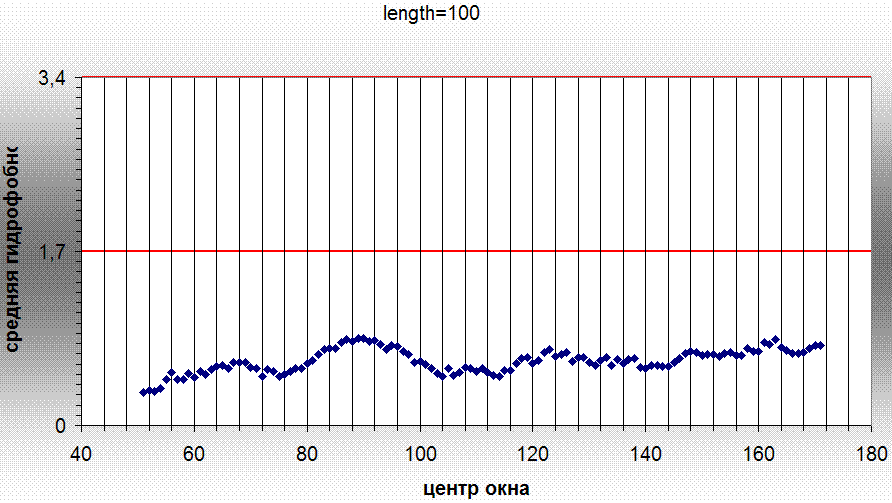
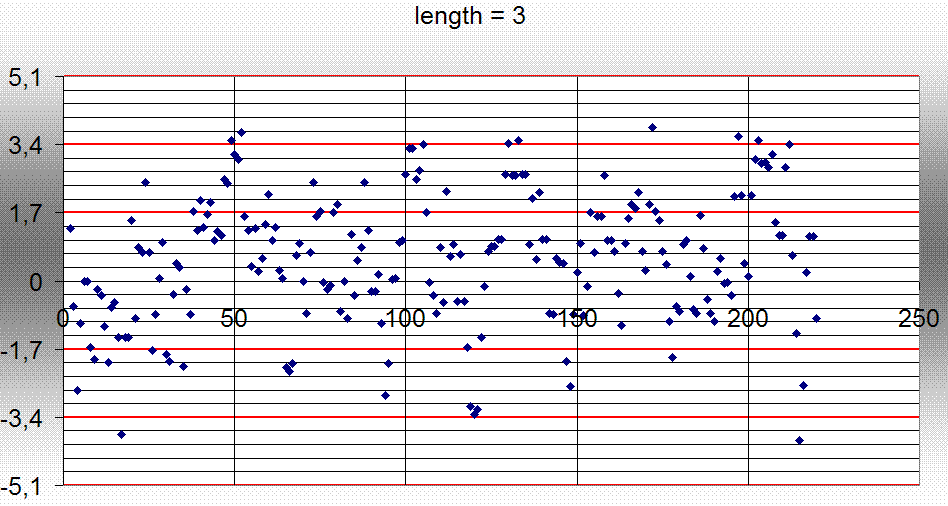
| топология | тип петли | количество остатков аргинина и лизина в петли | общее количество остатков в петелях данного типа | процентное содержание |
| ОМР (для последовательности цепи А белка 1VF5) | внутренние (стромальные) | 7 | 47 | 0,15 |
|---|---|---|---|---|
| внешние (тиллакоидные петли) | 6 | 84 | 0,07 | |
| ТМНММ (для последовательности анализируемого белка Q116S5) | внутренние (стромальные) | 9 | 58 | 0,16 |
| внешние (тиллакоидные петли) | 5 | 72 | 0,07 |
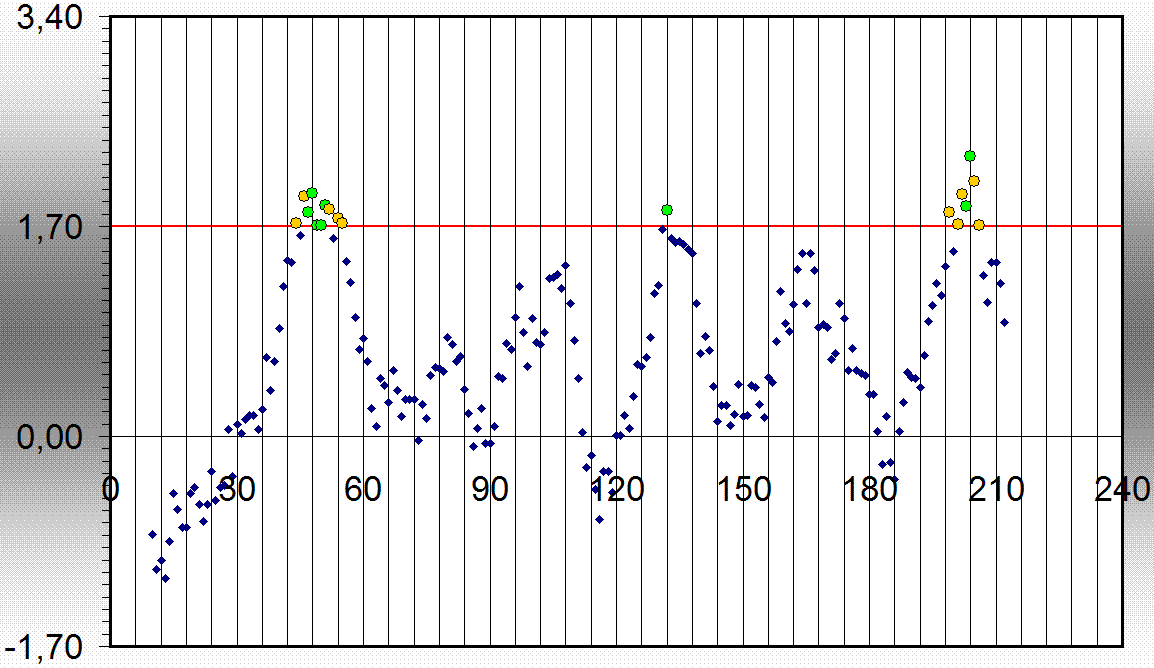
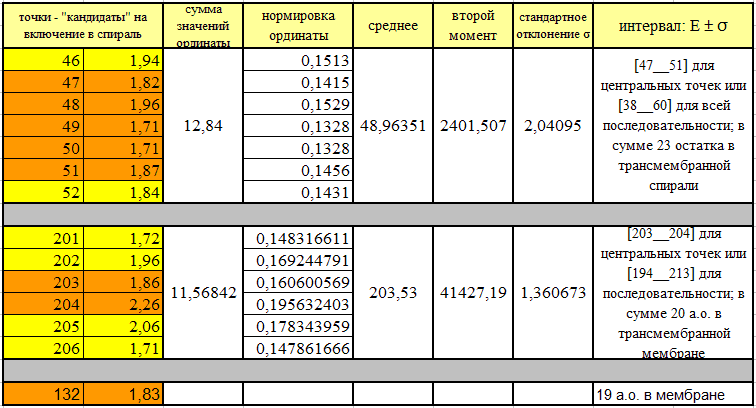
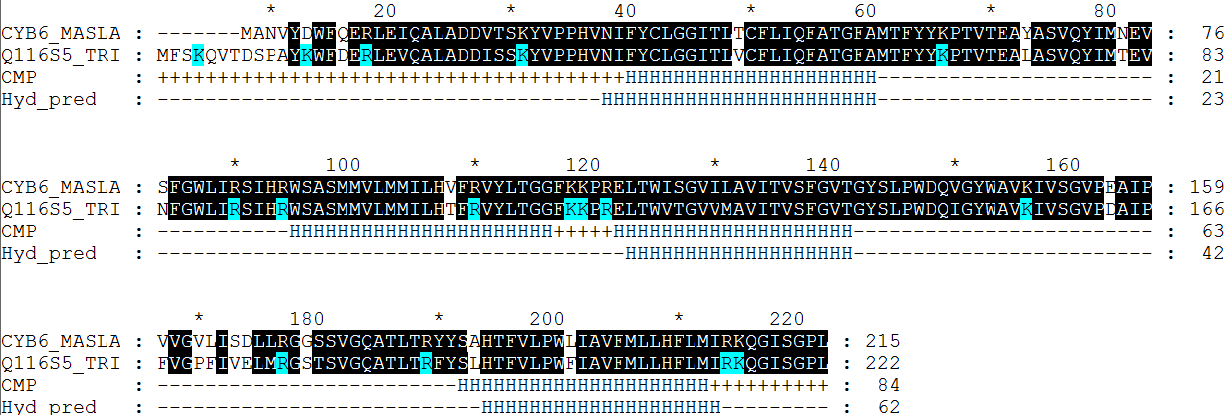
| топология | номер петли | количество остатков аргинина и лизина в петли | общее количество остатков в петли | процентное содержание этих основных аминокислот |
| Hyd_pred (для последовательности Q116S5) | №1 | 4 | 37 | 0,108 |
|---|---|---|---|---|
| №2 | 7 | 62 | 0,113 | |
| №3 | 3 | 52 | 0,058 | |
| №4 | 2 | 9 | 0,222 |
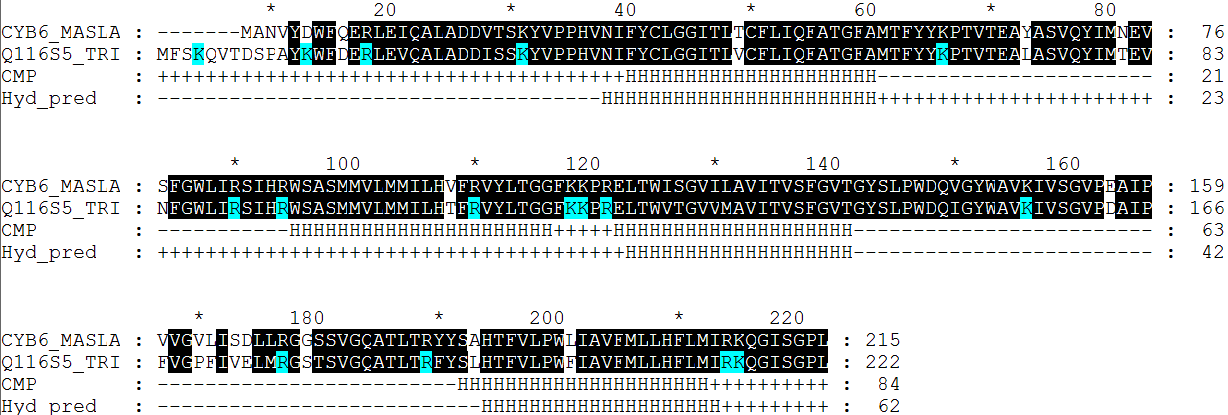

| Число аминокислотных остатков (или доля а.о.) | |
| Всего а.к. остатков | 222 |
| Остатки, предсказанные как локализованные в мембране (всего) | 62 |
| Правильно предсказано (true positives, TP) | 59 |
| Предсказано не то, что нужно (false positives, FP) | 3 |
| Правильно не предсказано (true negatives, TN) | 135 |
| Не предсказано то, что нужно (false negatives, FN) | 25 |
| Чувствительность (sensivity) = TP / (TP+FN) | 0,70 |
| Специфичность (specificity) = TN / (TN+FP) | 0,98 |
| Точность (precision) = TP / (TP+FP) | 0,95 |
| Сверхпредсказание = FP/ (FP+TP) | 0,05 |
| Недопредсказание = FN / (TN+FN) | 0,16 |