Трансляция любого белка в клетке начинается на свободных рибосомах, слоняющихся по цитоплазме. Однако далнейшая судьба разных белков неодинакова: часть из них должна остаться в цитоплазме, а часть - попасть в другие компартменты клетки или же за её пределы (секретируемые белки, например, антитела). Белки, пунк назначения которых - эндоплазматический ретикулум, аппарат Гольджи, лизосомы или внеклеточная среда, транслируются внутрь эндоплазматического ретикулума на сидячих рибосомах. Чтобы попасть туда до окончания трансляции, белку нужно быть узнанным SRP-частицей (мультисубъединичный белковый комплекс, включающий молекулу специальной РНК), которая как раз и отвечает за транспорт рибосомы в комплексе с мРНК и синтезируемой пептидной цепью к ЭПР. Логично, что пептидный сигнал (лидерный пептид) таких белков расположен на N-конце, так как этот конец первым выходит из рибосомы. Его узнаёт часть SRP-частицы, в то время как другая её часть связывается с рибосомой и временно блокирует трансляцию. В таком состоянии весь комплекс дрейфует к ЭПР, где садится на белок-транслокатор, SRP-частица диссоциирует, и трансляция продолжается. Ниже на рис.1 гифка, наглядно демонстрирующая весь процесс (будьте терпеливы и SRP-частица обязательно придёт!).
Сразу хочу оговориться, что для построения матриц и формирования выборок далее я пользовался адаптированным кодом, написанным Петром Милейко. Вот он. В результате его работы я получил 3 файла: первый, второй и третий, в которых лежат соответствеено 1) 100 последовательностей вида |7 нуклеотидов + инициаторный ATG + 3 нуклеотида| для построения PWM, 2) 300 последовательностей такого же вида в качестве тестовой выборки и 3) 300 последовательностей вида |7 нуклеотидов + неинициаторный ATG + 3 нуклеотида| в качестве отрицательного контроля.
Затем была построена PWM (исходим из GC содержания в геноме человека 41%), которую можно увидеть в таблице 1.
| 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 | 13 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| A | -0.389 | -0.34 | -0.551 | -0.206 | 0.304 | -0.126 | -0.126 | 1.218 | -5.691 | -5.691 | -0.389 | 0.112 | -0.819 |
| C | 0.643 | 0.115 | 0.535 | 0.668 | -0.187 | 0.617 | 0.717 | -5.327 | -5.327 | -5.327 | 0.198 | 0.59 | 0.347 |
| G | 0.115 | 0.476 | 0.414 | -0.025 | 0.59 | -0.312 | 0.115 | -5.327 | -5.327 | 1.582 | 0.808 | -0.187 | 0.741 |
| T | -0.494 | -0.249 | -0.551 | -0.612 | -1.593 | -0.34 | -1.187 | -5.691 | 1.218 | -5.691 | -1.187 | -0.819 | -0.676 |
Чтобы выбрать порог, по которому выбирать, найден сигнал или нет, я воспользовался гистограммой на рис.2, изображающей распределение весов последовательностей для трёх выборок (обучающая, тестовая, отрицательный контроль).
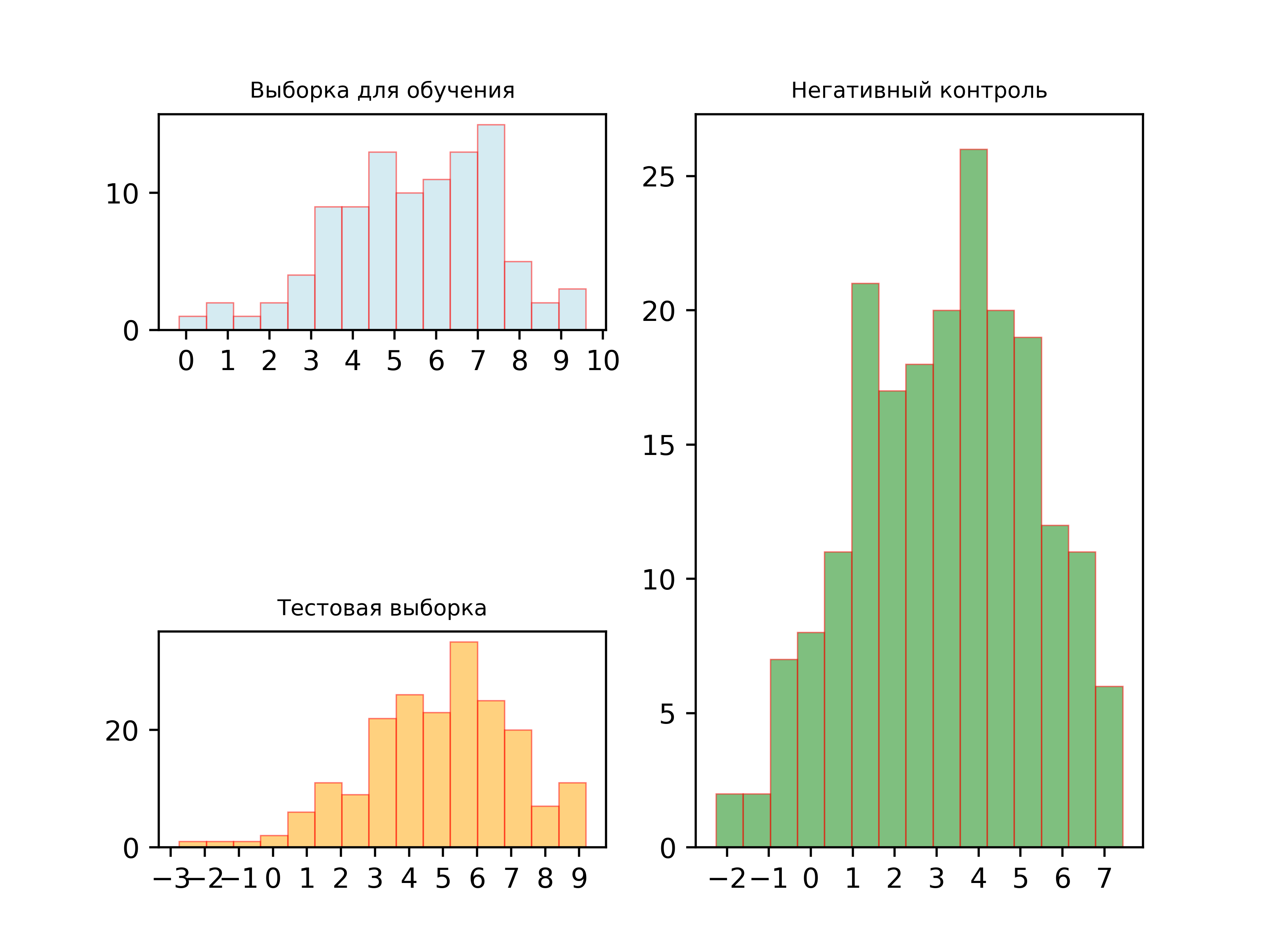
В качестве порога я выбрал число 5 и построил таблицу 2, в которой для каждой из трёх выборок дано количество последовательностей, перешедших порог и не перешедших его:
| выборка |
всего последовательностей |
перешедших порог | ниже порога |
|---|---|---|---|
| обучающая | 100 | 60 | 40 |
| тестовая | 200 |
107 | 93 |
| отрицательный контроль | 200 | 45 | 155 |
С помощью того же кода была сгенерирована таблица 3, содержащая информационное содержание для каждой позиции и каждого нуклеотида:
| 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 | 13 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| A | -0.112 | -0.103 | -0.135 | -0.071 | 0.176 | -0.047 | -0.047 | 1.761 | 0.0 | 0.0 | -0.112 | 0.053 | -0.154 |
| C | 0.362 | 0.038 | 0.27 | 0.386 | -0.046 | 0.338 | 0.435 | 0.0 | 0.0 | 0.0 | 0.072 | 0.315 | 0.145 |
| G | 0.038 | 0.227 | 0.185 | -0.007 | 0.315 | -0.068 | 0.038 | 0.0 | 0.0 | 2.286 | 0.536 | -0.046 | 0.46 |
| T | -0.128 | -0.083 | -0.135 | -0.141 | -0.138 | -0.103 | -0.154 | 0.0 | 1.761 | 0.0 | -0.154 | -0.154 | -0.146 |
С помощью ресурса WebLogo3 на основе обучающей выборки был создан рисунок 3, на котором видны "важные" позиции сигнала:
Чтобы обойти проблемы с перекрыванием сайтов, я сделал так: предположил, что вероятность встретить искомый сайт не зависит от остатка деления номера начала сайта на 6 и разбил геном на слова по 6 букв, идущие друг за другом, но не перекрывающиеся (n штук). Посчитал вероятность встречи сайта как произведение частот букв по геному. Провёл биномиальный тест из модуля scipy.stats (ожидаемое = np, получилось равным 223, реальное - 127). Получил p-значение, примерно равное 3.6е-12, что говорит о значимости различий. всё сделано с помощью собственного скрипта.
Janda, C., Li, J., Oubridge, C. et al. Recognition of a signal peptide by the signal recognition particle. Nature 465, 507–510 (2010). https://doi.org/10.1038/nature08870
von Heijne G. The signal peptide //The Journal of membrane biology. – 1990. – Т. 115. – С. 195-201.
{kind=link}