Изучение сигналов в геноме
Сигнал в геноме Zea mays
Сигнал центромерной ДНК Zea mays CentC представляет собой тандемные повторы длиной от 100 bp.
С последовательностью, полученной из GenBank, можно ознакомиться по ссылке >KT724900.1
Эта последовательность связывается центромерной изоформой гистона CENH3, которая замещает классический гистон H3.[1]
Данный сигнал крайне эффективен, так как обеспечивает формирование центромер во всех классических А-хромосомах и даже в добавочных B-хромосомах[2], полностью связываясь с CENH3.
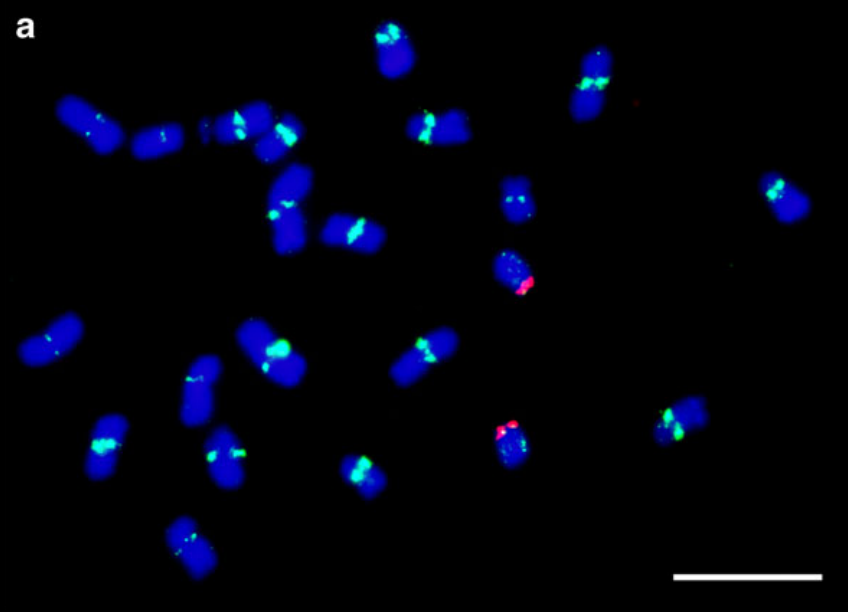
Взято из Peng S.F. et al (2011)[2]
Построение PWM для последовательности Козак H.sapiens
В данном задании предлагается исследовать последовательность Козак в геноме человека. Для этого использовался скрипт М. Смирнова, за что автор выражает ему благодарность. Со скриптом можно ознакомиться по ссылке.
С помощью скрипта были выбраны 100 случайных генов человека, из которых вырезался фрагмент 7 bp до + стартовый ATG + 3 bp после. Полученные наборы можно посмотреть по ссылкам: обучение (n = 40) и тестовый (n = 60)
По выравненным без гэпов участкам из тестовой выборки была построена Позиционная весовая матрица (с помощью скрипта, ε = 0,8, GC-content = 41%[3]):
| 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 | 13 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| A | -3.305 | -0,532 | -0,936 | 0,155 | -1,189 | -0,72 | -1,189 | 1,761 | -5,89 | -5,89 | -0.532 | -0.72 | -1,89 |
| T | 0.536 | -0.72 | -1,89 | -0.532 | -1,89 | -1,189 | -2.43 | -5,89 | 1,761 | -5,89 | -1,498 | -1,498 | -1,189 |
| C | 0,443 | 0,443 | 1,062 | 0,159 | 1,22 | 0,785 | 0,159 | -5,365 | -5,365 | 2.286 | 1,43 | 0,566 | 1,363 |
| G | 0,443 | 0,785 | 0,785 | 0,308 | 0,68 | 0,785 | 1,554 | -5,365 | -5,365 | -5,365 | -0,411 | 1,062 | 0,443 |
Для положительного контроля были выбраны 60 тестовых последовательностей, для отрицательного с помощью скрипта выбраны 60 последовательностей вокруг не стартового ATG. Как можно заметить из (+)-контроля, наша PWM действительно верно считает веса последовательностей.
(-)-контроль также подтверждает исправную работу PWM, так как выдаваемые веса, даже на взгляд, значительно меньше истинной последовательности Козак.

Информационное содержание последовательности Козак H.sapiens
В данном разделе по выбранным генам исследовалось информационное содержание последовательности Козак. Для этого строилась матрица информационного содержания, доступная по ссылке.
Для удобства матрица информационного содержания (IC(b,j)) продублирована ниже:
| 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 | 13 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| A | -0.089 | -0.112 | -0.146 | 0.045 | -0.155 | -0.132 | -0.155 | 1.761 | 0 | 0 | -0.112 | -0.132 | -0.148 |
| T | 0.224 | -0.132 | -0.148 | -0.112 | -0.148 | -0.155 | -0.128 | 0 | 1.761 | 0 | -0.156 | -0.156 | -0.155 |
| C | 0.117 | 0.117 | 0.447 | 0.03 | 0.576 | 0.27 | 0.03 | 0 | 0 | 2.286 | 0.783 | 0.165 | 0.712 |
| G | 0.117 | 0.27 | 0.27 | 0.072 | 0.216 | 0.27 | 0.93 | 0 | 0 | 0 | -0.068 | 0.447 | 0.117 |
| IC(j) | 0.3679 | 0.1427 | 0.4226 | 0.0351 | 0.4889 | 0.2535 | 0.6769 | 1.7612 | 1.7612 | 2.2863 | 0.4473 | 0.3239 | 0.5258 |
После определения информационного содержания сигнала полученное выравнивание было загружено в программу WebLOGO3. Из полученной диаграммы видно, что последовательность Козак содержит большое количество G/C в положениях до старт-кодона, которые имеют чуть больший вес, чем нуклеотиды после ATG. Однако эта последовательность не так информационно значима как сам старт-кодон.
References
- Zhong C. X. et al. Centromeric retroelements and satellites interact with maize kinetochore protein CENH3 //The Plant Cell. – 2002. – Т. 14. – №. 11. – С. 2825-2836.
- Peng S. F., Cheng Y. M. Characterization of satellite CentC repeats from heterochromatic regions on the long arm of maize B-chromosome //Chromosome Research. – 2011. – Т. 19. – №. 2. – С. 183-191.
- Lander E. S. et al. Initial sequencing and analysis of the human genome. – 2001. link