Поиск белков подсемейства при помощи HMM-профиля
Выбор семейства и подсемейства
Бактериальные пили в широком смысле могут сильно отличаться друг от друга по структуре и способу сборки. Помимо достаточно типичных для грамотрицательных бактерий вариантов секреции и сборки, характерных для пилей IV типа (структурно сходных с системами секреции II типа), половых и T-пилей (в составе системы секреции IV типа), P-пилей и фимбрий 1 типа (механизм chaperone-usher), существует более экзотический способ, характерный для curli (амилоидных поверхностных структур бактерий) - внеклеточная нуклеация-преципитация.
Внеклеточная часть этих структур образована белками CsgA и CsgB, формирующими амилоидные волокна, которые играют роль в образовании биопленок некоторыми энтеробактериями. При этом белок CsgG выступает в роли нуклеатора полимеризации CsgA. Центральную роль в системе секреции CsgA и CsgB (системе секреции VIII типа) играет белок CsgG, нонамер которого образует пору, пересекая внешнюю мембрану 36 раз (Рис. 1). Помимо этого CsgG также нужен для связывания белка CsgF, который в свою очередь закрепляет нуклеатор CsgB около поры.
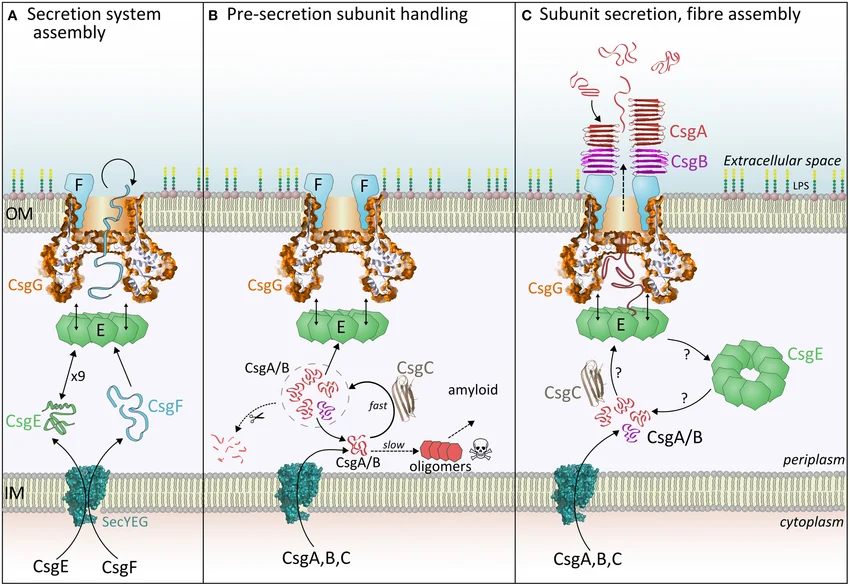
Благодаря своей стабильности, поры из CsgG нашли применение в нанопоровом секвенировании, а комплексная пора из CsgG и CsgF (содержащая в канале два сужения, в отличие от большинства других пор) дает более сложный сигнал при прохождение через нее нуклеиновой кислоты, что позволяет секвенировать гомополимерные участки с большей точностью.
Для дальнейшего анализа было выбрано семейство Pfam компонентов системы секреции структур curli CsgG (Curli production assembly/transport component CsgG; ID: CsgG; AC: PF03783, всего 7 061 белок, из них 2 145 в full и 10 в seed).
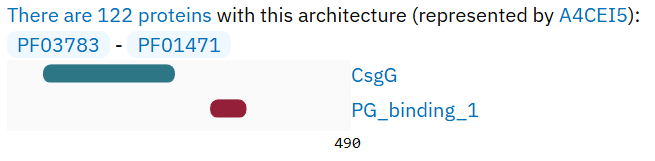
В этом семействе было выбрано подсемейство из 122 белков, которые помимо основного домена CsgG содержат также предполагаемый пептидогликан-связывающий доменом (Putative peptidoglycan binding domain, доменная структура: PF03783 - PF01471, см. Рисунок 2).
Построение HMM-профиля
Наиболее логичным вариантом для получения HMM-профиля, который позволил бы отделить белки подсемейства от прочих белков семейства, выглядит его построение по последовательностям пептидогликан-связывающего домена (далее - PGBD). Но все же было бы интересно проверить, сможет ли HMM-профиль, построенный по доменам CsgG белков подсемейства, с приемлемой точностью определять эти белки на фоне остальной части семейства.
Для получения последовательностей доменов был написан скрипт на Python, который для каждого представителя подсемейства через InterPro API находит координаты доменов CsgG (AC: PF03783) и PGBD (AC: PF01471) и вырезает их из аминокислотной последовательности.
Полученные последовательности доменов CsgG и PGBD были выровнены при помощи MAFFT:
mafft CsgG_PGBD.fasta > CsgG_PGBD_align.fasta
mafft CsgG_CsgG.fasta > CsgG_CsgG_align.fasta
На основании полученных выравниваний были построены HMM-профили:
hmmbuild --amino CsgG_PGBD.hmm CsgG_PGBD_align.fasta
hmmbuild --amino CsgG_CsgG.hmm CsgG_CsgG_align.fasta
При помощи HMM-профилей был осуществлен поиск белков рассматриваемого подсемейства среди всех белков семейства:
hmmsearch --tblout found_PGBD.txt CsgG_PGBD.hmm CsgG.fasta
hmmsearch --tblout found_CsgG.txt CsgG_CsgG.hmm CsgG.fasta
Анализ результатов поиска
Полученные в формате TSV результаты поиска по HMM-профилям доменов CsgG и PGBD были обработаны при помощи скрипта на Python.
При поиске по профилю, построенному по домену CsgG, первичные фильтры HMMER прошли 6 231 последовательность семейства. При использовании же HMM-профиля на базе домена PGBD в итоговой области поиска оказались лишь 128 белков. И в том и в другом случае все 122 белка подсемейства прошли первичные фильтры и попали в область поиска.
Используемый скрипт на основании данных из таблицы находок и списка AC белков подсемейства создает таблицу, в которой в отдельной колонке указана принадлежность (1) или не принадлежность (0) белка к подсемейству. Также он строит графики ROC (Reciever Operating Characterictics, TPR от FPR) и PR (Precision-Recall, TPR от PPV) и определяет потенциальные оптимальные пороговые значения веса по показателям J (для ROC-кривой, расстояние до главной диагонали) и F1 (для PR-кривой, среднее гармоническое PPV и TPR). В дальнейшем рассматривается счет выравнивания для лучшего найденного домена.
\(\text{TPR (True Positive Rate, Recall, Sensitivity)} = \frac{TP}{P} = \frac{TP}{TP + FN}\)
\(\text{FPR (False Positive Rate, Recall)} = 1 - Specificity = \frac{FP}{N} = \frac{FP}{FP + TN}\)
\(\text{PPV (Positive Predictive Value, Precision)} = \frac{TP}{TP + FP}\)
\(\text{J} = TPR - FPR\)
\(\text{F1} = \frac{2 \cdot TPR \cdot PPV}{TPR + PPV}\)
P - реальное число положительных результатов, N - реальное число отрицательных результатов. TP - истинноположительные результаты, FP - ложноположительные результаты, TN - истинноотрицательные результаты, FN - ложноотрицательные результаты.
При заданном пороговом значении для веса показатель TPR отражает долю реальных положительных результатов, преодолевших порог; FPR - долю реальных отрицательных результатов, преодолевших порог; PPV - долю истинноположительных находок среди всех находок, преодолевших порог.
Как можно видеть из полученных графиков (Рис. 3) и модифицированной таблицы, HMM-профиль, построенный по выравниванию доменов PGBD, позволяет практически идеально выделять представителей подсемейства на фоне остальных белков семейства. Оптимальный порог по весу, определнный по показателю J - 52.1, по показателю F1 - 34.9. Первый вариант позволяет отсечь 121 представителя подсемейства и не получить ни одного ложноположительного срабатывания. Второй же позволяет выбрать все 122 искомых белка, но захватить при этом 1 ложноположительный.
Такая ситуация объясняется тем, что один из белков подсемейства (A0A948W813_UNCEI) имеет меньший вес выравнивания с профилем, чем один из белков, не входящих в подсемейство (A0A644Z869_9ZZZZ). Это может быть связано с тем, что данный белок подсемейства имеет укороченный по сравнению с другми аннотированный домен PGBD.

Вероятно, в данном случае будет лучше установить порог, не допускающий возникновения ложноположительных результатов (55.0). Численные характеристики выделения подсемейства HMM-профилем приведены в таблице 1.
| Преодоление порога | В подсемействе | Не в подсемействе | Всего |
|---|---|---|---|
| Да | TP = 121 (121) | FP = 0 (0) | 121 (121) |
| Нет | FN = 1 (1) | TN = 6 (6 939) | 7 (6 940) |
| Всего | 122 (122) | 6 (6 939) | 128 (7 061) |
В случае HMM-профиля, построенного по последовательностям доменов CsgG, ситуация иная (что видно в том числе в модифицированной таблице). Согласно кривой ROC (Рис. 4) данный профиль все еще очень эффективно определяет принадлежность и не принадлежность белков к подсемейству. Однако, такая картина очень обманчива и столь близкий к идеальному результат объясняется во многом тем, что размер подсемейства (122 белка) значительно меньше области поиска (6 231 белок).

При этом кривая PR показывает куда более скверную картину. Оптимальный порог по показателю J - 207.7, выше него оказываются 119 из 122 белков подсемейства и 209 ложноположительных находок. По показателю F1 оптимальный порог - 233.6, больше него набирают 114 из 122 белков подсемейства, а также 133 белка, не имеющих к подсемейству отношения.
Можно полагать, что как PR-кривая в рассматриваемой ситуации намного лучше отражает действительную эффективность классификатора, так и в качестве порога лучше выбрать тот, при котором максимален будет показатель F1 - 233.6. Численные характеристики такой попытки выделения подсемейства приведены в таблице 2.
| Преодоление порога | В подсемействе | Не в подсемействе | Всего |
|---|---|---|---|
| Да | TP = 114 (114) | FP = 133 (133) | 247 (247) |
| Нет | FN = 8 (8) | TN = 5 976 (6 806) | 5 984 (6 814) |
| Всего | 122 (122) | 6 109 (6 939) | 6 231 (7 061) |
В целом из полученных результатов видно, что HMM-профиль, построенный по выравниванию последовательностей домена, специфичного для подсемейства, позволяет с намного большей точностью определять представителей этого подсемейства среди всех белков семейства.
ЛИТЕРАТУРА И ИСТОЧНИКИ
Taylor JD, Matthews SJ. New insight into the molecular control of bacterial functional amyloids. Front Cell Infect Microbiol. 2015 Apr 8;5:33. doi: 10.3389/fcimb.2015.00033. PMID: 25905048; PMCID: PMC4389571.