIN_IDENTITY = 0,885 (npge.conf)
npge MakePangenome
stdout и stderr программы: log_make
npge PostProcessing
stdout и stderr программы: log_processing
По ссылкам ниже можно ознакомиться с выходными файлами.
| Файл | Содержание |
|---|---|
| pangenome.info | Основная информация о блоках |
| nj-global-tree.tre | Дерево геномов, по объединенному выравниванию g-блоков |
| features.bs | Описание генов |
| mutations.tsv | Описание всех мутаций в блоках |
| consensuses.fasta | Построенные консенсусы блоков |
| pangenome.bs pangenome.bi |
Характеристика блоков |
Стабильное ядро нуклеотидного пангенома
Характеристика стабильного ядра, состоящего из s-блоков, приведена в таблице ниже.
| Число s-блоков | 937 (15822383 bp) |
| Размер нуклеотидного ядра (% нуклеотидов в ядре от числа нуклеотидов во всех геномах) | 76,88% |
| % консервативных колонок в объединённом выравнивании s-блоков | 98,1611% | Длина построенных фрагментов | min : 97 max : 33703 |
Описание крупных делеций
Для выполнения данного задания файл pangenomes.bi был проанализирован с помощью Excel (выполнялись разбиение по столбцам и сортировка по убыванию). В результате для штаммов C16 и WWM610был найден блок h2x11707 (в пределах g5x46485), соответствующий делеции участка в 11707 bp в оставшихся трёх штаммах.
Данный блок содержит, в большинстве, гипотетические белки (hypothetical protein), поэтому большинство из них не приведены в отчете:
- 14556 CDS MSMAC_1062 hypothetical protein (MMC16), 276 bp
9108 CDS MSMAW_2349 hypothetical protein (MMWWM), 276 bp
882-1158 позиции данного блока - 14561 CDS MSMAC_1067 hypothetical protein (MMC16), 309 bp
9112 CDS MSMAW_2353 hypothetical protein (MMWWM), 309 bp
4150-4458 позиции данного блока - 14571 CDS MSMAC_1077 Site-specific recombinase (MMC16), 675 bp
10926-11600
9121 CDS MSMAW_2362 Site-specific recombinase (MMWWM), 951 bp
10650-11600
Как видно из выдачи NPG, данная делеция затронула малозначимый участок генома, не кодирующий важных белков. Попробуем найти более интересный с биологической точки зрения индель.
Произведя поиск в окне блоков NPG h-блоки с умеренным содержанием генов (3-8), я остановил выбор на двух интересных примерах.
Блок h3x855: присутствует у штаммов SarPi, WWM610 и C16, хотя если у двух первых находится в блоке i4x3335 (в нем же находятся 2 штамма с делецией), то у C16 такой блок отнесен к i1x5940, что говорит нам о возможной транслокации.
В пределах данного блока встречается ген MSMAC_3057 Rhodopirellula transposase (штамм C16) длиной 303 bp. Этот белок относится к семейству транспозаз бактерии Rhodopirellula, что говорит о возможном горизонтальном переносе генов.
Блок h2x4310: присутствует у штаммов Go1 и LYC. Данный блок содержит 9 генов, однако интерес представляют 2 позиции:
- MM_2982 antibiotic resistance protein (MMGO1) и выравнивающийся на него MSMAL_1483 PPOX class probable F420-dependent enzyme (MMLYC). Оба данных белка могут обеспечивать антибиотик-резистентность.
- MM_2981 type I restriction-modification system (MMGO1) и MSMAL_1482 Type I restriction-modification system (MMLYC). Данные белки являются сайт-специфичными аденил-метилтрансферазами и участвуют в системе рестрикции-модификации, которая используется прокариотами для защиты от вирусов.
В двух приведенных примерах, в h-блоки попали предсказанные белки, которые несут преимущество для архей, несущих их. Данный пример хорошо иллюстрирует горизонтальный перенос генов, что позволяет выдвинуть предположение о таком происхождении выбранных инделов.
Перестановка синтений в g-блоках
В данном задании, визуально изучив g-блоки на пример перестановок, была обнаружена перестановка h4x1875 > в пределах блока g5x256839. Данное событие было вывлено только в штамме WWM610.

Ошибка аннотации сборок
В данной части, я проанализировал аннотации последовательностей на пример несовпадения описываемых генов. Приведу несколько примеров, демонстрирующих недостаточную аннотируемость выбранных сборок.
Пример 1a: s5x22996 с позиции 439 несет аннотацию гена LSU ribosomal protein L3P (MM_2124) для штамма Go1. Стоит отметить, что запись соответствующего белка в UniProt несет статус Reviewed, соответствующие участки остальных последовательностей очень(!) хорошо выравниваются на данный ген, но при этом не аннотированы.
Пример 2: s5x18321 с позиции 7539 (reverse) несет аннотацию гена L-threonine 3-O-phosphate decarboxylase для всех штаммов кроме Go1, для которого этот же ген указан как histidinol-phosphate aminotransferase. Если найти запись UniProt для данного гена Go1 (MM_2060) и изучить историю изменений, то можно увидеть, что данный белок был переопределен как L-threonine 3-O-phosphate decarboxylase (соответствует остальным штаммам). В устаревшей аннотации сборки же это не изменилось.
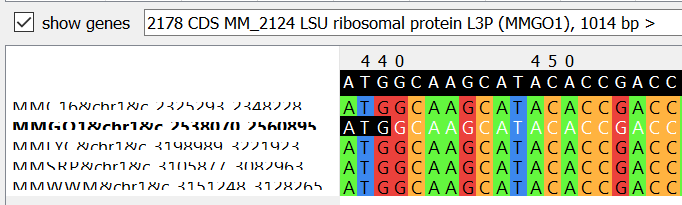
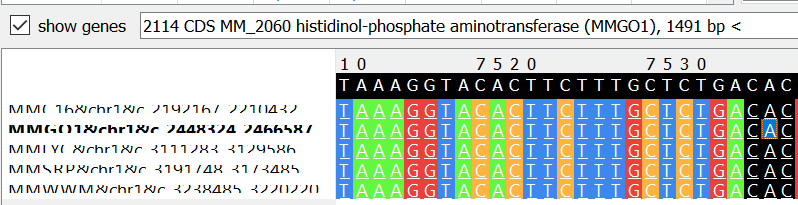
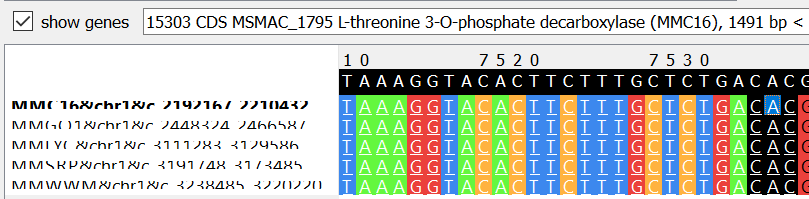

Вероятное объяснение ошибок: сборка штамма Go1 является референсной для выбранного вида, поэтому скорее всего характеризуется лучшим качеством аннотации. Но в примере 2 мы видим абсолютно противоположную картину, так как референсная сборка более старая, нежели чем остальные выбранные.
Финал
