Геномная сборка Sphaeroforma arctica и нуклеотидные банки данных
Геномная сборка Sphaerofoma arctica
Для дальнейшей работы был выбран представитель класса Ichtyosporea из клады Holozoa — Sphaeroforma arctica (Рис. 0).
Данный организм является перспективным кандидатом в модельные организмы для изучения происхождения многоклеточности, в том числе из-за того, что класс Ichtyosporea филогенетически близок к Metazoa. Особеннотью Sphaeroforma arctica является относительно простой жизненный цикл без жгутиковых, амебоидных и почкующихся стадий, что облегчает его культивирование и изучение в лабораторных условиях и позволяет создавать синхронизированные популяции.

Также Sphaeroforma arctica в жизненном цикле проходит стадию многоядерного ценоцита (до 128 ядер, с этой стадией связано также то, что в отличие от многих других Ichtyosporea для S.arctica характерен закрытый митоз), подвергающегося целлюляризации с образованием поляризованного слоя клеток, напоминающего эпителий. Причем процесс целлюляризации обеспечивается актин-миозиновым комплексом, как и у Metazoa (например, при образовании бластодермы перибластулы у членистоногих).
Для Sphaeroforma arctica существуют 2 геномные сборки: одна с уровнем сборки Scaffold, другая — Contig. Для дальнейшего анализа была выбрана сборка с уровнем Scaffold, информация о ней приведена в Таблице 1.
| GenBank | GCA_001186125.1 |
| RefSeq | GCF_001186125.1 |
| Уровень сборки | Scaffold |
| Размер генома (п.н.) | 121 631 465 |
| Число скаффолдов | 15 619 |
| N50 для скаффолдов (п.н.) | 64 598 |
| L50 для скаффолдов | 516 |
| Число контигов | 25 774 |
| N50 для контигов (п.н.) | 7 125 |
| L50 для контигов | 3 774 |
Поисковые системы NCBI, ENA и DDBJ
Был произведен поиск белка кофилина (белок, стимулирующий деполимеризацию актиновых филаментов) на сайтах NCBI, ENA и DDBJ.
В случае базы данных NCBI был проиведен поиск по наличию слова cofilin в поле Title по базе данных Nucleotide: cofilin[Title]. Результаты поиска представлены в Таблице 2.
| База данных | mRNA | genomic DNA/RNA | Всего |
|---|---|---|---|
| GenBank | 1 617 (399) | 26 (7) | 1 695 (406) |
| RefSeq | 2 165 (4) | 9 (8) | 2 190 (15) |
| Всего | 3 782 (403) | 35 (15) | 3 885 (421) |
Стоит отметить, что не все данные последовательности имеют непосредственное отношение к белковому продукту. Например, была найдена 5'-нетранслируемая область мРНК кофилина (D28345.1).
На сайте ENA был проиведен поиск нуклеотидных последовательностей человека, содержащих в полях Description или Scientific Name слово cofilin. Было найдено 400 мРНК (mRNA) и 2 геномные последовательности (genomic DNA).
Запрос в ENA для мРНК: tax_eq(9606) AND (description="cofilin" OR scientific_name="cofilin") AND mol_type="mrna"
Запрос в ENA для геномных последовательностей: tax_eq(9606) AND (description="cofilin" OR scientific_name="cofilin") AND mol_type="genomic dna"
На сайте DDBJ был осуществлен поиск нуклеотидных последовательностей кофилина человека (при запросе слово cofilin использовалось в поле Definition, был выбран раздел HUM в поле Division, тип молекулы, mRNA или DNA, задавался в поле Molecular Type). Было найдено 19 мРНК (mRNA) и 2 геномные последовательности (DNA).
Из данных поисковых систем самой привычной и простой в использовании кажется NCBI, однако интерфейс составления запросов несколько удобнее в ENA. Для биоинформатических целей я бы скорее стал использовать NCBI, в том числе потому, что, по-видимому, поисковая система NCBI позволяет найти большее количество разнообразных записей по сравнению с ENA и DDBJ по сходному запросу.
Файлы сборки из NCBI FTP
Описание файлов данной сборки, найденных при помощи NCBI FTP:
Файлы директории *_assembly_structure — Файлы, предоставляющие детализированную информацию о структуре геномной сборки. В поддиректории non-nuclear содержаться файлы, характеризующие единтсвенный митохондриальный скаффолд сборки, в поддиректории Primary_Assembly — все остальные. В файлах формата AGP описывается, каким образом контиги объединяются в скаффолды. Есть файлы, в которых приведены AC контигов (component_localID2acc) и скаффолдов (scaffold_localID2acc).
*_assembly_report.txt — Файл, содержащий общую информацию о сборке, а также информацию о всех скаффолдах сборки.
*_assembly_stats.txt — Статистические данный о геномной сборке, такие как суммарная длина (total-length), длина без гэпов (ungapped-length), L50, N50 и т.д.
*_cds_from_genomic.fna.gz — Последовательности CDS.
*_fcs_report — Последовательности, определенные как вероятный результат контаминации.
*_feature_count.txt.gz — Статистическая информация о количествах различных геномных особенностей, таких как CDS, гены тРНК, псевдогены и др.
*_feature_table.txt.gz — Таблица геномных особенностей.
*_gene_ontology.gaf.gz — Аннотация GO для аннотированных генов.
*_genomic.fna.gz — Нуклеотидные последовательности геномной сборки.
*_genomic.gbff.gz — Последовательности сборки с аннотациями.
*_genomic.gff.gz — Аннотации последовательностей в формате GFF.
*_genomic.gtf.gz — Аннотации последовательностей в формате GTF.
*_genomic_gaps.txt.gz — Информация о гэпах, описанных в файлах AGP.
*_protein.faa.gz — Аминокислотные последовательности аннотированных белковых продуктов.
*_protein.gpff.gz — Аннотации белковых продуктов.
*_rna.fna.gz — Нуклеотидные последовательности аннотированных РНК-продуктов.
*_rna.gpff.gz — Аннотации РНК-продуктов.
*_rna_from_genomic.fna.gz — Аннотированные участки генома, кодирующие РНК.
*_translated_cds.faa.gz — Аминокислотные последовательности протранслированных аннотированных CDS.
Из данных файлов можно понять, например, что в сборке есть один скаффолд, определенный как митохондриальный (файл *_assembly_report.txt). Также в данной сборке аннотированы 18730 CDS, 18213 белок-кодирующих генов, 106 псевдогенов, 6 генов рРНК, 318 генов тРНК и 18 псевдогенов тРНК (файл *_feature_count.txt.gz).
Помимо прочего именно в файле *_assembly_stats.txt содержатся полные данные о таких параметрах, как число контигов и скаффолдов, N50 и L50. На странице сборки в NCBI Datasets приведены данные лишь для единицы сборки (Assembly Unit) Primary Assembly, тогда как единица сборки non-nuclear не учтена.
Органеллы
В рассматриваемой геномной сборке имеется один скаффолд, определенный как митохондриальный. В файле *_assembly_report.txt для единицы сборки non-nuclear, в которую входит этот скаффолд, указаны отдельные AC: GCA_001187675.1 (GenBank) и GCF_001187675.1 (RefSeq). Последовательность данного скаффолда имеет AC NW_014024939.1 в RefSeq.
Однако, для данного скаффолда отсутствуют какие-либо аннотации (Рис. 1).

Диаграмма длин фрагментов генома
Для скаффолдов геномной сборки методами Python была построена диаграмма, отражающая распределение их длин (Рис. 2, данные о N75, L75, N90 и L90 взяты из файлов *_assembly_stats.txt и *_assembly_report.txt, фрагменты для подсчета длин — из файла *_genomic.fna)
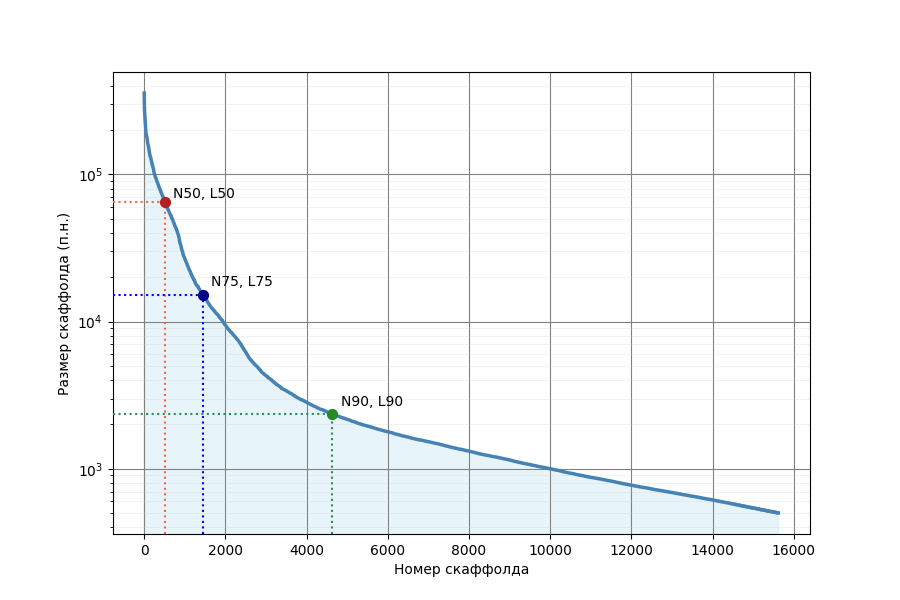
Как можно видеть, качество геномной сборки оставляет желать лучшего. Значение L50 имеет порядок сотен (516), параметр N50 (64.6 kb) выглядит незначительным в сравнении с длиной всей сборки (121.6 Mb) и длиной без гэпов (97.5 Mb, получена из файла *_assembly_stats.txt), которые при этом не равны, что также говорит не в пользу качества данной сборки. Также из Рисунка 2 можно видеть, что большая часть скаффолдов (почти 12000 из 15619) имеет длину от 500 до 3000 п.н.