Задание 1. Программа getorf пакета EMBOSS
Программа getorf извлекает из нуклеотидной последовательности открытые рамки считывания. С помощью команды entret была получена запись D89965 из банка EMBL. Для того, чтобы получить открытые рамки длиной не менее 30 аминокислотных остатков и начинающиеся со старт-кодона (или начала последовательности) и заканчиваются стоп-кодоном (или концом последовательности), программа getorf использовалась со следующими параметрами:
getorf -find 1 -maxsize 90 -outfile D89965.orf D89965.entret
Было обнаружено 5 последовательностей, причем одна из них - D89965_3 - частично соответствует приведённой в поле FT кодирующей последовательности (CDS): координата последнего нк в найденной с помощью программы рамки меньше, чем у исходной на 3, т. к. в CDS рисутствует стоп-кодон.
Запись D89965 ссылается на последовательность hslv_ecoli.Для того, чтобы узнать, какой рамке соответствует эта последовательности, применили программу blastp:
blastp -query hslv_ecoli.fasta -subject d89965.orf -out blastp.out
Получили, что пятая рамка D89965_5, соответствующая обратной цепи, лучше всех выравнивается с hslv_ecoli
Query= HSLV_ECOLI P0A7B8 ATP-dependent protease subunit HslV (3.4.25.2)
(Heat shock protein HslV)
Length=176
Subject= D89965_5 [294 - 1] (REVERSE SENSE) Rattus norvegicus mRNA for RSS,
complete cds.
Length=98
Score = 200 bits (509), Expect = 4e-71, Method: Compositional matrix adjust.
Identities = 98/98 (100%), Positives = 98/98 (100%), Gaps = 0/98 (0%)
Query 28 MKGNVKKVRRLYNDKVIAGFAGGTADAFTLFELFERKLEMHQGHLVKAAVELAKDWRTDR 87
MKGNVKKVRRLYNDKVIAGFAGGTADAFTLFELFERKLEMHQGHLVKAAVELAKDWRTDR
Sbjct 1 MKGNVKKVRRLYNDKVIAGFAGGTADAFTLFELFERKLEMHQGHLVKAAVELAKDWRTDR 60
Query 88 MLRKLEALLAVADETASLIITGNGDVVQPENDLIAIGS 125
MLRKLEALLAVADETASLIITGNGDVVQPENDLIAIGS
Sbjct 61 MLRKLEALLAVADETASLIITGNGDVVQPENDLIAIGS 98
Почему в записи о фрагменте матричной РНК крысы есть сслыка на белок кишечной палочки? Для ответа на этот вопрос можно посмотреть запись о белке HSLV_ECOLI в SwissProt и найти там предупреждение:
CC -!- CAUTION: PubMed:9013898 sequence is supposed to originate from rat CC but, based on sequence similarity, it seems that this is a case of CC bacterial contamination from E.coli.
Взможно, такое несоответствие возникло из-за того, что секвенируемые крысы были заражены кишечной палочкой.
Задание 2. Файлы-списки
В задании требовалось получить файл с последовательностями дегидрогеназ из заданных организмов.
С помощью команды
seqret sw:adh*_* adh.fasta
были получены все доступные в Swissprot последовательности алкогольдегидрогеназ. Для того, чтобы получить файл с универсальными адресами (USA) этих последовательностей использовалась программа infoseq -only и -usa:
infoseq adh.fasta -only -usa > list.txt
Получите из этого файла-списка другой, меньший, с адресами только тех последовательностей, которые взяты из ваших организмов. Используйте программу grep с параметром -f, чтобы подать ей на вход список слов для поиска. На основе нового файла-списка получите fasta-файл с последовательностями дегидрогеназ ваших организмов. Используйте программу seqret (посмотрите в wiki, как подать на вход файл-список). В отчете укажите запущенные команды и их параметры. Дайте ссылку на файл с последовательностями ваших алкогольдегидрогеназ.Из этого файла-списка был создан меньший файл, с адресами только тех последовательностей, которые взяты из некоторых организмов. (Список организмов можно найти в файле.) Для этого использовалась команда grep с опцией -f:
grep -f pattern.txt list.txt > list2.txt
Fasta-файл с последовательностями дегидрогеназ моих организмов был получен с помощью команды seqret:
seqret @list2.txt adh_n.fasta
Файлы, полученные в этом задании, можно посмотреть здесь:adh.fasta,list.txt, list2.txt,adh_n.fasta
Задание 3. EnsEMBL
Идентификатор белка из задания 2 по online BLAST: VLDLR. Последовательность гена: d16532.fasta. Информацию о данном гене искали на портале EnsEMBL. Для начала искали ген в человеческом геноме сервисом "BLAST/BLAT". В результатах - несколько блоков.
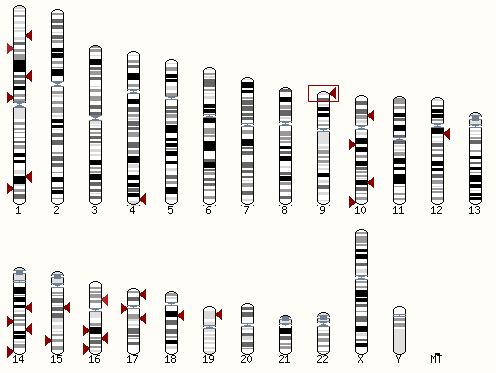
В блоке "Alignment Locations vs. Karyotype" можно увидеть расположение участка генома, который выравнялся с данным геном. В нашем случае это малое плечо 9 хромосомы, участок выделен рамочкой. Стрелочки - другие выравнивания, но не такие удачные. выравнивания
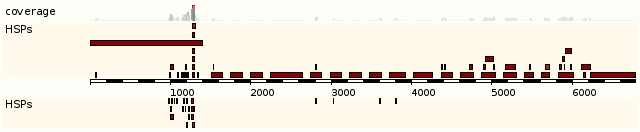
В следующем разделе "Alignment Locations vs. Query" в графическом виде приведена информация о полученном выравнивании (HSP - high-scoring segment pair):
В последнем блоке "Alignment Summary" даны общие сведения о выравниваниях: последовательности, позиции на гене хромосоме, цепь, score, e-val, процент идентичности, длина выравнивания, а так же ссылки (Links). Отображаемую информацию о хромосоме, гене(query) и т д можно выбирать.
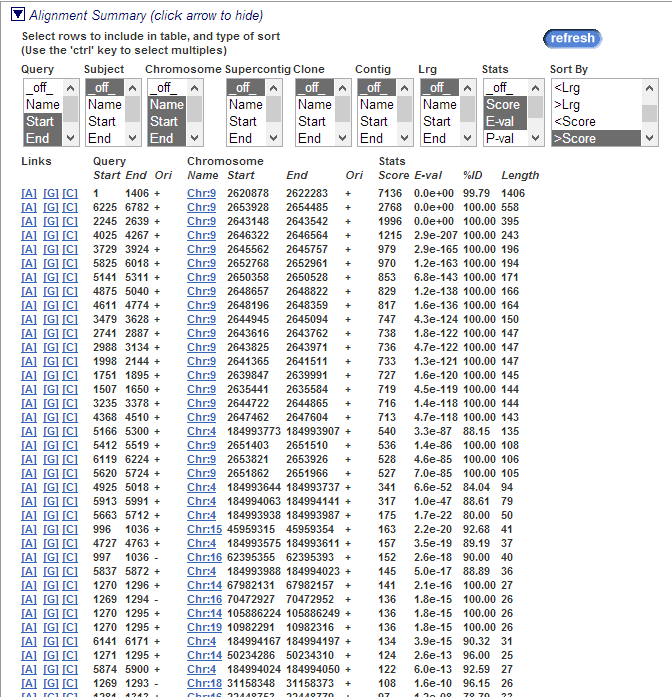
В "Links" есть 3 ссылки: [A] - Alignment, [G] - Genome Sequence, [C] - ContigView.
[A] приводит нас к более подробному описанию выбранного выравнивания:

[G] показывает нам последовательность хромосомы, на которой красным цветом отмечено выбранное выравнивание, желтым - экзоны, а синим - другие выравнивания(на данном участке их нет):

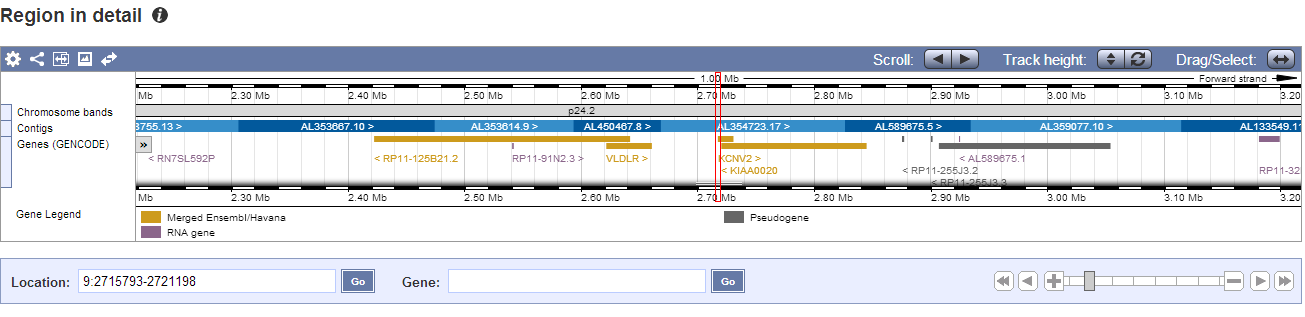
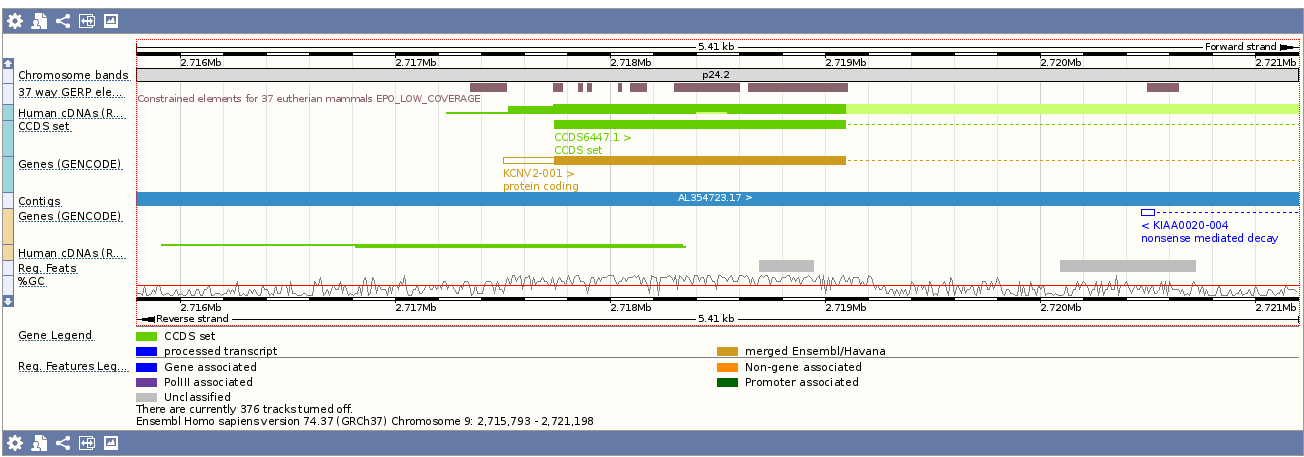
Пройдя по ссылке [C], можно посмотреть информацию о расположенных на участке хромосомы генах, о экзонах и интронах, контигах (Region in detail). Изображения с данными можно сохранять, регулировать параметры изображений(например, увеличивать масштаб), перемещаться по участку, получать информацию о генах, контигах и т д, нажимая на них. Итак, в [C] мы можем посмотреть 3 раздела:
- Положение на хромосоме
- Более детально описанную область с геном
- Локус хита