
|
Учебный сайт Алены Корягиной |

|
Главная |
Oбо мне |
Cеместры |
Cсылки |
ROC-кривая
Белки обычно состоят из одного или нескольких функциональных областей или доменов. Различные комбинации доменов порождают многообразие белков в природе. Нахождение того или иного домена в белке, может предоставить информацию о функциях белка. Для поиска домена в белке используется, так называемый, поиск по профилю. Профиль строится на основании выравнивания достоверных доменов с помощью программы hmm2build и калибруется с помощью программы hmm2calibrate. Далее осуществляется поиск по интересующим последовательностям с помощью программы hmm2search. В итоге мы получаем файл, в котором каждой последовательности соответствует число, - нормализованный вес или Evalue – оценивающее сходство последовательности и домена . Для того чтобы выбрать последовательности, в которых мы будем считать нахождение домена достоверным, необходимо выбрать порог веса, выше значения которого принимаем предсказание домена верным. Для выбора порога необходимо построить ROC-кривую.
Для построения этой кривой нужно провести поиск по профилю на множестве последовательностей с известным ответом. Далее рассчитываются параметры чувствительности и специфичности поиска. Допустим, что в качестве оценки сходства последовательности и домена мы имеем нормализованный вес. Отсортируем таблицу по убыванию веса. Для каждого значения веса предположим, что именно оно является порогом, и посчитаем 4 переменных: 1) количество последовательностей, которое выше этого порога и достоверно содержит искомый домен (переменная TruePositiv), 2) количество последовательностей, которое ниже порога и достоверно не содержит домен (TrueNegative), 3) количество последовательностей, которое выше порога, но на самом деле не содержит домена (FalsePositiv), и 4) количество последовательностей, которое ниже порога, но достоверно содержит домен (FalseNegative). Чувствительность поиска — это доля достоверно предсказанных белков, содержащих домен, от общего количества последовательностей, известно содержащих домен (TP/(TP+FN)), а специфичность — доля достоверно предсказанных белков, не содержащих домен, от общего количества последовательностей, известно не содержащих этот домен (TN/(TN+FP)). Далее строится график зависимости чувствительности от параметра 1 минус специфичность.
В итоге получаем ROC-кривую (пример ROC-кривой см. на рис 1). На этой кривой можно выбрать точку, которой соответствуют достаточно высокие значения чувствительности и специфичности, и по этим значениям найти порог для предсказания. В зависимости от целей поиска эта точка может быть выбрана по разному. Например, если в исследуемых последовательностях нужно найти максимально ВСЕ последовательности, в которых может содержаться домен, то выбирается более высокий параметр специфичности, а если нужно выбрать последовательности, в которых ТОЧНО содержится искомый домен, то выбирается точка, с более высоким значением чувствительности.
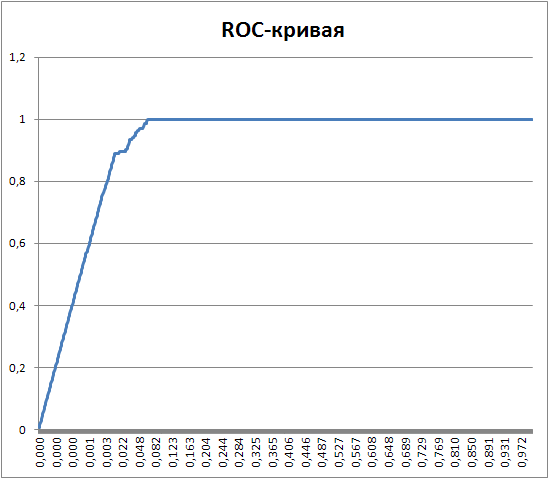
Рис. 1. Пример ROC-кривой. Изображение получено с помощью Excel.
Таким образом, выбрав порог, мы считаем, что последовательности, значение веса которых выше порога, содержат исследуемый домен, и, наоборот, последовательности вес которых ниже порога, не содержат этот домен.
Дата последнего изменения: 11.09.2015