Профили
1.
С помощью онлайн конвектора я перевела выравниванеи из fasta формата в msf-формат.
2.
Добавила веса последовательностей в выравнивание:
pfw my_alignment.msf >weighted_alignment.msf
3.
Создала профиль:
pfmake weighted.msf /usr/share/pftools23/blosum62.cmp > my.prf
4.
Создала нормализованный профиль:
pfsearch –C 10 –f my.prf /srv/databases/uniprot/sprot_shuffled.fasta | sort -nr > scores.txt
pfscale scores.txt my.prf > scaled.prf
5.
Нашла в SwissProt всех представителей домена:
pfsearch –C 1.0 –f my.prf /srv/databases/uniprot/sprot.fasta | sort -nr > my.xls
Я поставила порог выдачи 300, и получила 2323 результата.
Полученная таблица-Excel , уже со всеми графиками и расчётами.
Построила график весов находок pfsearch и ROC-кривую.
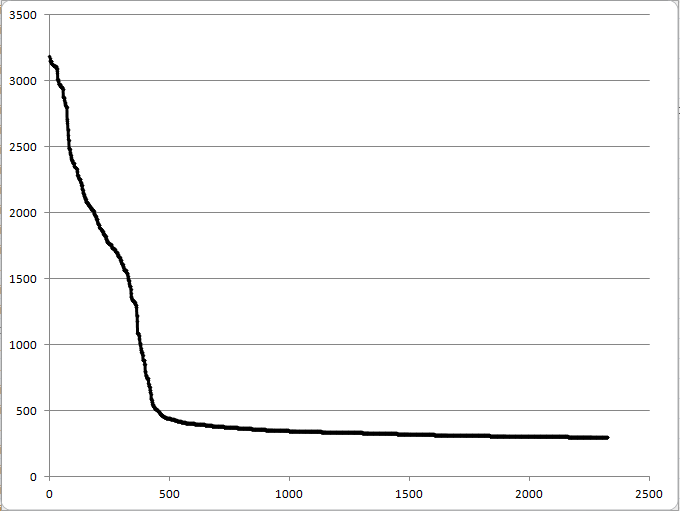 На графике весов видно, что в районе 500 график образует "ступеньку".
Я бы предложила, что порог 450-500. При таком низком пороге я получаю много ошибок второго
рода - принимаю много ложных результатов.
На графике весов видно, что в районе 500 график образует "ступеньку".
Я бы предложила, что порог 450-500. При таком низком пороге я получаю много ошибок второго
рода - принимаю много ложных результатов.
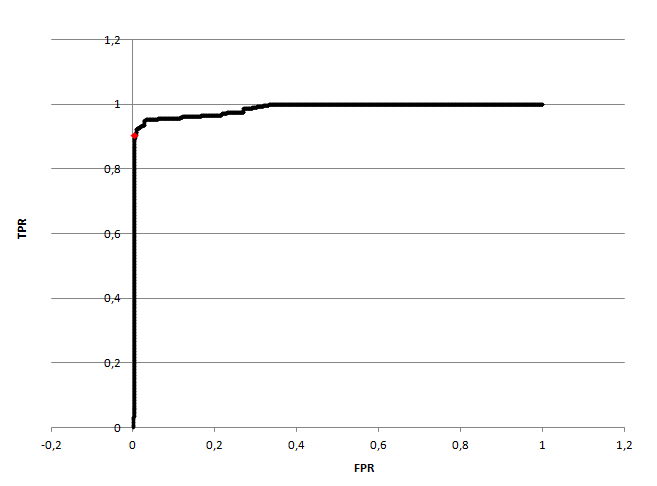 На кривой видно небольшое плато, прежде чем кривая достигает единицы.
Это плато соответствует ситуации, когда чувствительность почти не изменяется, а специфичность падает.
Поэтому я взяла за порог точку до начала плато (отмечена красным). Конечно, в этом случае я отвергаю
довольно много верных результатов, но и принимаю ложных намного меньше. Эта точка соответствует порогу
880. То есть, после построения ROC-кривой я увеличила порог в почти два раза. Возможно, имеет смысл
поискать некую золотую середину, но мне вроде и сравнивать не с чем, чтобы было куда стремиться.
При пороге 880 число ошибок первого рода составляет 41 (1.76% - какой кошмар), второго - 5 (0.39%).
Граница между верными и неверными находками довольно расплывчата, и после принятого мной порога верные
находки встречаются часто по одной, иногда по 3-5 штук, но они разделены большим количеством неверных находок.
Хорошо видно (в таблице), что можно понизить порог до 680, например, и уменьшить число ошибок первого рода на 10,
увеличив число ошибок второго рода на 11 >_< Мне почему-то кажется в данном случае, что ошибки второго рода (принятые неверно)
хуже ошибок первого (непринятых неверно).
На кривой видно небольшое плато, прежде чем кривая достигает единицы.
Это плато соответствует ситуации, когда чувствительность почти не изменяется, а специфичность падает.
Поэтому я взяла за порог точку до начала плато (отмечена красным). Конечно, в этом случае я отвергаю
довольно много верных результатов, но и принимаю ложных намного меньше. Эта точка соответствует порогу
880. То есть, после построения ROC-кривой я увеличила порог в почти два раза. Возможно, имеет смысл
поискать некую золотую середину, но мне вроде и сравнивать не с чем, чтобы было куда стремиться.
При пороге 880 число ошибок первого рода составляет 41 (1.76% - какой кошмар), второго - 5 (0.39%).
Граница между верными и неверными находками довольно расплывчата, и после принятого мной порога верные
находки встречаются часто по одной, иногда по 3-5 штук, но они разделены большим количеством неверных находок.
Хорошо видно (в таблице), что можно понизить порог до 680, например, и уменьшить число ошибок первого рода на 10,
увеличив число ошибок второго рода на 11 >_< Мне почему-то кажется в данном случае, что ошибки второго рода (принятые неверно)
хуже ошибок первого (непринятых неверно).
Анализ результатов поиска по профилю
1. Я разделила выравнивания представителей домена на две группы по доменной архитектуре белков.
2. Построила профили без нормализации для каждой группы.
профиль архитектуры PID+SH2
профиль архитектуры SH3_1+SH2+Pkinase_Tyr
3. Поиск по профилям
pfsearch –C 0 –f p2.prf all_seq.fasta | sort -nr > p2.xls
pfsearch –C 0 –f p3.prf all_seq.fasta | sort -nr > p3.xls
таблица-Excel с вычислениями для архитектуры PID+SH2
таблица-Excel с вычислениями для архитектуры SH3_1+SH2+Pkinase_Tyr
В результаты поиска попали фрагменты представителей архитектур. Поэтому, например, в случае двудоменной архитектуры
сначала, с наибольшим весом, следуют ВСЕ представители данной архитектуры , потом идёт
большой кластер из представителей трёхдоменной архитектуры, а потом встречаются куски
представителей нужной мне архитектуры. Если отмечать их как находки, то кривая получается не
красивой. А если не отмечать их '+', то профиль хороший. В случае первой, я решила не отмечать их, поскольку все
настоящие находки уже представлены в верхней части таблицы, а в случае второй- отметила. А куски последовательностей не
являются истинно верными находками, это не найденная архитектура.
| PID+SH2 |
SH3_1+SH2+Pkinase_Tyr |
график весов находок
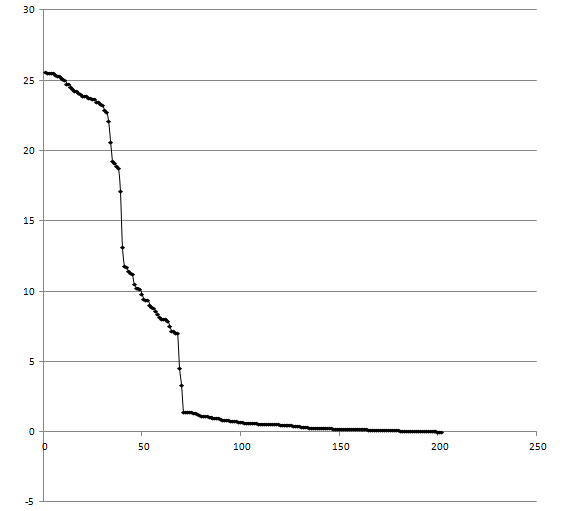
|
график весов находок
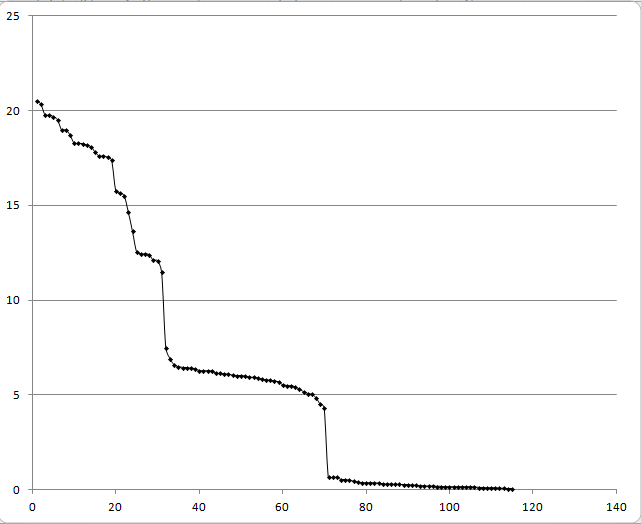
|
ROC-кривая
|
ROC-кривая
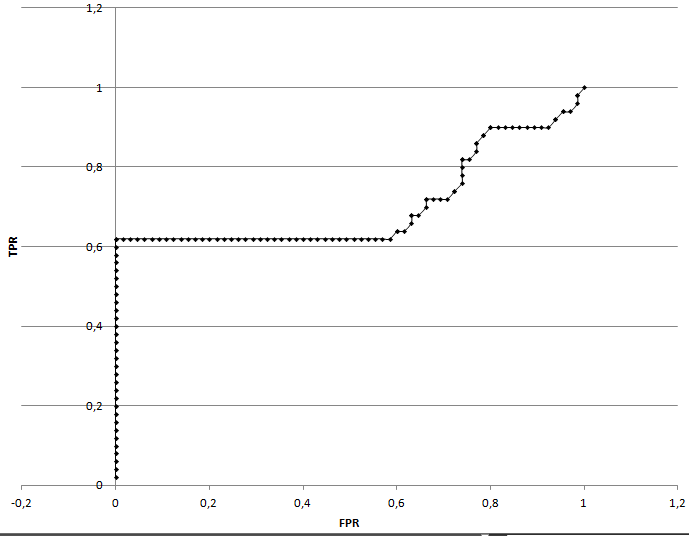
|
Порог для первой последовательности 17, а для второй- 11.
С такими порогами я делаю много ошибок первого рода и ниодной ошибки второго рода.

© Julia Chudakova