HMM-профили
Выбор семейства Pfam
Для выполнения данного практикума было выбрано семейство белков
PF00006 (ATP synthase alpha/beta family, nucleotide-binding domain),
с которым мы работали во втором семестре. В целом, АТФ-синтаза - белок не требующий представления, стоит лишь сказать, что
его каталитические сайты располагаются между исследуемыми нами альфа- и бета-субъедницами.
Количество белков в seed — 355
Количество белков в full — 55 092
Как подсемейство я выбрал белки со следующей доменной архитектурой:
PF00006 - PF22919 - PF02823
Такую архитектуру в частности отражает M0ZKF0 (H(+)-transporting two-sector ATPase) из картошки Solanum tuberosum
Всего таких белков оказалось 25, их последовательности мы скачали и выровняли с помощью программы muscle.
Построение HMM-профиля
Сперва, консольными методами, опираясь на полученное выравнивание, мы выделили части белковых последовательностей, которые соответствуют доменам. По полученному файлу domains.fasta мы уже строили HMM-профиль.
Для построения HMM-профиля мы использовали программу hmmbuild:
hmmbuild --amino hmm_result domains.fasta
где: --amino - опция указывающая на то, что выравненные последовательности аминокислотные
hmm_result - выходной файл
domains.fasta - выравненные последовательности доменов
Далее мы скачали все последовательности семейства PF00006 (39448 последовательностей), принадлежащих классу двудольных покрытосеменных растений (Magnoliópsida),
так как большинство белков из нашего подсемейства (24 из 25), принадлежат организмам из этого класса (проверили с помощью NCBI taxonomy).
Скачивать записи Rewieved, как сказано в задании, нам показалось нелогично, так как все белки нашего подсемейства unrewieved
Для нахождения белков со схожей доменной архитектурой применили функцию:
hmmsearch -o hmm_find hmm_result protein-matching-PF00006\(2\).fasta
где -o - название выходного файла
Всего было найдено 253 находки, что заметно больше, чем белков с нашей архитектурой
Определение оптимального порога
С помощью методов bash мы отсортировали наш файл, достав только записи соответствующие белкам, принадлежащим изучаемому подсемейству.
Наименьший score был у белка A0A6A6K0T2 - 367.6
С таким же или лучшим score оказалось еще почти 17500 последовательностей, что очень много.
Программа установила порог находки, на уровне score = 390.4, при такое пороге мы получаем 253 находки, из которых 22
принадлежат к нашему подсемейству. Нам кажется это не совсем оптимальным, поэтому попробуем взять другой порог.
Для определения наилучшего порога будем использовать ROC-кривую. Для этого сперва сделаем сводную таблицу последовательностей с весами и индексом принадлежности к подсемейству.
Далее полученную таблицу обработали следующим скриптом: Colab
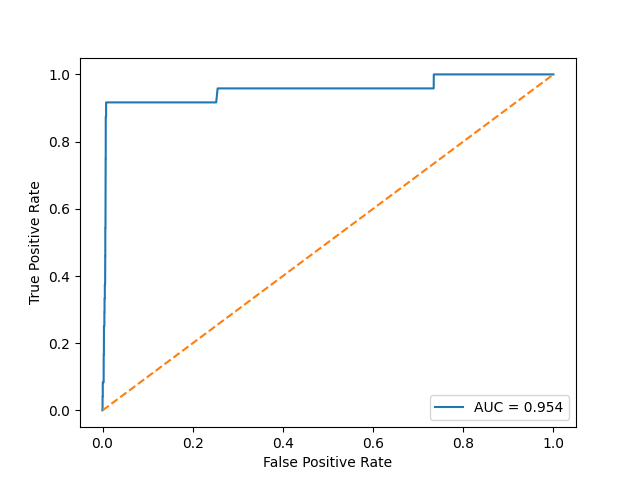
Рис. 1. ROC-кривая, AUC=(площадь под кривой)
Полученный оптимальный результат с помощью ROC-кривой = 392.1
Это порог сооветвующий точке на ROC-кривой наиболее удаленной от baseline.
Интересно заметить, что найденный нами порог очень близок, к тому, что выдала программа.
Охарактеризуем наш порог следующей таблицей:
| Вес выше порога | Вес ниже порога | |
|---|---|---|
| Принадлежит подсемейству | 22 | 2 |
| Не принадлежит подсемейству | 187 | 39 237 |