Встреча с Pfam и HMM
Для работы был выбран домен putative serine dehydratase domain(PF14031). Этот домен найден в D-сериндегидратазе на С-конце. Для изучения была выбрана следующая доменная архитектура (Pfam говорит, что такая архитектура содержится в 4030 последовательностях).

Для поиска в UniProt был создан запрос database:(type:pfam pf01168) database:(type:pfam pf14031), который нашёл все белки с двухдоменной архитектурой. Белков в UniProt оказалось более
10000, поэтому были взяты белки из царства Eukaryota. Скачанные белки можно посмотреть в этой ссылке.
Далее была построена гистограмма длин белков, она представлена на Рисунке 2.
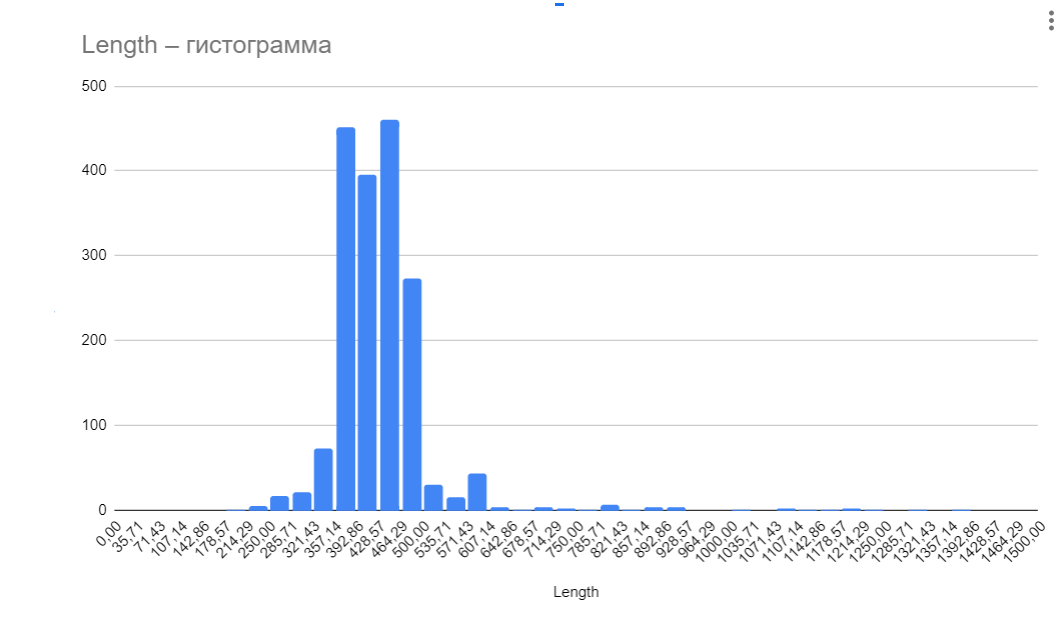
45 белков с длиной 350-500 нуклеотидов из разных таксонов были отобраны для дальнейшей работы (их можно посмотреть на листе "выбранные 45" в гугл-таблице, ссылка на которую представлена
выше).
Для скачивания последовательностей белков был написан вот такой скрипт. Для создания
единого файла со всеми последовательностями и последующего выравнивания использовались команды:
muscle -in all_seq.fasta -out aligned_all.fasta
Затем пришло время ревизии множественного выравнивания. Для этого файл aligned_all.fasta был визуализирован в JalView и убраны части до самого левого N-концевого блока и после последнего C-концевого блока. Также были убраны последовательности, значительно отличающиеся от большинства. Отредактированное выравнивание можно скачать здесь.

Затем были запущены следующие команды:
hmm2build out_hmm.hmm aligned_all_reviewed.fastahmm2calibrate out_hmm.hmm
С помощью этих команд был построен и откалиброван hmm-профиль.
Затем были скачаны все последовательности из Uniprot, которые содержат выбранный домен. С помощью команды hmm2search —cpu 1 -E 0.1 out_hmm.hmm pfam.fasta > results.txt была проведена
проверка по hmm-профилю. Файл с результатами можно посмотреть
здесь.
Получена таблица с весами всех находок, которая затем была отсортирована, и был построен график весов выравниваний, который представлен ниже.
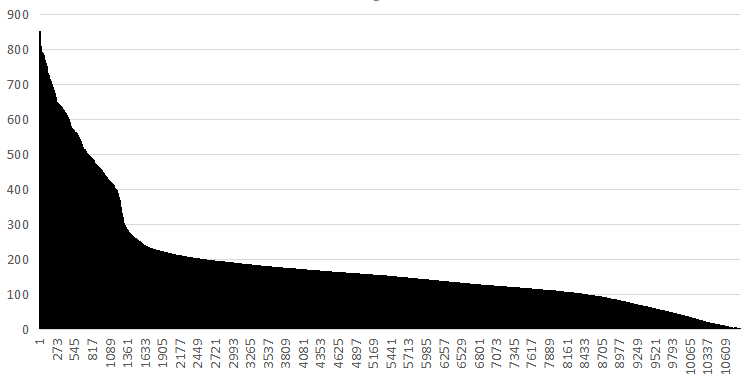
Видно, что на какой-то точке происходит резкое падение весов выравниваний. Возьмём из этой точки значения True Positive, True Negative, False Positive, False Negative для заполнения
таблицы.
E-value находки с выбранным весом - 2,8e-105.
| uniprot+ | uniprot- | |
| hmm+ | 547 | 698 |
| hmm- | 265 | 269 |
На основе имеющихся данных была построена ROC-кривая (выгляит неплохо), представленная на рисунке ниже.
