
|
|
|
|
Упражнения
Файлы taskX.[X] - результирующие файлы. 4) transeq - нуклеотидные последовательности из файла coding1.fasta транслируются по указанной таблице(стандартной), полученные аминокислотные последовательности пишутся в файл task4.fasta: transeq -table 1 coding1.fasta task4.fasta 5) transeq - нуклеотидная последовательность из файла cp000837.fasta транслируется в шести рамках: transeq -frame 6 cp000837.fasta task5.fasta 6) seqret - выравнивание переводится из формата fasta в формат msf: seqret align_07.fasta aln::task6.msf 7) infalign - в стандартный поток вывода подается число совпадающих букв между второй и остальными последовательностями(с именами, -only нужно для того, чтобы показать только выбранную информацию): infoalign -refseq 2 -only -name -idcount align_07.fasta stdout 8) featcopy - запись переводится из формата .gb в табличный .gff: featcopy streptococcus_gz1.gb task8.gff 10) shuffle - перемешивается последовательность нуклеотидов(-o - это запись в файл): shuffle -o task10.fasta AAC74885.2.fasta 11) cusp - подсчитываются частоты кодонов в данных последовательностях: cusp strept.fasta task11.txt 12) compseq - первый скрипт выдает реальные частоты нуклеотидов в последовательности, второй - ожидаемые: compseq strept.fasta task12_1.txt compseq -calcfreq strept.fasta task12_2.txt 13) tranalign - кодирующие последовательности выравниваются соответственно выравниванию их продуктов: tranalign gene_sequences.fasta protein_alignment.fasta task13.fasta  Получение списка трансляций открытых рамок Для обработки я взяла свою бактерию из первого семестра - Sorangium cellulosum So ce 56. Для нее имеется сборка полного генома, AC - AM746676. Чтобы получить таблицу трансляций открытых рамок, я использовала программму getorf: getorf -table 11 -minsize 180 -find 0 -circular sequence.fasta translations.fasta. Полученный список я обработала программой infoseq: infoseq -only -name -description -length translations.fasta > listed.txt Файл с трансляциями открытых рамок Таблица открытых рамок считывания Получите список аннотированных генов белков С сервера ncbi я скачала файлы по моей бактерии в форматах .faa и .ptt. Получила необходимую таблицу. Файл с последовательностями белков Таблица аннотированых генов Сравнение таблиц Правильная сравнительная таблица Сравнительная таблца (не очень хороший вариант) Уже проделав всю работу по неудобному и ненаглядному варианту таблицы, я подумала, что таблицы можно было объединить по-другому - чтобы значения из второй таблицы вставились между значениями первой. Я привела ссылку на эту таблицу, однако все изображения сделаны по другой. Данные при этом не изменились, поэтому примеры и выводы не должны измениться в зависимости от вида таблицы. Несомненно, что "правильная сравнительная таблица" в разы практичнее, чем неправильная. По заданию требуется привести не менее 10 примеров расхождений в таблицах. Это несложно сделать, потому что аннотированных белков у бактерии 9380, а открытых рамок нашлось 106717. Различия в таблицах удобно показать на самых первых открытых рамках, ведь данные отсортированы по номеру открывающего нуклеотида. Ниже приведен фрагмент таблицы - самое ее начало. 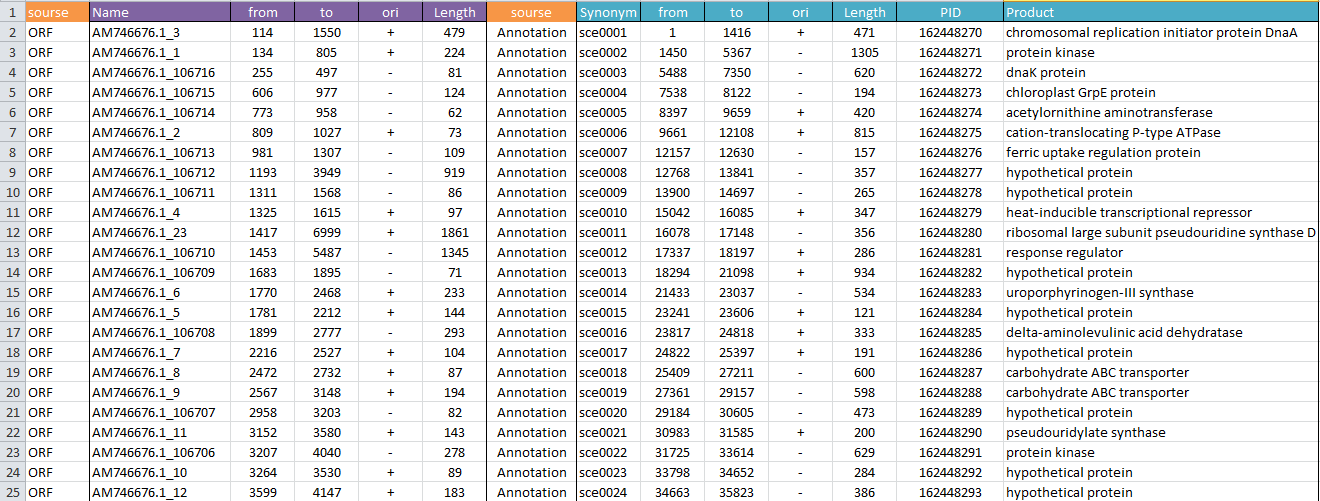 Во первых, рассмотрим первый аннотированный белок(1) DNAa, инициирующий репликацию хромосомы, и первую открытую рамку.  Кодирующий участок белка начинается с первого нуклеотида. Первая открытая рамка начинается со 114, поэтому часть гена этого белка ни в одну рамку не попадает. Это может быть вызвано тем, что мы смотрели открытые рамки от стоп-кодона до стоп-кодона, а белок начинает транслироваться со старт-кодона, который в геноме стоит раньше, чем первый стоп-кодон. Кончается же первая открытая рамка позже, чем кончается белок. Идем далее. Теперь посмотрим на следующие 6 открытых рамок в левой части таблицы.  Рамки, отмеченные красным, находятся на прямой цепи и попадают на участок, который кодирует DNAa, "собственных" белков не имеют. Рамки, отмеченные синим, находятся на обратной цепи. Можно заметить, что трансляция первого аннотированного белка по обратной цепи начинается с 1450 нуклеотида, а эти рамки лежат в промежутке от 255 по 1307 нуклеотиды - никакие аннотированные белки в них не попадают. Это объясняется тем, что не каждой открытой рамке должен соответствовать белок. Еще одно явное отличие - длина белков. При получении таблицы с открытыми рамками мы указали, что их длина должна быть не менее 180 нуклеотидов. Значит, белки длиной менее 60 аминокислот (не учтем некодирующие триплеты) не получат своей более-менее точной открытой рамки. Таких белков в таблице 84 штуки. Я получила их, отсортировав таблицу с аннотированными белками по длине. Ниже приведены первые 24 штуки, большинство из них гипотетические. 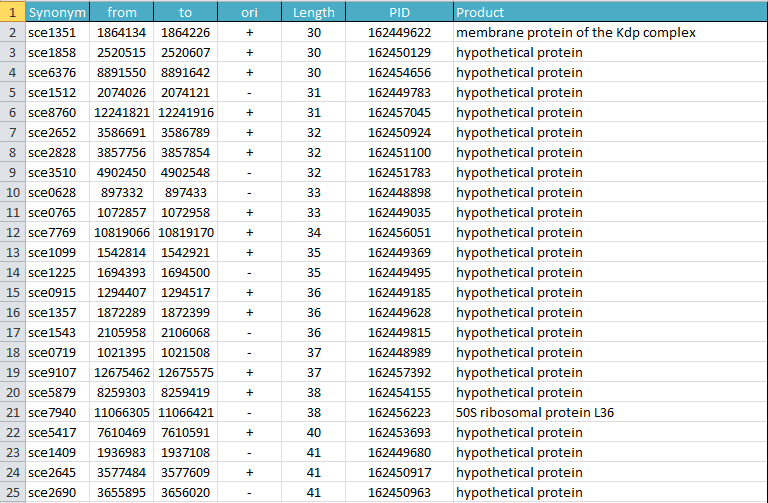 membrane protein of the Kdp complex  50S ribosomal protein L36  50S ribosomal protein L34  Приведу пример, когда рамка практически совпадает с рамкой трансляции белка. dnaK protein кодируется нуклеотидами с 5488 по 7350, на это очень похожа рамка с 5491 по 7365 нуклеотиды.   Рассмотрим белок, стоящий в таблице на 13 строчке - response regulator, длиной 286 аминокислот. Рассмотрим, с какими открытыми рамками перекраывается его рамка считывания. Такие рамки на прямой и обратной цепях представлены на рисунке ниже(это объясняется наличием стоп-кодонов на данном участке кольцевой днк). Интересно заметить, что рамки на 133 и 134 строчках антипарраллельны, их перекрытие составляет 829 нуклеотидов. А перекрытие между 131 и 132, также антипараллельными, составляет 166 нуклеотидов. Однако сложно объяснить данный феномен, так как белков, точно соответствующих данным рамккам нет. Есть только указанный мною response regulator. Вообще говоря, вероятнее будет транскрибироваться самая длинная рамка. |
|
© Шугаева Т.Е. 2014