
1. Получение последовательности ДНК на основании хроматограммы
В данной части практикума необходимо было проанализировать имеющуюся хроматограмму (а точнее две хроматограммы) и получить последовательность ДНК. Нам были выданы каждому по два файла, содержащие в себе хроматограммы прямой и обратной последовательностей: 37_F.ab1 и 37_R.ab1. Для анализа использовался онлайн-редактор Pearl.
Как по мне, качество Хроматограммы достаточно хорошее. Уровень шума низок и достаточно равномерен, подавляющее большинство нуклеотидов Pearl смог опознать. Но, была и пара затруднительных моментов. В редакторе был выставлен пункт: "Treat secondary peaks as conflicts", чтобы точно ничего не пропустить. В случаях, когда обратная цепь не могла помочь разрешить неопределённость, я выставлял "N" (Pearl не давал сделать это маленькими буквами). Большинство изменений были зафиксированы, а затем объединены в коллажи в зависимости от того, была ли для них обратная цепь, разрешающая проблему.
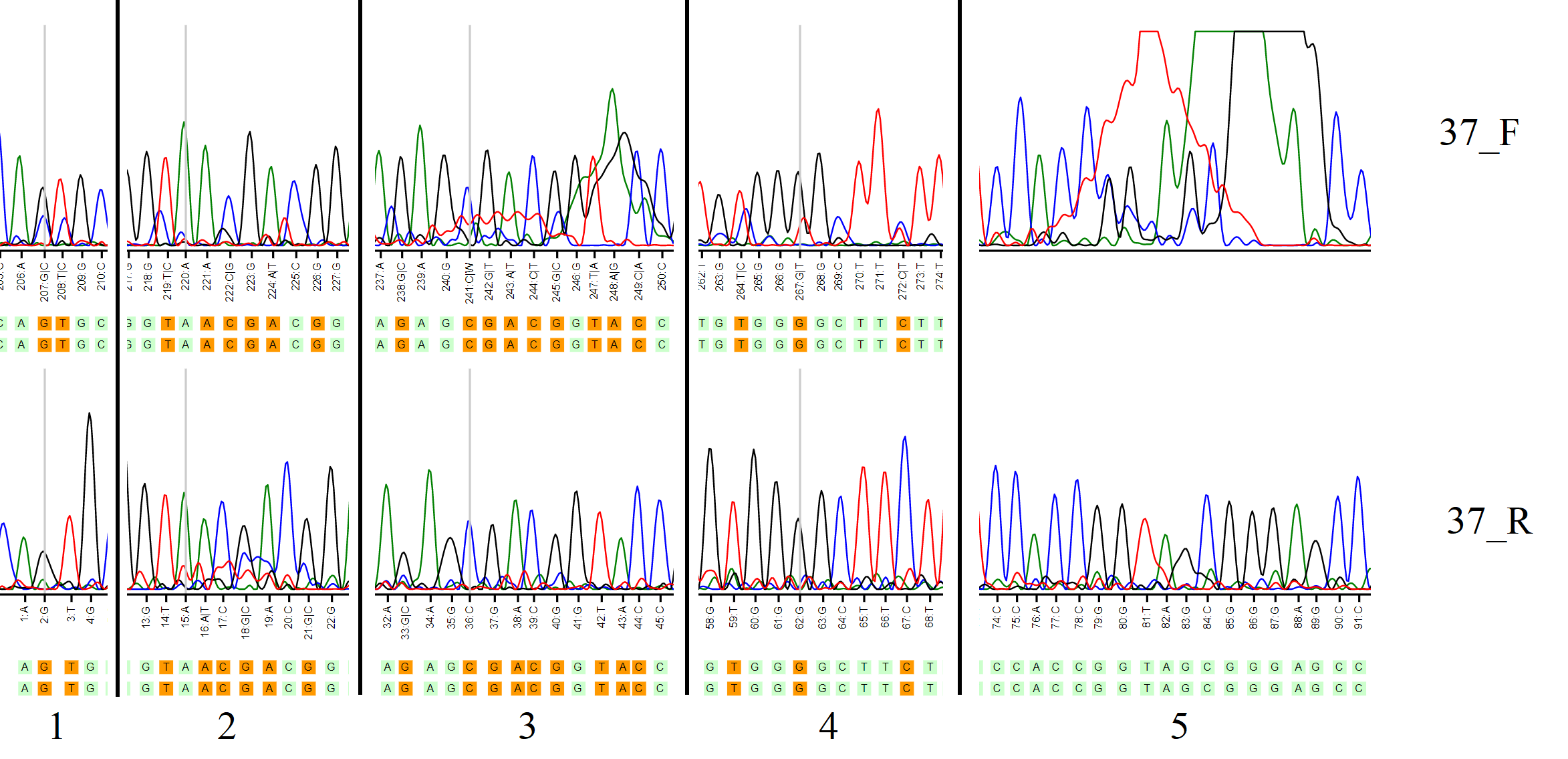
Рис. 1. Решённые проблемные участки.
Как видно из рисунка, Pearl сам исправлял неопределённости, опираясь на вторую цепь. В 1 случае в цепи 37_F нуклеотиды 207 и 208 были уточнены (G и T соответственно). Во 2 - проблемный участок на цепи 37_R с координатами 14-21 был уточнён (TAACGACG). В 3 - достаточно масштабный участок на 37_F (238-249) был исправлен при помощи 37_R. На 5 виден нечитаемый участок 37_F, информацию о котором нам даёт 37_R.
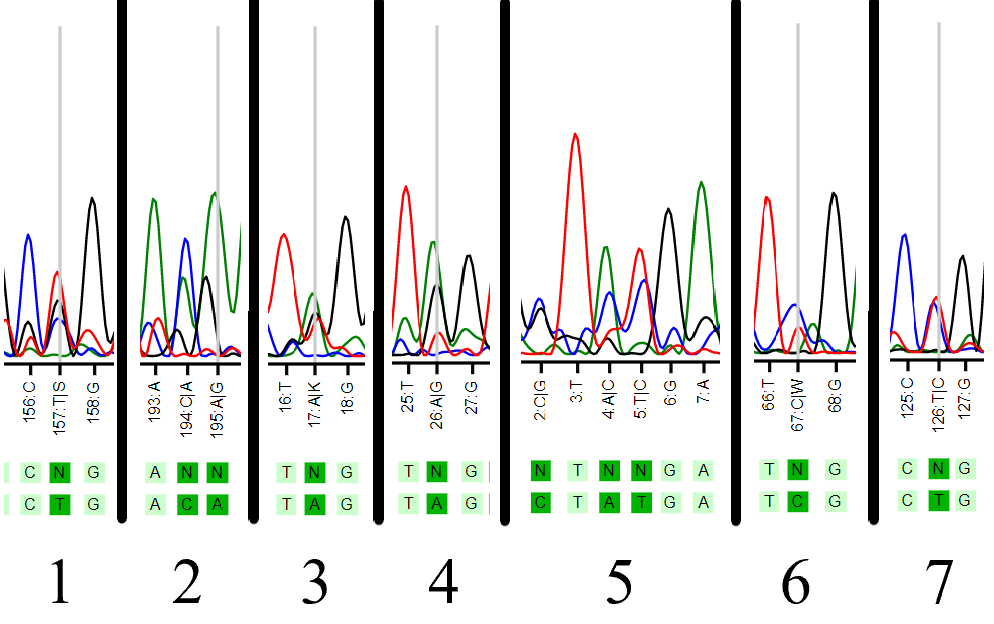
Рис. 2. Неопределённые нуклеотиды.
К сожалению, в некоторых случаях опираться было не на что, так что я выставлял в таких местах "N", что значит, что мы не знаем точно, какой там стоит нуклеотид. Примеры приведены на картинке выше.
Из Pearl было выгружено выравнивание (файл), которое, к сожалению я не смог перевести из формата .json в .fasta (простите, пожалуйста). Затем была получена консенсусная последовательность (файл).
2. Поиск нечитаемых участков
В предыдущей части практикума уже были приведены некоторые проблемные участки, поэтому здесь я решил добавить то, что туда не вошло. А именно само начало хроматограммы. Из-за того, что в самом начале длины исследуемых фрагментов очень малы, мы имеем достаточно сильную погрешность, связанную с неточностью прибора при анализе таких коротких фрагментов. Ниже я привожу начала своих хроматограмм, чтобы показать это.
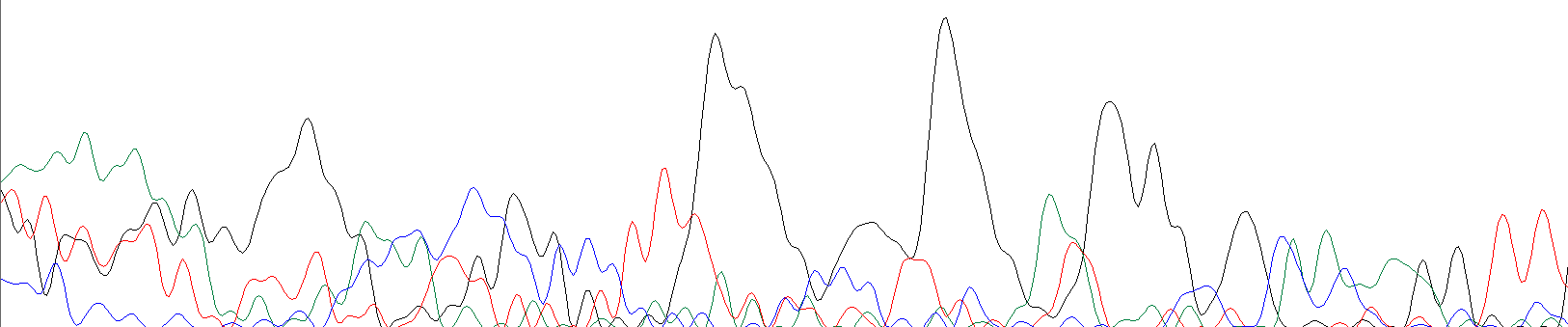
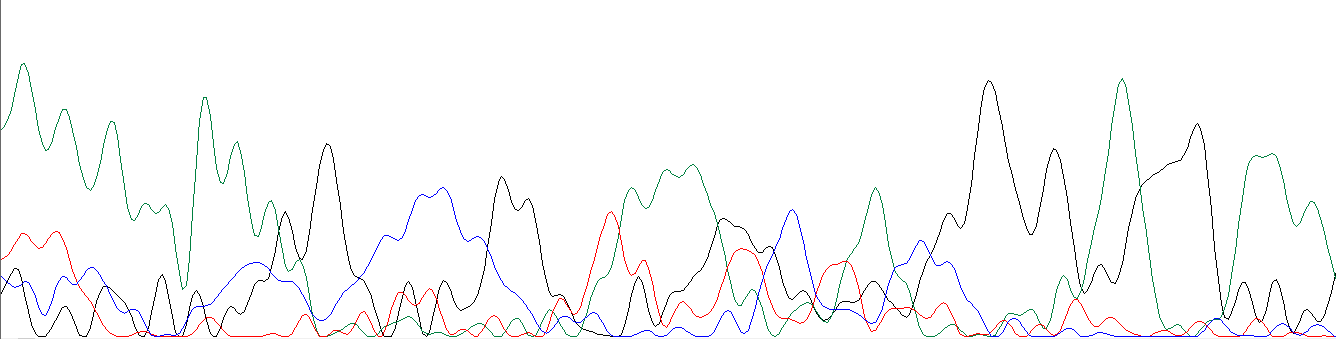
Рис. 5,6. Нечитаемое начало хроматограмм