Ресеквенирование. Поиск полиморфизмов у человека.
Задание 1. Анализ качества чтений и их очистка
В качестве референсной последовательности мне была дана вторая хромосома человека. В ходе выполнения практикума было использовано множество команд, которые можно увидеть в таблице 1.
| Команда | Для чего была использована |
|---|---|
| hisat2-build chr2.fasta chr2 | индексация референсной последовательности |
| fastqc chr2.fastq, fastqc chr2_2.fastq | анализ качества чтения, дает информацию о количестве ридов и их качестве |
| java -jar /nfs/srv/databases/ngs/suvorova/trimmomatic/trimmomatic-0.30.jar SE -phred33 chr2.fastq chr2_2.fastq TRAILING:20 MINLEN:50 | были убраны все нуклеотиды с конца, имеющие качество прочтения ниже 20 и все риды, длина которых меньше 50 |
| hisat2 -x chr2 -U chr2_2.fastq -S chr2_alignment.sam --no-spliced-alignment --no-softclip | построение выравнивания референсной последовтельности и прочтения в формате sam. Параметры нужны именно такие, так как мы работаем с экзонами, поэтому мы запрещаем картировать с разрывами.-X - индексированная референсная последовательность, после -U указываем на файл с прочтениями, после S - название выходного файла. |
| samtools view -b chr2_alignment.sam -o chr2_alignment.bam | перевод файла с выравниванием в бинарный файл с форматом .bam. -o - название выходного файла, -b - перевод файла в бинарный формат. |
| samtools sort chr2_alignment.bam chr2_sorted | сортировка выравнивания чтений с референсом по координате начала чтения в референсе. Выходной файл - chr2_sorted.bam |
| samtools index chr2_sorted.bam | индексирование сортированного предыдущей командой файла chr2_sorted.bam.bai |
| samtools mpileup -uf chr2.fasta -g -o poly.bfc chr2_sorted.bam | создание файла с полиморфизмами в формате .bcf. -o (название выходного файла), -g (выдает файл в формате bfc). |
| bcftools call -cv poly.bfc -o poly.vcf | переводим файл в более удобный для чтения человеком формат vcf. Получаем файл poly.vcf, который потом используем для описания трех полиморфизмов. |
| convert2annovar.pl -format vcf4 snp_only.vcf -o snp_only.avinput | для дальнейшей работы с программой annovar переводим файл в читаемый для нее формат. |
| annotate_variation.pl -out refgene -build hg19 -dbtype refGene snp_only.avinput /nfs/srv/databases/annovar/humandb/ | аннотация файла с snp по базе refgene. |
| annotate_variation.pl -filter -out snp138 -build hg19 -dbtype snp138 snp_only.avinput /nfs/srv/databases/annovar/humandb.old/ | аннотация файла с snp по базе dbsnp. |
| annotate_variation.pl -filter -out 1000_genomes -build hg19 -dbtype 1000g2014oct_all snp_only.avinput /nfs/srv/databases/annovar/humandb.old/ | аннотация файла с snp по базе 1000 genomes. |
| annotate_variation.pl -filter -out gwas -build hg19 -dbtype gwasCatalog snp_only.avinput /nfs/srv/databases/annovar/humandb.old/ | аннотация файла с snp по базе Gwas. |
| annotate_variation.pl -filter -out clinvar -build hg19 -dbtype clinvar_20140211 snp_only.avinput /nfs/srv/databases/annovar/humandb.old/ | аннотация файла с snp по базе Clinvar. |
Исходно было получено 10410 ридов, длина которых составляла от 40 до 100 нуклеотидов, а среднее качество прочтения - около 38%. После очистки чтений их количество уменьшилась слегка: до 10191, а длина стала не меньше 50 нуклеотидов, как мы того и требовали. На рисунках 1 и 2 можно видеть более информативную оченку качества чтений, полученную с помощью программы FastQC. По ним видно, что теперь качество каждого рида выше 20 и ничего не располагается в красной области. Из-за этого увеличилось и среднее арифметическое всех прочтений и, в целом, данные стали более надежныи, поэтому триммирование оправдано.
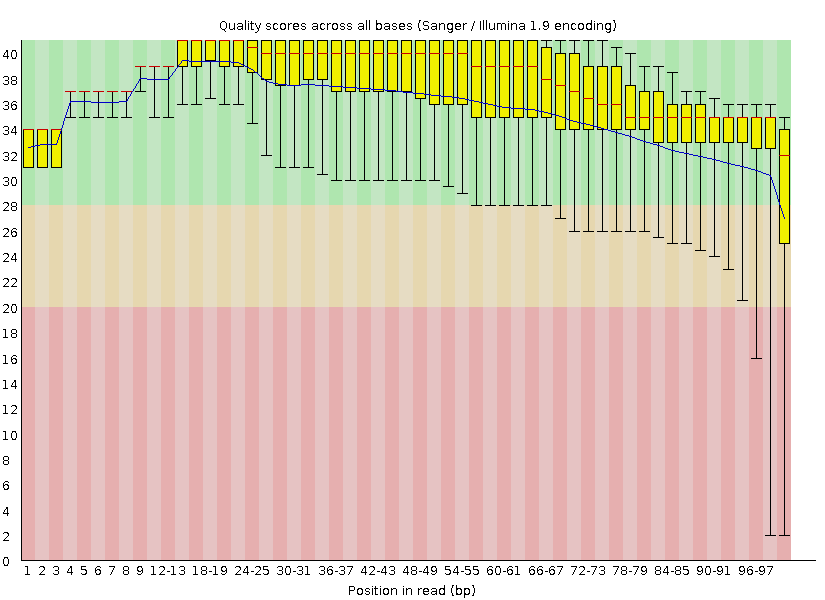
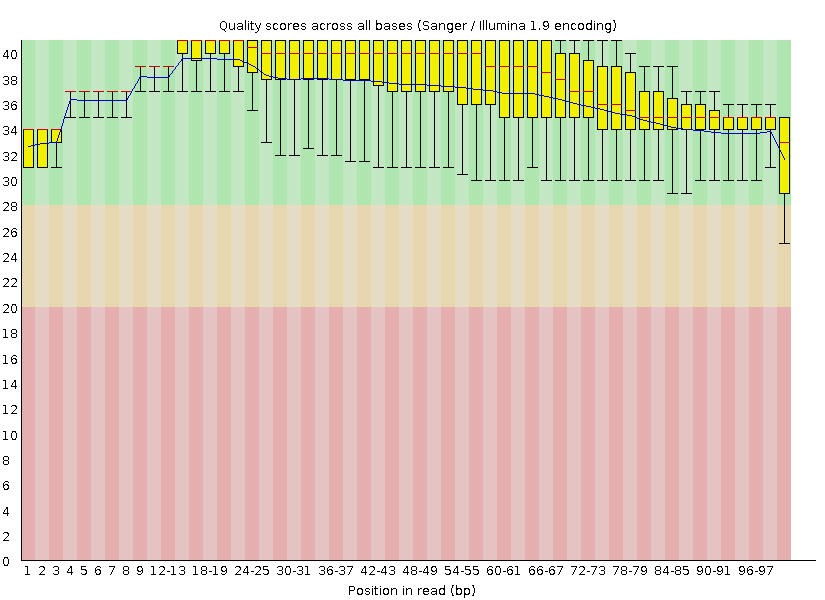
Задание 2. Анализ полученного выравнивания и поиск инделей и snp
По выводу программы Hisat2:
10191 (100.00%) were unpaired; of these:
47 (0.46%) aligned 0 times
10140 (99.50%) aligned exactly 1 time
4 (0.04%) aligned >1 times
99.54% overall alignment rate видно, что 99,5% чтений выравнились ровно один раз, всего 4 рида выравнились два и больше раза и 47 прочтений, что составляет около 0,46% не выравнились вообще. Можно сказать, что качество картирования высокое.
Для описания snp и инделей был получен файл poly.vcf. Он содержит описания 79 полиморфизмов, из которых 7 - это индели. Глубина покрытия (DP) указана в последнем столбце, а качество покрытия можно посмотреть в столбце Qual. Все полученный данные занесены в таблицу 2.
| № | Координата полиморфизма | Тип полиморфизма | Референс | Чтение | Глубина покрытия | Качество чтения |
|---|---|---|---|---|---|---|
| 1 | 234160243 | замена | G | C | 7 | 81.0075 |
| 2 | 234202274 | вставка | TCC | TCCC | 1 | 3.80767 |
| 3 | 234201186 | замена | А | G | 14 | 126.008 |
Проанализировав качество всех полиморфизмов, были получены следующие значения: среднее арифметическое: 70,46, а медиана - 127,23, то есть ровно половина значений больше медианы, но ненамного. Среднее значение глубины покрытий = 15,73, но медиана (=3,5) лучше характеризует этот показатель, так как видно, что около половины ридов накладываются на геном меньше четырех раз, но за счет некоторых участков с большой глубиной покрытия, среднее арифметическое оказывается высоким.
Задание 3. Аннотация SNP.
Программа convert2annovar.pl для файла только с SNP показала, что из 72 замен 50 являются транзициями, а 22 соответственно трансверсиями. Далее производилась аннотация полученного файла по различным базам. При аннотации по refgene был получен файл refgene.variant_function, в котором описано в каком участке ДНК произошла данная замена. Разделение получилось следующим: exonic (6), UTR3 (6), UTR5 (2),ncRNA_exonic (1), intronic (57). Гены, в которые попали SNP: CCCDC88A, ATG16L1, MLPH. Для шести замен, попавших в экзоны в файле refgene.exonic_variant_function, указано являются ли они синонимическими или нет. Синонимичной является только одна из них, попавшая в ген MLPH.
Из аннотации по базе snp можно понять, сколько snp имееют rs. Информация лежит в файле snp138.hg19_snp138_dropped, получается, что 67 snp имеют rs, то есть это те замены, которые есть в банке snp. Оставшихся 5 замен в банке нет, они лежат в файле snp138.hg19_snp138_filtered. Также была посчитана средняя частота найденных snp по аннотации по базе 1000 Genomes. Она составила 37.72%. А в целом она очень сильно варьируется, есть как и очень часто встречающиеся Snp, так и редкие. Одна аннотированная в Clinvar замена вызывает восприимчивость к воспалению кишечника, тогда как замен, аннотированных в Gwas, не было найдено вообще.