Длины белков
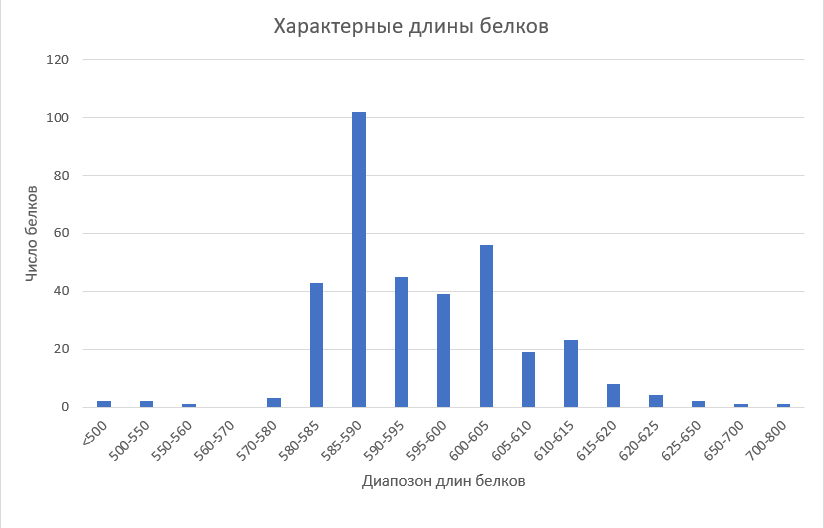
Для длин белков была построена гистограмма. Больше половины белков лежит в диапозоне 580-595, этот диапозон я и буду считать характерной длиной белка.
При помощи сортировки Excel я выбрал 40 белков, принадлежащих организмам из разных семейств, они представлены в файле
Выравнивание выборки белков с двухдоменной архитектурой
Я сделал выравнение выбранных белков в Jalview с помощью Muscle с параметрами по умолчанию, последовательности были скачаны из Uniprot.
N-концевой консервативный блок у меня начинался с первой позиции для всех последовательностей, поэтому я ничего не удалил
После C-концевого домена я удалил 6 неконсервативных позиций (на рисунке они ещё не удалены) Проект Jalview
Построение профиля
Я построил профиль по созданному выравниванию при помощи пакета HMMER. Сначала для построения профиля я использовал команду
hmm2build -g hmm algn.fa
Затем профиль был откалиброван:
hmm2calibrate hmm
Получился файл с откалиброванным профилем выравнивания.
Проверка профиля
Сначала я скачал все последовательности, содержащие один из двух выбранных доменов (домен PF03611). Таких последовательностей оказалось 15067. Программа hmm2search по построенному профилю
искала белки с двухдоменной архитектурой среди белков, содержащих 1 из доменов. Порог на e-value я взял равный 0.1. Поиск проводился при помощи команды:
Далее я сравнивал список находок программы со списком, полученным из Uniprot по двум доменам. Анализ проводился при помощи Python, данные сначала были подготовлены при помощи Excel
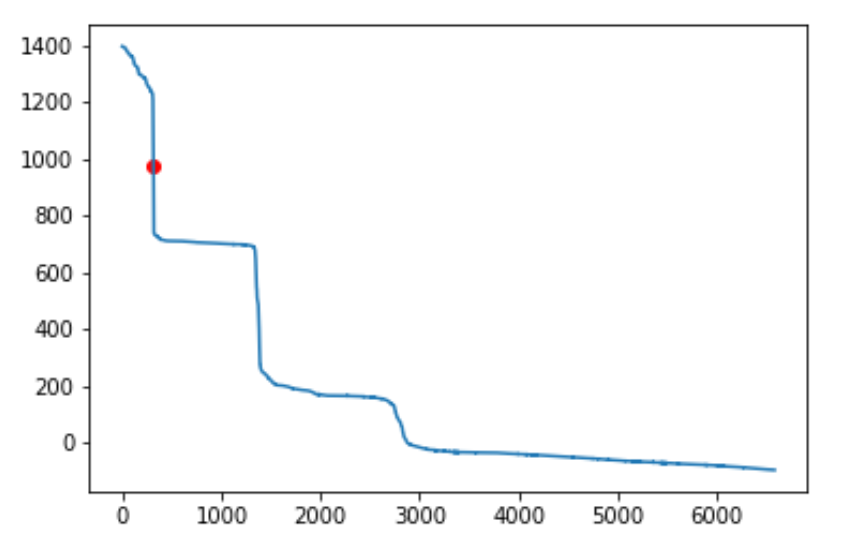
( Таблица с подготовленными данными). Сначала я отсортировал находки по убыванию веса и построил
график полученного распределения.
Определение оптималього порога
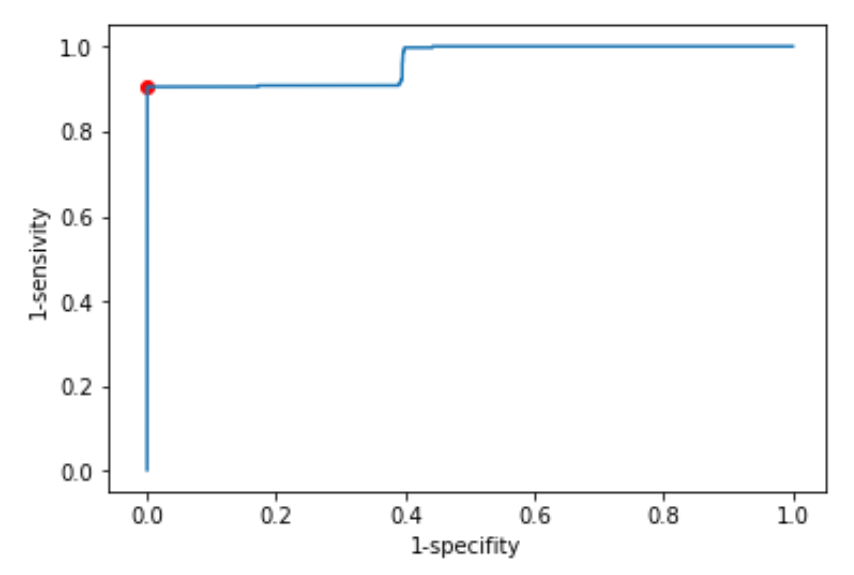
Далее моей задачей было подобрать оптимальное значение веса, при котором бы получались наиболее точные предсказания двудоменной структуры. Для этого находят чувствительсть теста и его мощность
(1-специфичность) для всех возможных значений порога (среди наших предсказаний), по ним была построена ROC-кривая
Далее так же был вычислен параметр F1 для каждого из предсказаний, а затем выбрано значение порога, для которого этот параметр принимает максимальное значение. Найденный
порог оказался равен 978, он соответствует 315 строке в таблице выдачи программы, отсортированной по убыванию веса. (На графиках пороговое значение отмечено красной точкой, он расположен на
'ступеньке' распределения весов и на 'ступеньке' ROC-кривой, что подтверждает правильность выбора порога) Также была построена таблица предсказаний против "истины":
Jupyter-notebook с вычислениями и графиками
 Таблица со списком последовательностей
Таблица со списком последовательностей
 При помощи сортировки Excel я выбрал 40 белков, принадлежащих организмам из разных семейств, они представлены в
При помощи сортировки Excel я выбрал 40 белков, принадлежащих организмам из разных семейств, они представлены в  После C-концевого домена я удалил 6 неконсервативных позиций (на рисунке они ещё не удалены)
После C-концевого домена я удалил 6 неконсервативных позиций (на рисунке они ещё не удалены)
 Далее так же был вычислен параметр F1 для каждого из предсказаний, а затем выбрано значение порога, для которого этот параметр принимает максимальное значение. Найденный
порог оказался равен 978, он соответствует 315 строке в таблице выдачи программы, отсортированной по убыванию веса. (На графиках пороговое значение отмечено красной точкой, он расположен на
'ступеньке' распределения весов и на 'ступеньке' ROC-кривой, что подтверждает правильность выбора порога) Также была построена таблица предсказаний против "истины":
Далее так же был вычислен параметр F1 для каждого из предсказаний, а затем выбрано значение порога, для которого этот параметр принимает максимальное значение. Найденный
порог оказался равен 978, он соответствует 315 строке в таблице выдачи программы, отсортированной по убыванию веса. (На графиках пороговое значение отмечено красной точкой, он расположен на
'ступеньке' распределения весов и на 'ступеньке' ROC-кривой, что подтверждает правильность выбора порога) Также была построена таблица предсказаний против "истины":
