Предсказание генов эукариот
1. Описание скэффолда

Рис. 1. Созревающий V. vinifera1 |
В первом задании я буду описывать скэффолд
NW_003724208. Он принадлежит
Винограду культурному. Систематика:
Домен: Eukaryota
Царство: Viridiplantae
Тип: Embryophyta
Отдел: Magnoliophyta
Класс: Magnoliopsida
Порядок: Vitales
Семейство: Vitaceae
Род: Vitis
Вид: V. vinifera
V. vinifera — культурный вид винограда. Плоды не только употребляются в пищу
в свежем виде, но и используются для приготовления вина сока, уксуса. Виноград культурный
растёт в умеренных и субтропических регионах, широко культивируется во многих странах. В
диком виде виноград культурный неизвестен. Современный культурный виноград отличается от всех
диких подавляющим преобладанием обоеполых цветков, является ветроопыляемым, насекомоопыляемым
и самоопыляющимся растением. Сорт винограда характеризует отличительную совокупность
передаваемых по наследству морфологических, биологических и хозяйственных признаков.
Редактировать какие-то признаки существующего сорта можно путем генных модификаций.
V.
vitifera — это диплоидное растение с 38 (2n) хромосомами. Небольшой геном организма
имеет размер около 500 Мб. Всего было три проекта по секвенированию генома этого организма,
результаты были предоставлены EMBL (сборка
GCA_000003745.2)
1,2.
Немного информации о скэффолде
NW_003724208:
- длина: 324868 п.н.;
- число генов и CDS: 40;
- число некодирующих РНК (ncRNA): 3;
- файл с последовательностью: vitis.fasta
Для этого соответствующая запись была найдена в БД Nucleotide и
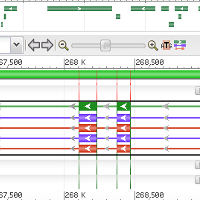
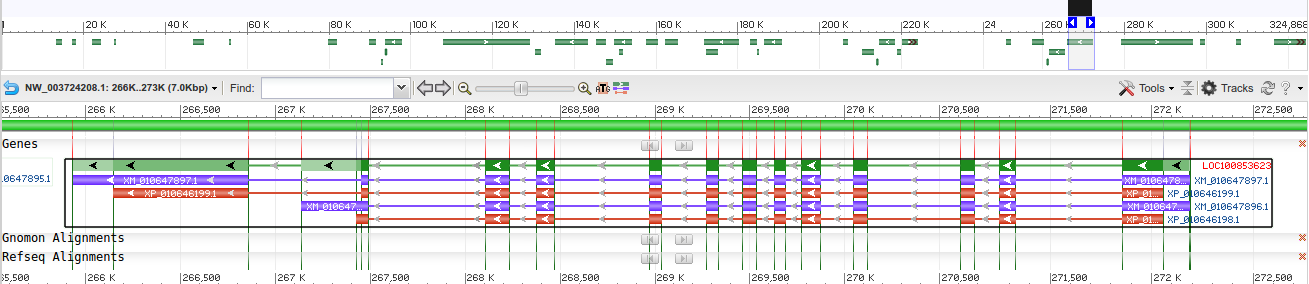
открыта в геномном браузере. Далее вручную был найден ген, для которого по данным базы данных
предсказывается альтернативный сплайсинг (рис. 2). В качестве продуктов трансляции мРНК
предсказаны 2 изоформы фумарилацетоацетат-гидролазы (ФАА гидролазы).
Ссылки на записи для вариантов мРНК и соответствующих изоформ на сайте NCBI:
- мРНК:
XM_010647896.2, изоформа X1: XP_010646198.1
- мРНК:
XM_010647897, изоформа X2: XP_010646199.1
На рис. 3 и 4 показаны домены упомянутых изоформ.
 Рис. 3. Изоформа X1 Рис. 3. Изоформа X1 |
 Рис. 4. Изоформа Х2 Рис. 4. Изоформа Х2 |
Таким образом, в состав изоформы Х2 помимо ФАА-гидролазы и N-концевой ФАА-гидролазы входит
еще и BAG-домен. Что же это за домены?
ФАА гидролаза— фермент, гидролизующий фумарилацетоацетат с образованием фумарата
и ацетоацетата (в ходе катаболизма тирозина). Мутации, вызывающие дефект в ферменте, приводят
к накоплению катаболитов тирозина. У людей, например, мутации в ФАА-гидролазе
вызывают тирозинемию, приводящую к повреждению почек, печени, периферических нервов и т.д.
N-концевая ФАА-гидролаза — домен, имеющий неохарактеризованную функцию. Имеет
конформацию бочонка, как у SH3-домена.
BAG-домен — домен-регулятор активности шаперона Hsp70, предотвращающего
мисфолдинг белков и и их дальнейшую агрегацию, стимулируя рефолдинг денатурированных
белков
3. Bag1, к примеру, образует с Hsp70 комплекс и ингибирует рефолдинг
белков
4.
Мне непонятно, зачем BAG-домен входит в состав изоформы Х2. blastp не нашел похожих белков, в
состав которых тоже входил бы этот домен (нашлись только гомологи изоформы Х1). Возможно, это
какая-то ошибка машинного анализа.
UPD: 26.11 NCBI изменил запись обсуждаемого скэффолда, убрав тот самый транскрипт, в
продукте которого содержался BAG-домен. Теперь ссылка на него, приведенная выше, не работает.
В геномном браузере участок, приведенный на рис.2, выглядит следующим образом:
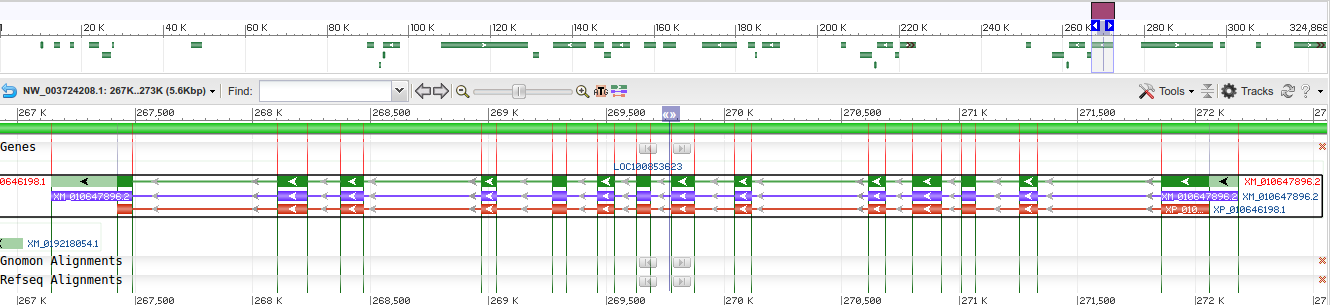 Рис. 5. Участок после изменения аннотации Рис. 5. Участок после изменения аннотации
|
Единственное возможное объяснение такой внезапно смены аннотации после того, как я сделала
задание, — NCBI следит за моим сайтом. Что ж, оставим это на их совести.
2. Предсказание генов и белок-кодирующих областей в выданном скэффолде
Для выполнения задания использовался web-сервер
AUGUSTUS (режим Prediction). Входные параметры:
AUGUSTUS parameter project identifier: arabidopsis
Genome file: vitis.fasta
User set UTR prediction: true
Report genes on: both strands
Alternative transcripts: few
Allowed gene structure: predict any number of (possibly partial) genes
Ignore conflictes with other strand: false
Для параметров модели был выбран организм
Arabidopsis thaliana (Резуховидка Таля),
т.к. согласно современной системе классификации цветковых растений
APG III порядок
Brassicales, которому принадлежит этот вид, ближе всех из предложенных
в
AUGUSTUS к порядку Vitales, к которому принадлежит наш виноград (см. рис.5).
Также в параметрах я установила предсказание UTR, т.к. судя по
GenBank они есть.
Еще было отмечено наличие нескольких альтернативных транскриптов, которые тоже есть в
записи (мы рассматривали один из примеров в п.1.). Все остальные параметры совпадают с
параметрами по умолчанию. В таблице 1 приведено описание полученных файлов.

Рис. 5. Положение
выбранных порядков (выделены) |
Табл. 1. Описание полученных файлов
| Файл |
Описание содержимого |
| predictions.tar.gz |
Архив со всеми файлами, выданными программой |
| augustus.gff |
Предсказания генов в формате .gff |
| augustus.gtf |
Предсказания генов в формате .gtf |
| augustus.aa |
Последовательности трансляций предсказанных генов в формате .fasta |
| augustus.cdsexons |
Предсказанные экзоны в формате .fasta |
| augustus.codingseq |
Предсказанные CDS в формате .fasta |
| augustus.gbrowse |
Координаты найденных генов, мРНК и т.д. для геномного браузера |
| augustus.mrna |
Предсказанные мРНК (с UTR) в формате .fasta |
Так как сравнивать целиком гены в двух файлах проблематично, я сравнивала
экзоны (вернее, все найденные CDS), полученные из обоих файлов
.gff.
Для того, чтобы сверить найденные CDS, был написан скрипт
pr12.py.
Затем с помощью команды (входные файлы:
vitis.gff3,
augustus.gff):
python pr12.py vitis.gff3 augustus.gff results.out
был получен файл
results.out, содержащий координаты CDS,
одинаковых в обоих файлах, а также общую статистику.
Прим. Некоторые координаты в выходном файле повторяются дважды. Это связано с
предсказанием двух транскриптов, а, следовательно, CDS для них повторяются дважды. В
записи
GenBank такое тоже встречается. В качестве примера может служить обсуждаемый
в п.1 ген фумарилацетоацетазы.
Таким образом, из 263 CDS, найденных
AUGUSTUS, только 149 (84,65% от CDS в записи)
совпадают с аннотированными в
GenBank. Не найдено было 27 (15,34%) CDS, так что в
принципе я бы сказала, что процент предсказанных так же, как в записи
GenBank
кодирующих последовательностей довольно высок. Однако помимо 149 верно найденных CDS,
web-сервер нашел 114 (!), не аннотированных в
GenBank. Так что несмотря на
хороший процент верно найденных CDS, число неверно найденных слишком велико, чтобы
говорить о высокой точности алгоритма. Возможно, выбор более близкого организма для
параметров модели улучшил бы ситуацию.
Что касается обсуждаемого в п. 1 гена,
AUGUSTUS тоже, как ни странно, предсказал 2
транскрипта (см. g.45). Однако С-конец был предсказан по-другому: последний экзон имеет
координаты 268231..268106, в то время как в аннотации есть еще экзон 267452..267488 для
транскрипта Х1 и + 266146..266855 для транскрипта Х2 (здесь говоря об экзонах имеются в виду
и соответствующие участки CDS). Таким образом, частично веб-сервер смог предсказать
обсуждаемый ген и даже сделал ту же ошибку, предсказав два трансрипта.