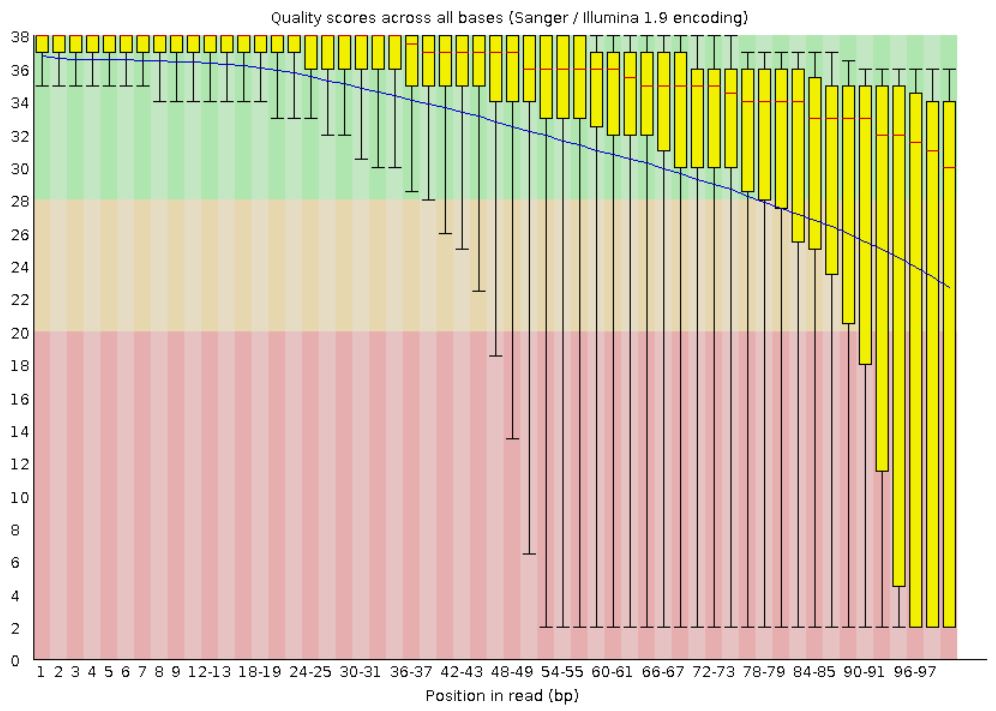
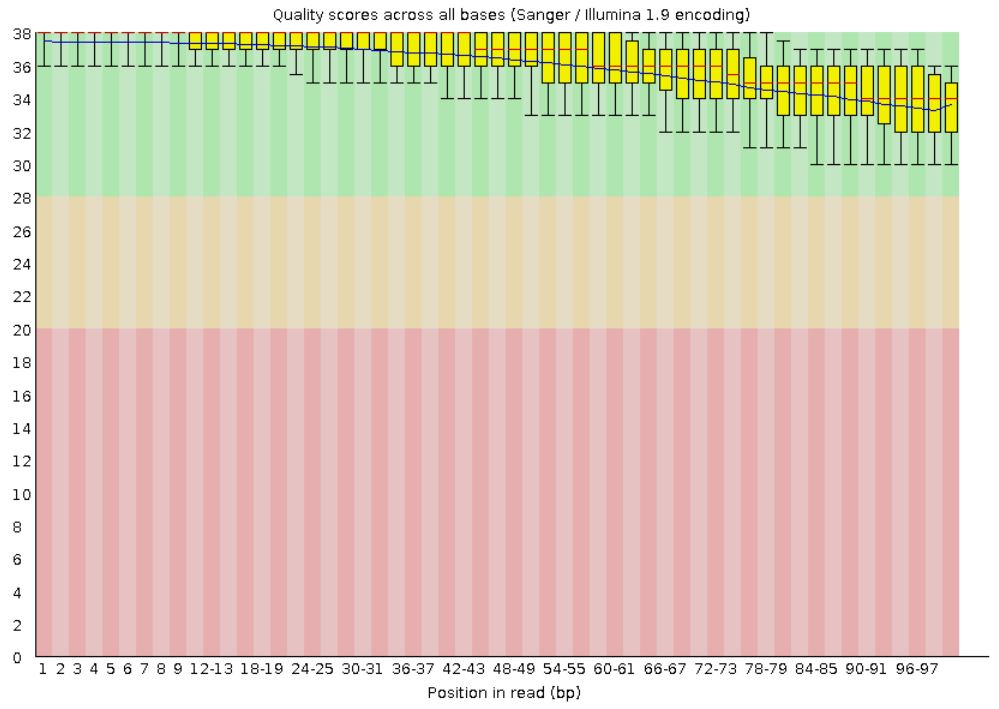
В данном практикуме было предложено поработать с транскриптомом резушки Arabidopsis thaliana. Для этого в рабочую директорию /nfs/srv/databases/ngs/s.kozyulina/G был скопирован архив
| Команда | Результат выполнения команды |
| gunzip G.fastq.gz | Разархивирует G.fastq.gz. Итог: в папке G получен и лежит файл G.fastq |
| seqret
Read and write (return) sequences Input (gapped) sequence(s): /P/y16/term3/block3/adapters/* output sequence(s) [prefixpe_1.fasta]: adapters.fasta |
Все адаптеры были собраны в единый файл adapters.fasta |
| java -jar /usr/share/java/trimmomatic.jar SE -phred33 G.fastq G_no_adapters.fastq ILLUMINACLIP:adapters.fasta:2:7:7 | Cоздан файл G_no_adapters.fastq с последовательностью без адаптеров.
Результат: Input Reads: 3869869 Surviving: 3869408 (99,99%) Dropped: 461 (0,01%) |
| java -jar /usr/share/java/trimmomatic.jar SE -phred33 G_no_adapters.fastq G_clean.fastq SLIDINGWINDOW:5:28 MINLEN:32 | Убирает плохие буквы с концов. Программа Trimmomatic проходит скользящим окном (SLIDINGWINDOW) длины 5 по каждому прочтению и убирает части ридов
после любого окна со средним качеством ниже 28. При этом удаляет прочтения, которые после очистки оказались короче 32 букв - считаем, что они доверия
не заслуживают.
Результат: Input Reads: 3869408 Surviving: 3420217 (88,39%) Dropped: 449191 (11,61%). |
Число прочтений до Trimmomatic - 3869408, размер файла - 979 М
Число прочтений после Trimmomatic - 3420217, размер файла - 797 М
| |
|
Подготовка 31-меров (множества всех возможных последовательностей рида длины 31) проводилась с помощью программы velveth (подпрограммы программы velvet). Velveth выдаёт файлы Sequences (с самими последовательностями) и Roadmaps (с информацией об этих последовательностях). Эти файлы необходимы для дальнейшей работы velvetg.
Команда: velveth velveth 31 -fastq -short G_clean.fastq
Выдача: директория velveth с файлами Log, Sequences и Roadmaps
Приступаем к velvetg - одной из программ, реализующих сборку генома методом граф де Брайна. Velvetg создает файлы contigs.fa (с последовательностях всех собранных контигов) и stats.txt (c информацией о контигах, стоящих в вершинах графа)
Команда: velvetg velveth
Выдача: "Final graph has 446888 nodes and n50 of 28, max 606, total 6826334, using 0/3420217 reads", в директории velveth созданы файлы
Graph, LastGraph, PreGraph, contigs.fa, stats.txt.
Можем анализировать полученную информацию.
N50 = 28, количество вершин = 446888
| Длина | short1_cov | short1_Ocov |
| Самые длинные контиги (1 строка - NODE_325832) | ||
| 606 | 14.40429 | 14.136964 |
| 590 | 3.523729 | 3.523729 |
| 589 | 2.597623 | 2.597623 |
| Контиг с максимальным покрытием (NODE_189196) | ||
| 1 | 4662508 | 4662508 |
| Контиг с минимальным покрытием (NODE_326415) | ||
| 43 | 1 | 1 |
| Средние значения | ||
| 15.27527 | 259.1113 | 166.4185 |
| Контиг | Банковская аннотация лучшей находки | Покрытие контига | Процент идентичности |
| NODE_325832 | Accesion - NM_123430.2 Arabidopsis thaliana succinate dehydrogenase 2-2 (SDH2-2), mRNA |
100% | 100% |
| NODE_189196 | Accesion - NM_001332684.1 Arabidopsis thaliana Late embryogenesis abundant (LEA) hydroxyproline-rich glycoprotein family mRNA |
100% | 100% |
| NODE_326415 | Accesion - NM_121381.4 Arabidopsis thaliana Acyl-CoA N-acyltransferases (NAT) superfamily protein mRNA |
75% | 98% |