Секвенирование по Сэнгеру
В данном практикуме я буду расшифровывать результаты секвенироваения, полученные на выходе из капиллярного секвенатора.
Ссылка на файл с прямой последовательностью
Ссылка на файл с обратной последовательностью
Для анализа хроматограмм я использовала программу GeneStudio. Я загрузите в неё прямую и обратную последовательности. Обратная последовательность была автоматически преобразовано в себе комплементарную и выравняна с прямой.
Характеристика хроматограммы в целом
Границы начального и конечного трудно читаемых участков в каждой последовательности приведены в таблице (они определены по позиции в выравнивании)
| 5' | 3' | |
| Прямая последовательность | 1-33 (1-19) | 697-924 (702-924) | Oбратная последовательность | 1-33 (1-13) | 952-948 (806-948) |
Без скобок я записала трудно читаемые участки, которые выдала программа, в скобках указаны значения для некачественных участков с моей точки зрения. То есть прогрмма более кретично оценивает хроматограмму.
В целом, качество хроматограммы можно определить на глаз. Интересно отметить, что обратная последовательность выполнена более точно: шумы едва различимы и редко встречаются.Однако в прямой последовательности пики от шумов составляют примерно 1/4 высоты сигнальных пиков и имеются на протяжении всей хроматограммы. Силы сигнала и шума неравномерны вдоль последовательности: сила сигнала уменьшяется на начальном и конечном этапе прочтения, в то время как сила шума возрастает на тех же участках.
Как было сказано ранее для выполнения практикума я пользовалась программой GeneStudio. В связи с этим хотелось бы отметить ее преимущества и недостатки.
+ |
- |
| Функционал программы позволяет выравнивать последовательности, соответсвтенно появляется возможность сравнивать сразу два результата, быстро приходить к консенсусу(очень удобно визуально оценивать результат) | На концах выравнивания появляются участки, для которых нуклеотидная последовательность представлена буквенно, но хроматограмма для них отсутствует | Kонсенсус и исправленные нуклеотидные последовательности обеих цепей можно экспортировать в формат fasta | При замене нуклеотида в одной из последовательностей автоматически происходит замена в консенсусе(Например, A меняется на a, хотя по сути в консенсусе-то было все правильно) |
| Программа с высокой точностью определила консенсусную последовательность | По необъяснимым для меня причинам, программа для одних и тех же файлов прямой и обратной последовательности(если запускать её несколько раз) предоставляет разные хроматограммы на концах выравнивания, это несильно сказывается на консенсусе, просто очень странно |
Выравнивание прямой и обратной последовательностей в формате fasta.
Хотелось бы сказать несколько слов о том, как я получила данное выравнивание в нужном формате:
После того как прогрммой GeneStudio было собрано выравнивание, я начала просматривать прямую последовательность в поисках сложных мест (примеры таких случаев приведены ниже). Решение по проблемным нуклеотидам принималось с помощью последовательносьти второй цепи. Все проблемные нуклеотиды исправлялись маленькими буквами. То же самое было проделано с обратной последовательностью. Результат преобразований был экспортированы в формат fasta.
Консенсусная последовательностью в формате fasta.
В целом консенсусная последовательность, изначально созданная программой после выравнивания, была довольно точной, я несильно её исправляла. Только на концах выравнивания остались неизвестные нуклеотиды (буквы N).
Обоснование решений для проблемных нуклеотидов или полиморфизмов.
Я постаралась найти в своём выравнивании все типичные сложные места
Редактирование состояло исключительно в замене букв, удалять или вставлять буквы воозможности не представилось.
Неопределённость 1, 2
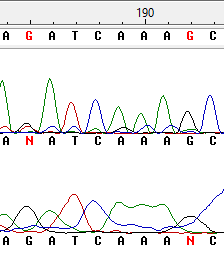
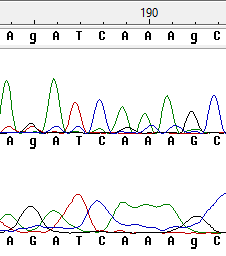
Здесь в первом случае в прямой последовательности шум выглядит почти как сигнал, данная неопределённость моментально разрешается благодаря наличию обратной цепи. Во втором случае в обратной последовательности сигнал от буквы C находится слишком близко к пику G, поэтому программе приходится помогать с выбором буквы.
Неопределённость 3,4
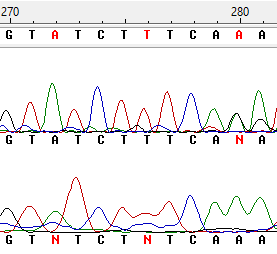
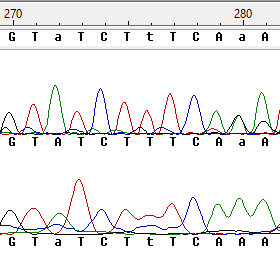
Видно, что в позиции 272 и 280 встречаются проблемы, которые уже были разобраны в пункте 1,2. Зато нуклеотид 276 вызывает интерес, это тот случай, когда одна и та же буква встречается несколько раз подряд, вместо 3ёх пиков в обратной цепи - 2 широких, возникает проблемный нуклеотид, заменяю N на t.
Неопределённость 5
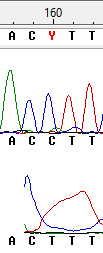
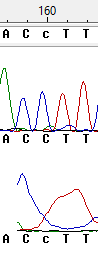
В данном случае в 160 позиции программа выдаёт полиморфизм (нуклеотид, про который было решено, что в секвенируемой ДНК встречаются два (или более) варианта). Однако, я считаю, что полиморфизма здесь нет, а тимин появляется в нижней последовательности из-за того, что далее встрчаются сразу 2 тимина, пик от которых смазан.
Пример нечитаемого фрагмента хроматограммы
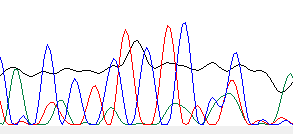
Хроматограмма нечитаема. Непонятно, как отличить сигнал от размытой краски, поэтому нуклеотиды распознать невозможно.