Предсказание генов эукариот
Описание контига NW_014573410 и одного из генов на нем, для которого предсказан альтернативный сплайсинг
 |
Контиг NW_014573410 принадлежит сое культурной (Glycine max), которая имеет следующую таксономию:
Viridiplantae; Streptophyta; Embryophyta; Tracheophyta; Spermatophyta; Magnoliophyta; eudicotyledons; Fabaceae; Phaseoleae; Glycine.
Соя - один из самых важных источников масла и белков. В процессе переработки возможно получение соевого молока и соответствующие продукты питания: творог, сыр. Жареные семена - отличный заменитель кофе. Основное распространение сои - Азия. Масло сои используют также в промышленности: в производстве красок, линолеума, клеенок, инсектицидов и дезинтификаторов.
Размер самого контига равен 367.934 bp (видно из данных GenBank). Чтобы установить количество CDS, экзонов, тРНК и тд, была составлена таблица из .gff-файла, скачанного с сайта NCBI. Готовую таблицу с фильтрами и формулой для подсчета (снизу) можно скачать здесь. Итого в контиге 32 гена и 330 CDS.
На картинке ниже видна мРНК с множеством изоформ:
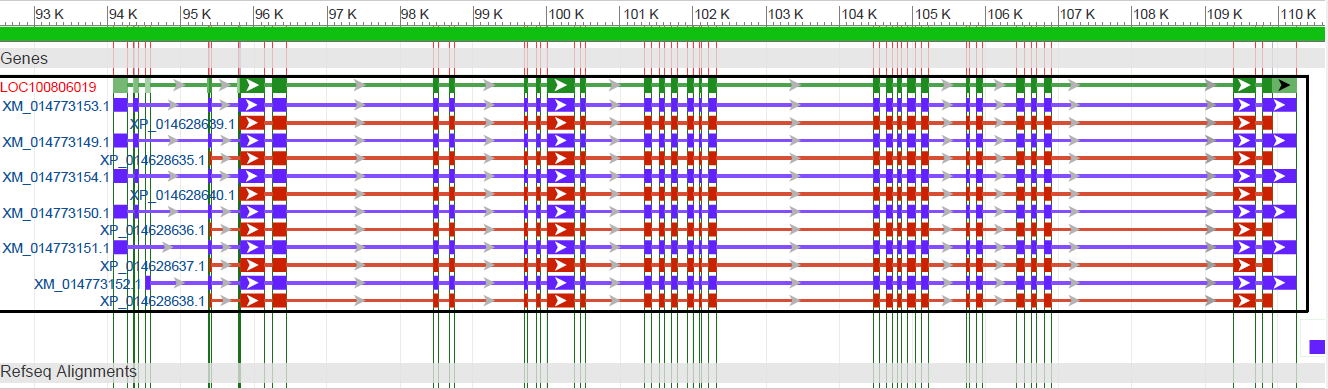
Также неплохо было бы отметить, что этот контиг имеет интересные особенности: в геномном браузере отображены тРНК и нкРНК. На картинках снизу можно посмотреть на них:


Видно, что обе последовательности окрашены в фиолетовый цвет, что свидетельствует о том, что они не кодируют белки, в отличие от полосок синего цвета.
Доп. информация: {ссылка на статью в Nature, в которой как раз частью работы являлось секвенирование сои}
Предсказвние генов и белок-кодирующих областей в NW_014573410
При помощи AUGUSTUS prediction были предсказаны всевозможные гены, экзоны, мРНК и тд. В качестве default организма было выбрано растение Arabidopsis thaliana. Также были изменены два параметра: UTR prediction - да и Alternative transcripts - medium. Это было сделано для того, чтобы мРНК предсказывались вместе с UTR, а количество находок было примерно равно количеству соответствующих в GenBank.
В итоге программа выдает 7 файлов, каждый из которых несет свою информацию:
.gff - предсказание генов в gff-формате;
.gtf - предсказание генов в gtf-формате;
.aa - предсказание генов в 'аминокислотном' fasta-файле;
.codingseq - предсказанные CDS в fasta-формате;
.cdsexons - предсказанные экзоны fasta-формате;
.mrna - предсказанные мРНК (с учетом UTR) в fasta-формате;
.gbrowse - предсказание генов в виде трека для просмотра в программе GBrowse.
| Таблица 1. Сравнение предсказания и данных GenBank | ||
|---|---|---|
| GenBank | AUGUSTUS | |
| Кол-во генов | 32 | 43 |
| Кол-во экзонов | 383 | 407 |
| Кол-во CDS | 330 | 382 |
Данные из таблицы выше были получены из excel-таблицы, которая была конвертирована из файла .gtf.
Для того, чтобы посмотреть, насколько хорошо сработало предсказание, была сделана сравнительная таблица по экзонам (также можно применить этот скрипт).
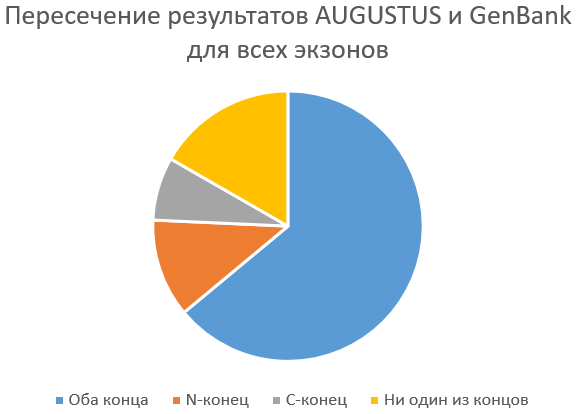
При помощи некоторых команд в Excel, было сделано сравнение результатов. Далее по полученным результатам была построена диаграмма (картинка слева):
 |
 |
Видно, что предсказание сработало в данном случае хорошо, так как количество сопадений на обоих концах 64%, на N-конце - 12%, на С-конце - 7.5%. Этот результат не настолько же хороший, как предсказание генов прокариот (совпадение на обоих концах - 76% - как пример), однако это все же неплохой результат.
Несмотря на это, этот результат вовсе не означает, что AUGUSTUS будет работать так же хорошо и с другими контигами, скэффолдами... На результат играет множество разных факторов, таких как: близкородственность выбранного default организма к исследуемому, выбираемые параметры (к слову мне пришлось несколько раз запускать AUGUSTUS, чтобы получить схожие результаты, так как меняя параметр alternative transcripts, менялось и количество последовательностей в файлах), сложность устройства исследуемой последовательности... К примеру, неизвестно, насколько хорошее было бы предсказание, будь у меня контиг плауна.
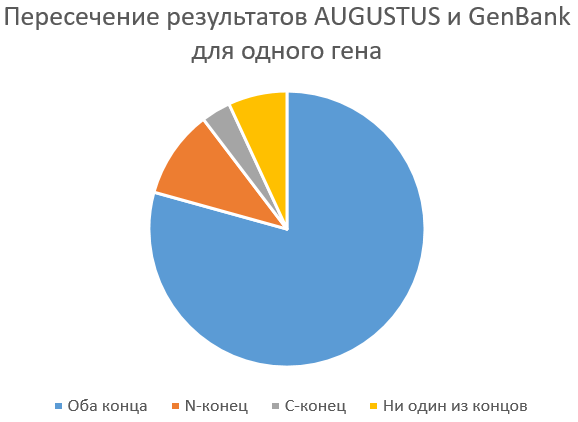
Что же касается выбранного мною в начале практикума гена с множеством изоформ (картинка сверху справа), то его программа предсказала очень хорошо (в таблице выделен серым - совпадение на обоих концах - 79%, на N-конце - 10%, на С-конце - 3%).
⌘
© Emir Radkevich, 2016