Поиск мотивов среди гомологов PDXS_BACSU. Программа MEME
Целью данной работы является поиск мотивов (блоков достоверного выравнивания) белка PDXS_BACSU с помощью программы MEME (Multiple Em for Motif Elicitation).
Выполнение работы
Для анализа был взят набор из 25 невыровненных последовательностей гомологов белка.
Запуск программы МЕМЕ производился двумя способами:
I. С помощью консоли Linux. Команда «ememe sequences.fasta memeout -nmotifs 3» выполняет запуск интегрированной в EMBOSS программы МЕМЕ. Используются данные из sequences.fasta, создается папка memeout, которая в том числе содержит выдачу данных в виде html-страницы.
II. С помощью сервиса MEME Suite. На сервис можно загрузить файл или сами последовательности, а также e-mail для получения результатов. Способ является более приятным из-за более удобной выдачи результатов. Так html-страницу с результатами можно увидеть перейдя по ссылке (плюс в том, что она доступна с любой точки).
MEME определила в качестве мотивов 3 фрагмента длиной 50 аминокислотных остатков (поиск при ограничении по 4 мотивам выдал те же мотивы и еще один короткий, длиной 29). Некоторая информация о них представлена в таблице 1.
Таблица 1. Информация о мотивах из выдачи MEME.
| Мотив | Число последовательностей («все» - значит, встретился во всех 25 последовательностях) | Длина мотива | E-value | LOGO |
| 1 | Все (25) | 50 | 1.8e-888 | Рис. 1 |
| 2 | Все (25) | 50 | 4.8e-831 | Рис. 2 |
| 3 | Все (25) | 50 | 9.7e-744 | Рис. 3 |
Примечания к таблице
Найденные мотивы встречаются во всех взятых для анализа последовательностях.
МЕМЕ ищет блоки и определяет из них мотивы, используя при этом определенные критерии. Важными являются величины LLR (log likelihood ratio) – они являются аналогами весам выравнивания в матрицах замен аминокислот, но создаются и действуют исключительно для одной позиции блока исходя из частот встречаемости аминокислот в нем.
E-value в данном случае есть вероятность нахождения в случайных последовательностях (такой же длины) блока с величиной LLR равной данной или большей.
LOGO (sequence logo) – графические изображения консервативности отдельных позиций для каждого найденного мотива – представлены на рисунках 1-3. Высота столбика показывает степень консервативности позиции, а доля высоты отдельных букв пропорциональна их количеству в этой позиции.
Рис. 1. LOGO для мотива 1.
Рис. 2. LOGO для мотива 2.
Рис. 3. LOGO для мотива 3.
Замечание. В начале данного раздела был описан сервис МЕМЕ-suite.
Сравнение блоков, найденных МЕМЕ, с полным выравниваним, выданным muscle
Было проведено выравнивание полноразмерных последовательностей, с использованием которых проводился поиск мотивов, с последовательностями самих мотивов, выданных MEME. Результаты можно увидеть на рисунках 4-6 (в полном размере – кликнув по изображениям), на них представлены выравнивания последовательности с каждым блоком по-отдельности (для наглядности).
Рис. 4. Выравнивание полноразмерных последовательностей с блоком мотива 1.
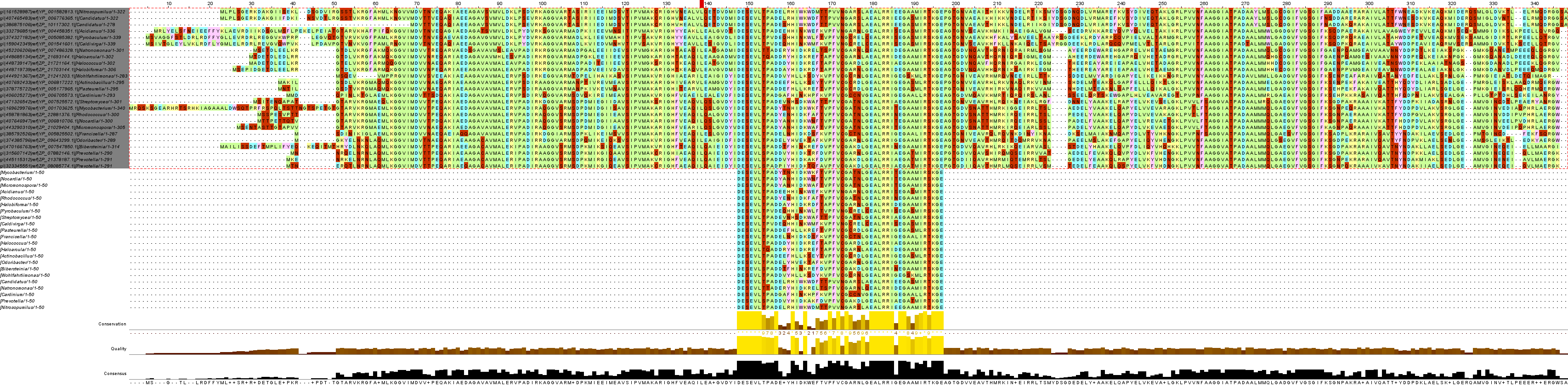
Рис. 5. Выравнивание полноразмерных последовательностей с блоком мотива 2.
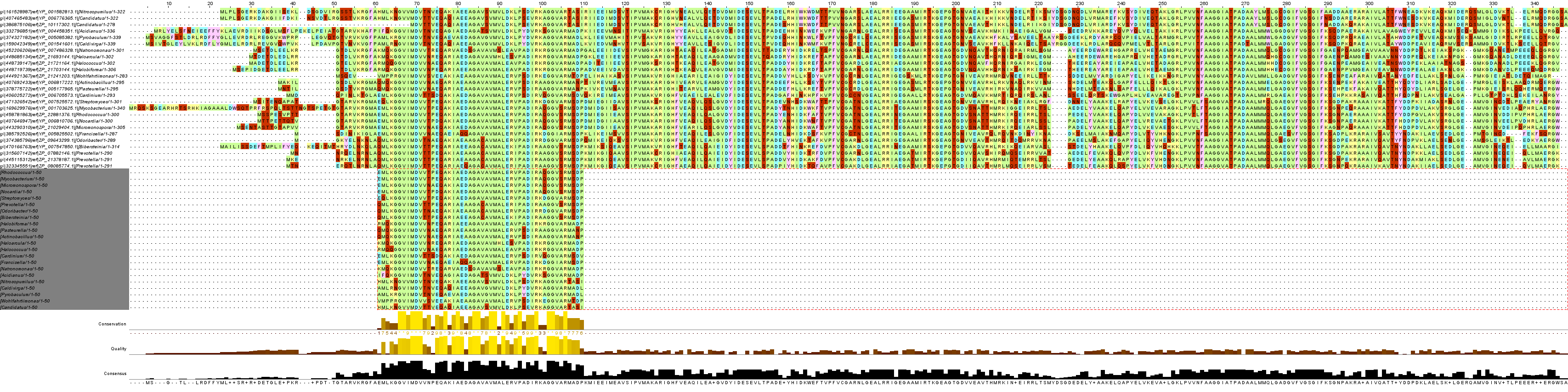
Рис. 6. Выравнивание полноразмерных последовательностей с блоком мотива 3.
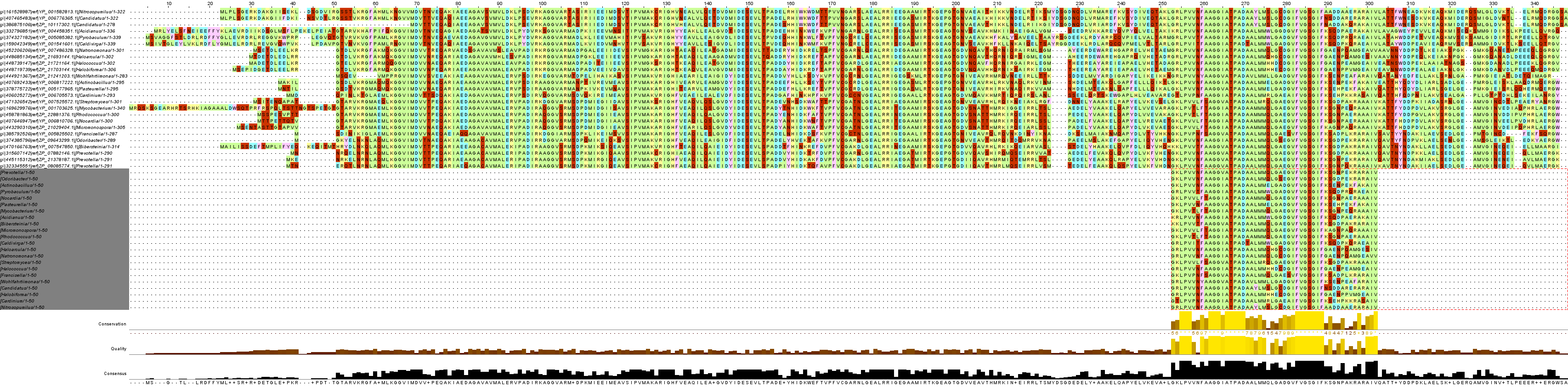
Выравнивание блоков, составленных из мотивов, полностью совпадают с выравниванием. Этому не мешает то, что в блоки попали не все последовательности.
Можно заключить, что выравнивание очень удачное, т.к. мотивы соответствуют полным последовательностям.
Поиск найденных мотивов в других последовательностях
С помощью программы MAST (Motif Alignment and Search Tool) был произведен поиск мотивов, найденных программой МЕМЕ, в последовательностях, из которых составлено выравнивание PF01680 домена PDXS_BACSU, взятого из Pfam (подробнее об этом в работе, посвященной доменной структуре изучаемого белка
Выполнение работы
1) Из выравнивания Pfam PF01680_seed.msf были извлечены последовательности программой degapseq с помощью команды:
2) Программа emast была запущена через консоль Linux с использованием txt-файла выдачи МЕМЕ:
3) Были проанализированы результаты с использованием выдачи mastout.html (см. ниже).
В seed.fasta (из Pfam) имелось 10 последовательностей. Некоторая информация о встречаемости обнаруженных мотивов среди этих последовательностей представлена ниже.
Первый и второй мотив были найдены в каждой последовательности входного файла, причем p-value (значение, обозначающее вероятность нахождения данного мотива в данной последовательности по случайным причинам) для выравниваний не превосходит 1.5е-38. Это означает, что выравнивания очень «удачные».
С другой стороны, ни в одной последовательности не был обнаружен третий мотив. Можно предположить, что это связано с тем, что этот мотив был вычленен из последовательностей близкородственных организмов и, в таком случае, был отброшен при работе Pfam. Тем не менее, возможны и другие причины.
Не все последовательности из выравнивания содержат хотя бы один мотив. Все 3 мотива содержат только 14 последовательностей. Таким образом, выравнивания фрагментов с мотивами не очень удачны, поскольку все три мотива встречаются в малом числе последовательностей, а некоторых даже не встречается ни один.
Анализ карты локального сходства белка TALe самого с собой
Представляется интересной карта локального сходства белка TALe с самим собой. Последовательность этого белка представлена в файле tale-seq.fasta
На рисунке 1 представлена карта локального сходства при стандартных параметрах работы сервиса DotHelix на сайте genebee. На рисунке 2 – она же при изменении верхней границы силы шума («power of noise») с 4 до 10, карта в таком виде слегка более ясна для впервые столкнувшегося с ней зрителя.
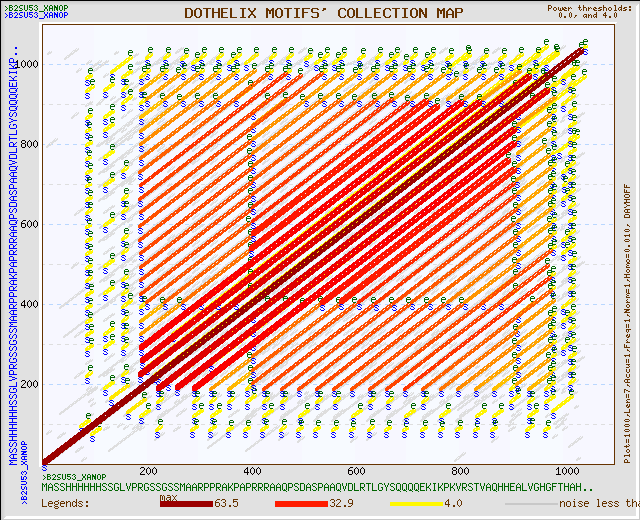
Рис. 1. Карта локального сходства при стандартных параметрах работы DotHelix.
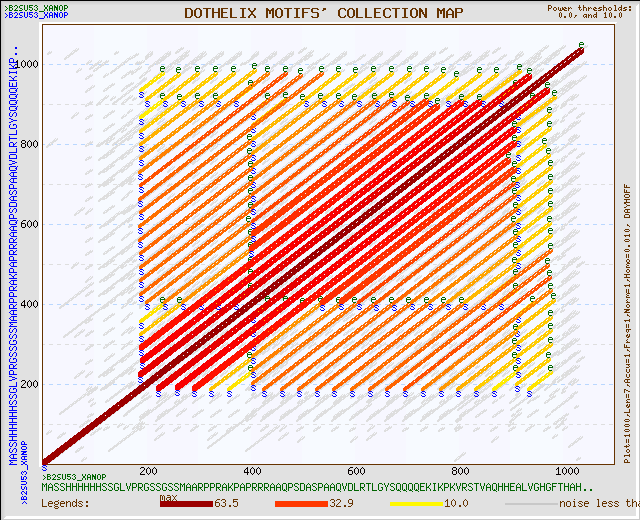
Рис. 2. Карта локального сходства при максимальном значении силы шума 10.
Карта симметрична относительно побочной диагонали, на которой находится сплошная линия, обозначающая, что последовательности, между которыми ищется локальное сходства, идентичны (это сам белок).
Очевидно, что другие линии на карте обозначают наличие неких повторяющихся частей последовательности. Причем необходимо отметить, что по карте заметно, что эти дублирующиеся кусочки располагаются с определенным периодом, т. к. расстояние между линиями одинаково.
Прямое исследование последовательности показывает, что один мотив встречается в белке 23 раза. Это подтверждается картой локального выравнивания (можно заметить, что линий на карте в самом деле 23). Отметим, что такие повторы возникают в районе 200-900 аминокислотных остатков.
Наличие некоторых других отметок (коротких линий на протяжении нескольких аминокислот) на карте с низким порогом максимальной силы шума обусловлено повторами на дистальных концах молекулы (до 200 и после 900 аминокислотных остатков).