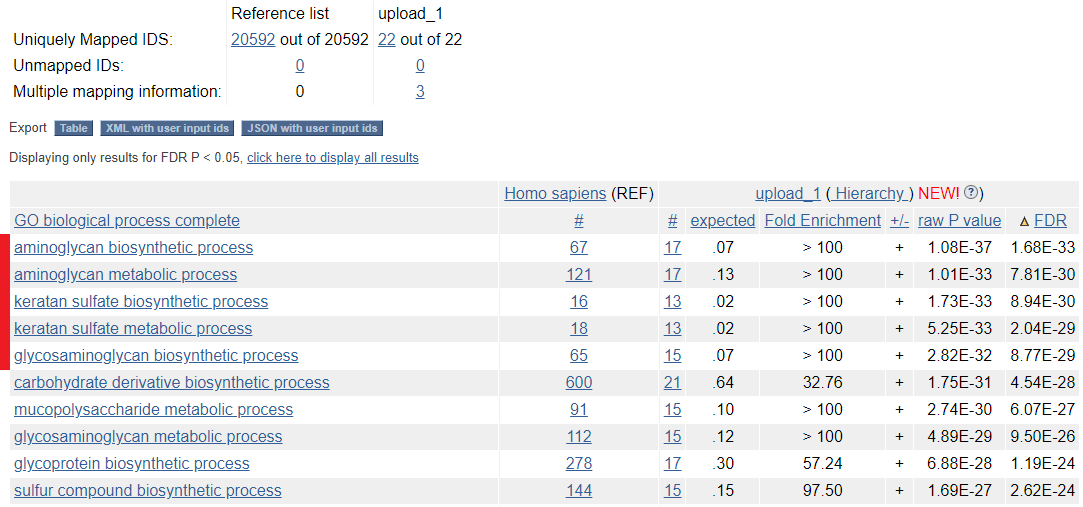
Полученный список генов я решил проанализировать с помощью базы данных GO. Анализ проводил с помощью сервиса GENE ONTOLOGY с опциями ''biological process'' и ''Homo sapiens''. После запуска меня перенаправило на сайт PANTHER и были использованы следующие настройки:
Analyzed List: upload_1 (Homo sapiens)
Reference List: Homo sapiens (all genes in database)
Annotation Data Set: GO biological process complete
Test Type: Fisher's Exact
Correction: Calculate False Discovery Rate
Все ID (22) прошли анализ обогощения. Далее я отсортировал выдачу по поправленному p-value так, чтобы наверху оказались самые значимые находки (нажав 2 раза на аннотацию FDR). Затем я взял 5 самых значимых GO terms (рис. 1). Им соответствуют следующие GO ID: GO:0006023, GO:0006022, GO:0018146, GO:0042339, GO:0006024.
Также ниже представлено описание каждой колонки в выдаче.
| Название колонки и номер | GO biological process complete (1) | # (2) | # (3) | expected (4) | Fold Enrichment (5) | +/- (6) | P value (7) |
| Описание | Название группы генов, вовлечённых в некий биологический процесс | Количество всех генов из референсного списка генов (все гены в выбранном организме), участвующих в данном процессе | Количество генов, участвующих в этой категории аннотации данных, из загруженного списка генов | Количество генов, которое можно было бы ожидать в рамках данной категории из загруженного списка. Считается на основе референсного набора генов | Отношение числа генов из списка, встретившихся в группе, к ожидаемому числу генов | Перепредставленность (+, Fold Enrichment > 1), недопредставленность (-, Fold Enrichment < 1) | P-value, определённое точным тестом Фишера (в моём случае) или биномиальным распределением (при выбранной другой опции) |
Далее я визуализировал их на графе (рис. 2) с помощью сервиса Gene Ontology and GO Annotations, вставив в графе Basket GO ID и нажав на значок весов.
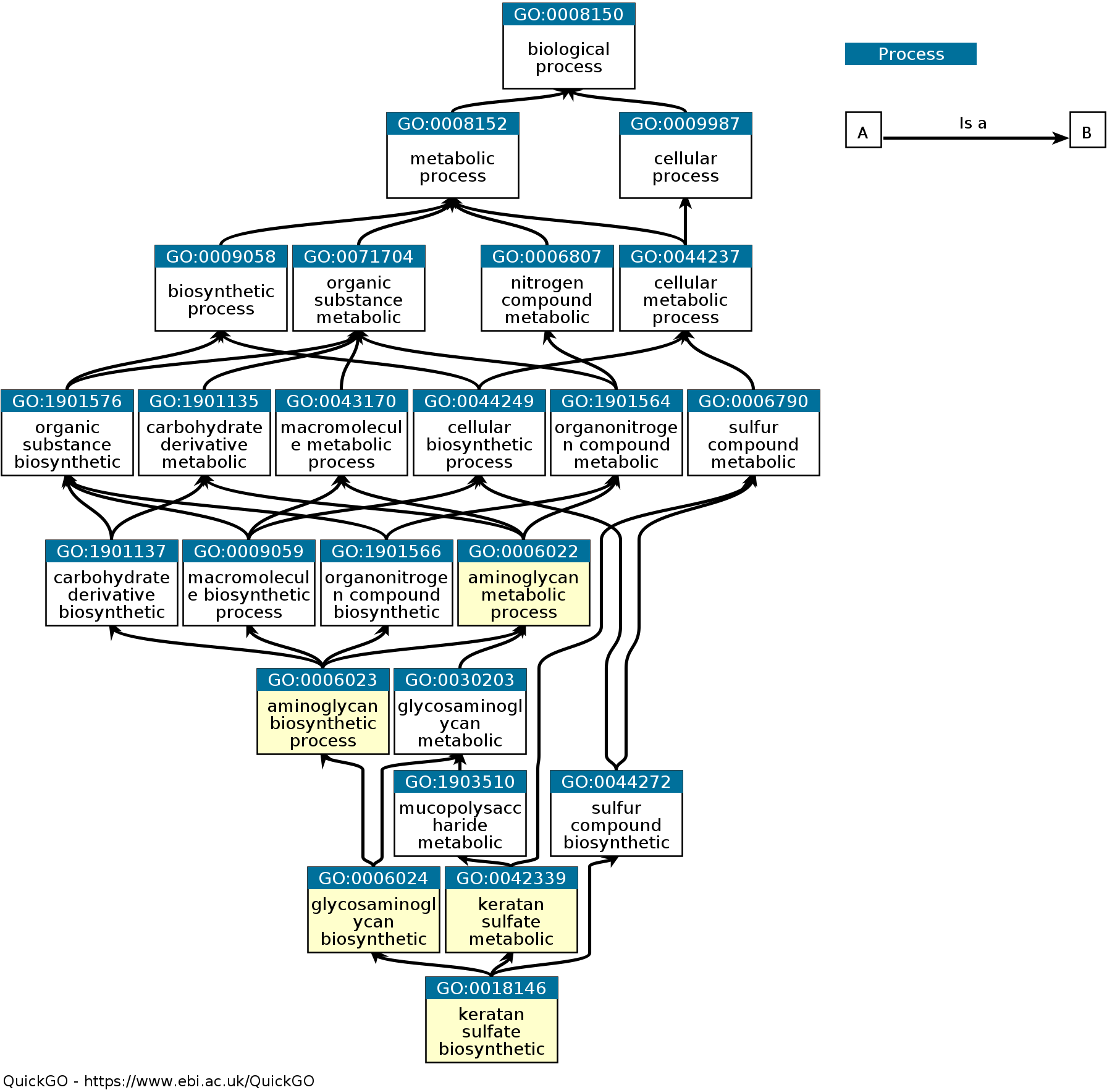
Все анализируемые GO terms являются процессами метаболизма макромолекул. Все ветви напрямую связаны друг с другом, между приведенными на рисунке узлами имеются только "is a" отношение, то есть узлы более высокого уровня в любом выбранном на графе пути кодируют процессы, обобщающие процессы, кодируемые узлами более низкого уровня. Процесс биосинтез кератансульфата является процессом одновременно биосинтезом гликозаминогликанов и процессом метаболизма кератансульфата. Процессом биосинтеза гликозаминогликанов является процесс биосинтеза аминогликанов. А процессы биосинтеза аминогликанов и метаболизма кератансульфата являются процессом метаболизма аминогликанов. Три выбранные GO категории представляют самые глубокие узлы графа (процессы биосинтеза кератансульфата и гликозаминогликанов и процесс метаболизма кератансульфата) и более точно описывают процессы частично характеризующие набор белков с данными ID, остальные две выбранные GO категории кодируют более общие процессы (биосинтез и метаболизма аминогликанов) и боллее обще описывают процессы всего набора белков с данными ID.