Сигнальные последовательности
Что было сделано:
- был скачан геном вируса Human coronavirus 229E
- была составлена таблица с координатами upstream областями перед геном полипротеина (orf1ab) и перед каждым поздним геном.
- был создан fasta-файл с upstream областями
- был проведен поиск СS в upstream областях с помощью сервиса MEME
Поиск upstream областей
У вируса Human coronavirus 229E семь генов в геноме: один кодирует полипротеин, остальные - поздние.
Они кодируют поверхностный гликопротеин, белки 4a и 4b, белок клеточной оболочки, мембранный белок и нуклеокапсидный белок.
Составили таблицу с координатами upsteam: для orf1ab - от 1 до -1 нуклеотида относительно старта
трансляции, а для поздних генов - от -101 до -1(для начала). Координаты я смотрела в аннотированной последовательности
генома вируса в формате .gb (также координаты открытых рамок можно было посмотреть с помощью программ
поиска ORF, например, UGENE).
Далее был создан fasta-файл с upstream областями с
помощью команды seqret пакета EMBOSS.
Работа с сервисом MEME
Для того, чтобы начать поиск мотива, понадобилось открыть сервис MEME Suit, открыть Motif discovery => MEME и ввести параметры:
- Select the site distribution: Zero or One Occurence Per Sequence (zoops)
- Select the number of motifs: 3
- How wide can motifs be? 6
- Can motif sites be on both strands? search given strand only
- What should be used as the background model? 0-order model of sequences
- How many sites must each motif have? Minimum sites: 2
Результаты были получены в виде html-страницы c диаграммами LOGO и в текстовом формате. Были получены три мотива длиной 49-50 нуклеотидов. Результат меня не очень порадовал: хоть мотивы были с хорошим E-value и среди мотивов были консервативные последовательности по пять нуклеотидов подряд, они не соответствовали СS, приведенной в статье.


Так что решено было попробовать еще раз. На этот раз максимальная длина мотива была ограничена до 20, а
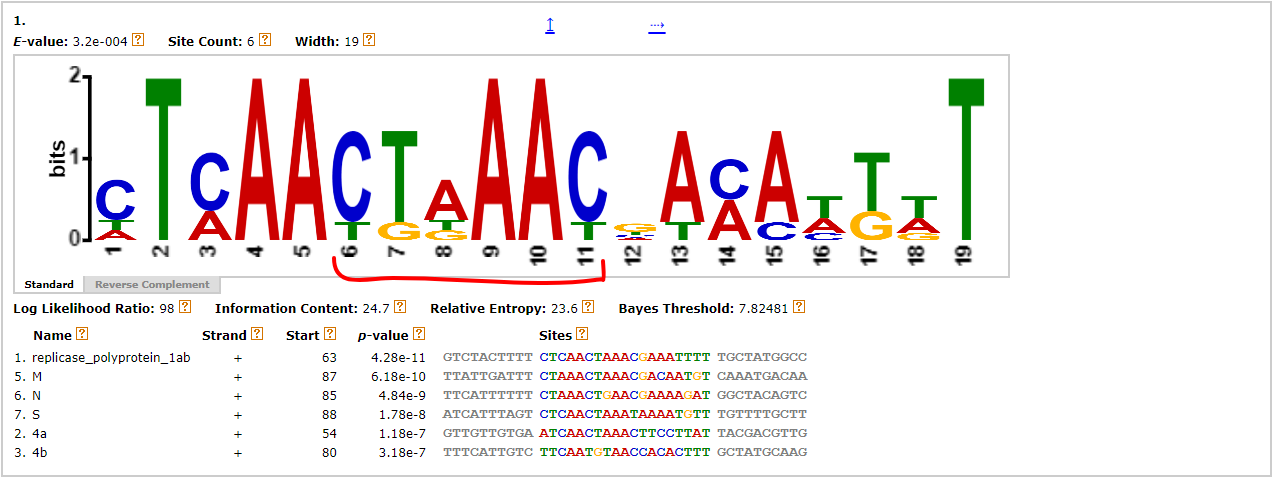
сами последовательности продлены на 30 нуклеотидов с 3'-конца, на всякий случай. Нашелся мотив, в котором есть 6 из 6 совпадений
с CS, приведенной в статье. Можно сказать, что нашелся TRS-L и TRS-B для пяти из шести поздних генов. На
схеме расположения мотивов в последовательностях этот мотив обозначен красным.
Кстати, добавлять по 30 нуклеотидов с 3'-конца каждой последовательности было не обязательно, на результат
это не повлияло.
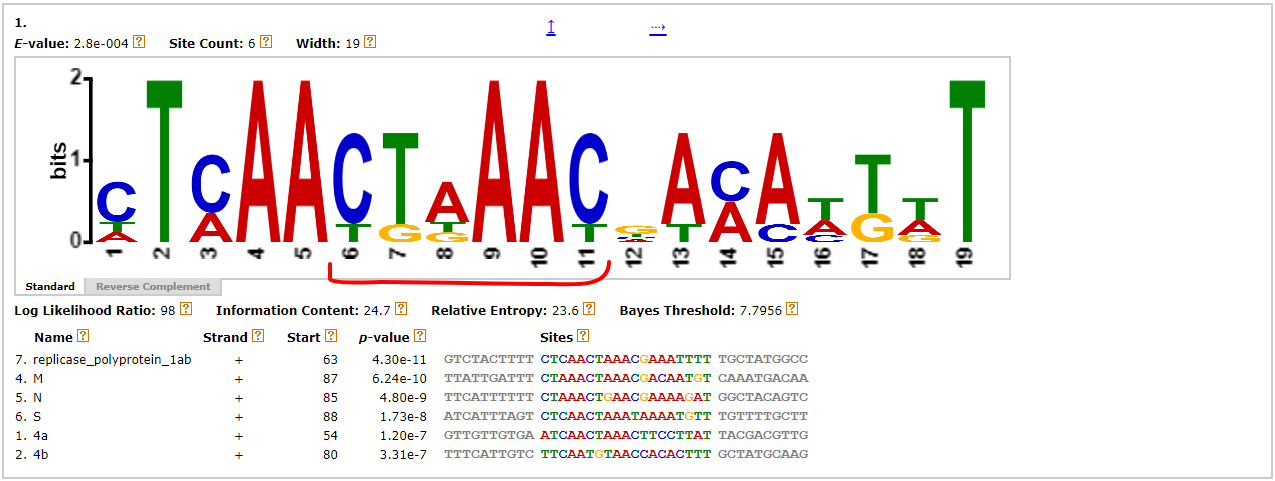
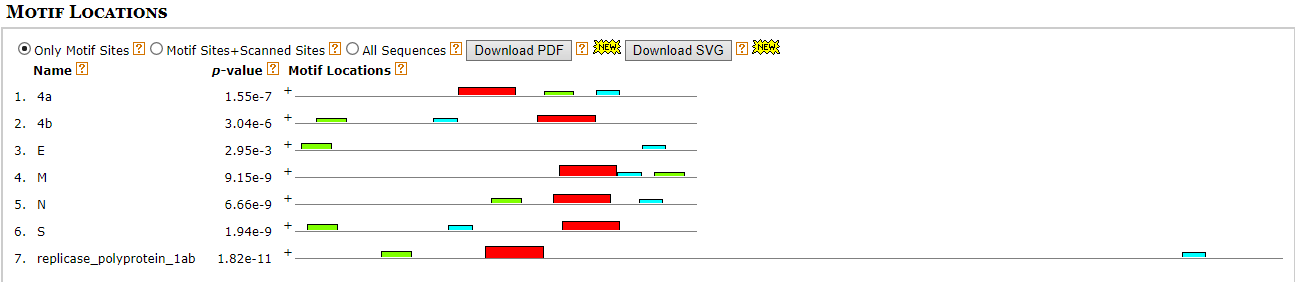
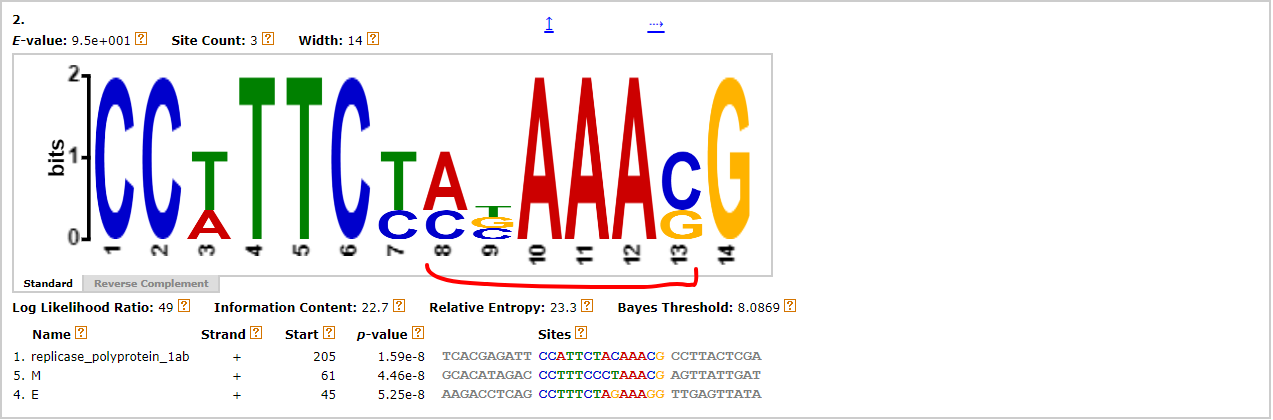
Но этого показалось мало, потому что для последовательности гена Е не оказалось нужного мотива. Возможно, он расположен чуть подальше с 5' конца от ORF, поэтому для этой последовательности я добавила еще 50 нуклеотидов с 5'-конца. Какой-то похожий на CS из статьи мотив для гена Е нашелся. (Е - ген, кодирующий белок оболочки). На схеме расположения мотивов этот мотив обозначен голубым. Для всех остальных последовательностей остался тот же мотив, что и был найден со второй попытки, обозначен красным.

Примечания:
Нажмитездесь,чтобы скачать таблицу PWM для M.musculus.
Файл с геномом выбранного мною вируса можно скачать здесь.
Ссылка на статью

