Обработка результатов секвенирования по Сэнгеру
В данном практикуме с помощью программы UGENE и дополнительных инструментов был произведен анализ предоставленных прочтений секвенатора и сборка контига.
1.Сборка последовательности по прочтениям
Исходные файлы: forward-read, reverse_read.
Результат: консенсус в формате FASTA

Выравнивания:
- Исходных последовательностей(не "почищенных") с консенсусом fasta-файл
- Отредактированных последовательностей с референсом fasta-файл
Для выбора референсной последовательности прочтения сперва были mapped на forward-рид и отредактированы. Полученный на этом этапе консенсус был забластован с помощью blastn NCBI. В выдаче с 99+ Identity присуствовали гены cytochrome oxidase subunit 1 (COI) голожаберных моллюсков. В качестве конечного референса я взял вторую находку - MG421031.1 Coryphella verrucosa voucher BIOUG14670-C05 cytochrome oxidase subunit 1 (COI) gene, partial cds; mitochondrial.
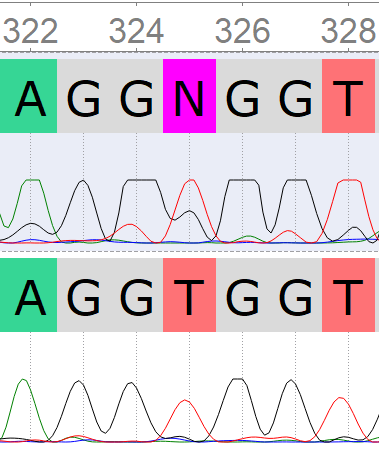
Полиморфизм 325_F: исправлен по R-прочтению.
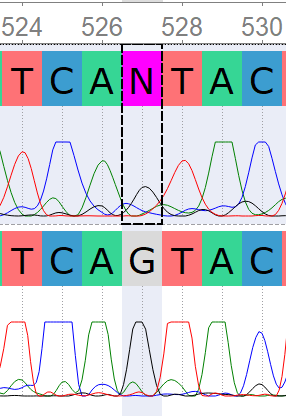
Полиморфизм 527_F: визуально G, также в R-риде.
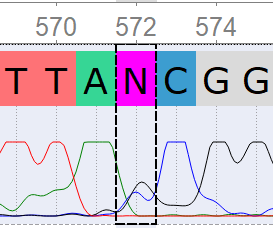
Полиморфизм 572_F: решено оставить S (G or C).
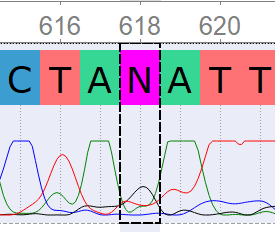
Полиморфизм 618_F: визуально определяемый G.
Характеристика хроматограммы:
- Нечитаемые участки F: 1-134 // 673-715 (автоматический порог в 30 оставил части этих участков)
- Нечитаемые участки R: 1-40 // 578-704 (автоматический порог в 30 оставил части этих участков)
- Неравномерность сигнала: визуально, F и R прочтения характеризуются соотносимыми по высоте пиками (в концах - более высокие и хаотичные, в "хорошей" середине - дискретные, равного уровня).
- Неравномерность шума: визуально, F и R прочтения характеризуются сильным хаосом в своих концах (пики сливаются, пересекаются и обладают разной формой), однако в "хорошей" середине они выравниваются по высоте (за редким исключением) и четко разделяются между собой. В хроматограммах встречаются слившиеся между собой пики от сигналов на гомо-трактах(олиго Т/олиго G и др.), однако определить количество нуклеотидов в них не представляет сложности.
- Оценка качества прочтений: проведена с помощью Python и представлена ниже (по образцу кода С.Исаева).
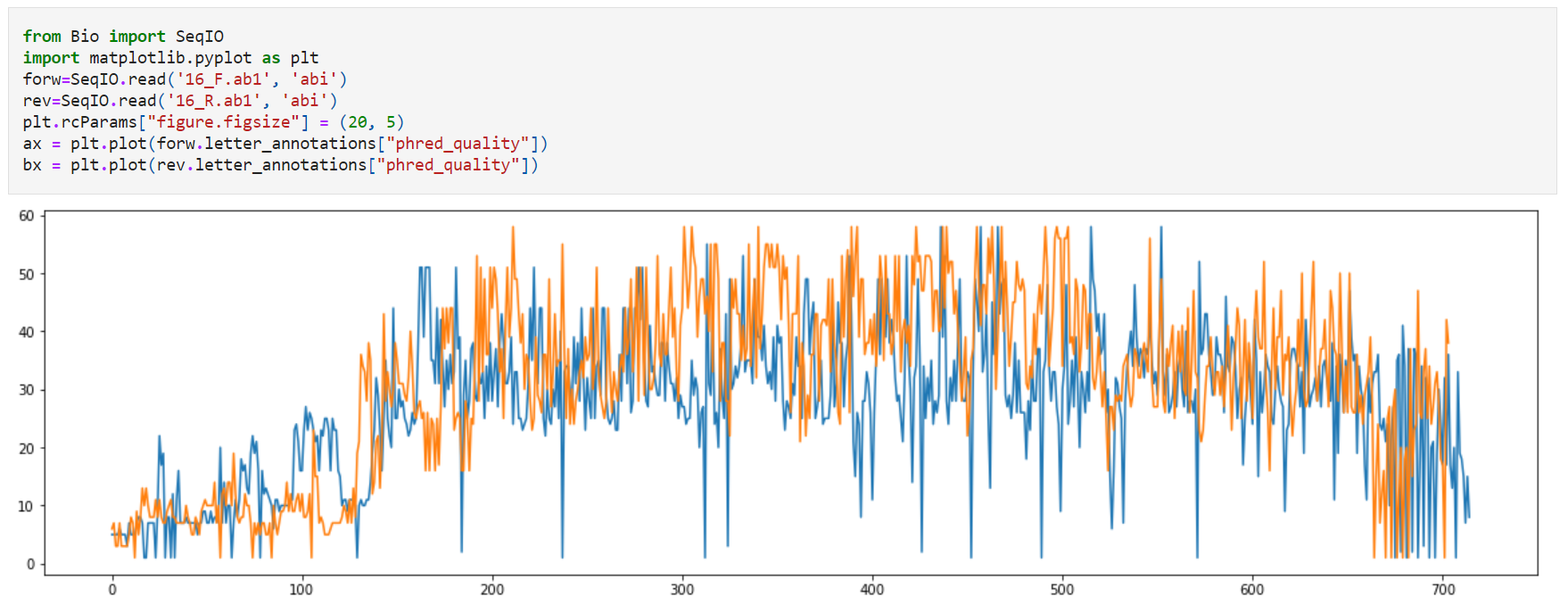
Вывод: Хроматограммы обоих прочтений, на мой взгляд, довольно качественные и отображают закономерности, наблюдаемые при считывании капиллярного секвенирования.
2.Пример нечитаемой хроматограммы
В качестве примера был взят файл WS2943_SP6R.ab1 из директории /bad. Для рассмотрения выбран участок с 37 по 78 нуклеотид.
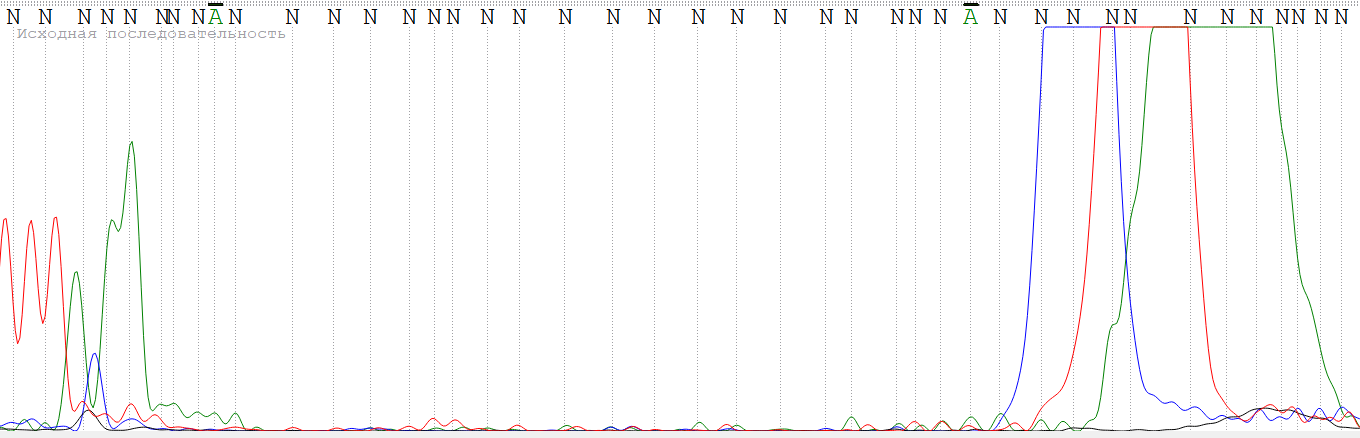
Данный участок начинается с пиков высокого сигнала, которые частично сливаются и пересекаются друг с другом, что нарушает алгоритм base-calling'а. После высоких пиков сигнал сильно падает (неизвестно, присутствует ли в данном участке сигнал от секвенируемой ДНК или же это просто шум). После относительного падения сигнала на хроматограмме видны огромные пики C-T-A.
Возможные проблемы:
- Плохое прочтение в начале: данный участок находится в близости от 5'-конца, вероятно праймеры смогли отжечься на матрицу, но возникла проблема при синтезе дальнейших участков. При секвенировании таких коротких образцов вся последовательность попадает "в участок плохого распознавания" и не даёт четких результатов.
- Отсуствие сигнала в середине: отсутствие ПЦР продукта(проблемы с праймерами, недостаток матрицы, деградация матрицы). Возможно образец был загрязнен ингибиторами (соли, фенолы, ЭДТА и др.). Можно предположить, что с ПЦР смогли поднять лишь небольшой участок вблизи праймера (~20 bp на праймер и 20 bp после), который и секвенировали.
- Высокие пики C, T, G: загрязнение образца пятнами красителей.