Анализ секвенирования по Сэнгеру
В данном упражнении нужно было получить последовательность ДНК на основании данных, полученных из капиллярного секвенатора. Из двух файлов были взяты хроматограммы прямой и обратной цепей. С помощью программы Chromas они были визуализированы и автоматически определена последовательность. Также программа определила концевые нечитаемые участки хроматограммы.
Прямая цепь:
5'-участок: 29 нуклеотидов
3'-участок: >220 нуклеотидов (качество на 3'-конце насколько низкое,
что невозможно посчитать количество нуклеотидов, но
читаемый участок на 84 нуклеотида короче, чем у обратной)
Обратная цепь:
5'-участок: 33
3'-участок: ~180
При схожем размере определенных программой нечитаемых участков, хроматограмма с прочтения прямой цепи имеет намного худшее качество по сравнению с обратной. Так, если на "читаемом" участке обратной цепи нет ни одного неопределенного нуклеотида, то на аналогичном участке прямой их 122. Если для обратной процент шума практически нулевой на большей части длины, то для прямой на лучших участках он составляет порядка 10-20%, а, начиная с середины уже превышает 50%
Полученные последовательности с обеих цепей были выравнены (были взяты участки, чуть большие отобранных программой), результат можно посмотреть в файле. По выравниванию была сделана новая последовательность по следующему алгоритму: 1. Для пары Gap-X, где Х любой символ выбирался Х. 2.Для пары N-X также выбирался Х (в т.ч. если он тоже N). 3. Для пары двух разных нуклеотидов записывалось 'N?'. 4. Для пары одинаковых - сам нуклеотид. Эту задачу осуществлял скрипт, приведенный в ссылке, файл в выравниванием предварительно был несколько преобразован (например, гэпы на концах заменены на N, внутренние гэпы были сначала проверены на хроматограмме на случай ошибочного пропуска или прочтения лишнего нуклеотида). В получившейся последовательности было два неопределенных нуклеотида в начале, которые затем были определены по хроматограмме вручную, и некоторое количество не совпавших нуклеотидов (обозначенных 'N?'), которые, однако, все были однозначно определены по последовательности и хроматограмме обратной цепи. Неверные выводы для них были сделаны программой только для прямой цепи, поэтому их проблемными нуклеотидами не считаем. Также был отдельно рассмотрен небольшой участок, идущий следом за полученной последовательностью в сторону 3'-конца и на основании хроматограмм, удалось добавить еще 5 нуклеотидов. Итоговый вариант последовательности вышел таким (так же файл fasta):
AtTAaGCCATGCATGTGCAAGTGCAAACTTTAACACGGTGAGACCGCGAATGGCTCATTAGATCAGTCTT TGTTCCTTAGACGGAATGTGCTACTTGGATAACTGTGGCAATTCTAGAGCTAATACATGCGAGAAAGCTC CGACCTTCACGGGAAGAGCGCAATTATTAGATCAAGACCAACCGGGCCGAAAGGTCCGAACGGCTGGTGA CTCTGGATAACCTCGGGCTGACCGCATGGCCTCGAGCCGGCGGCGCATCTTTCAAGTGTCTGCCCTATCA ACTTTCGATGGTATGCGACCTGCTTACCATGGTGGTTACGGGTAACGGGGAATCAGGGTTCGATTCCGGA GAGGGAGCATGAGAAACGGCTACCACATCCAAGGAAGGCAGCAGGCGCGCAAATTACCCACTCCTGGCAC AGGGAGGTAGTGACGAGCAATAACGACCCGGGACTCTTTCGAGGCCTCGGGATTGGAATGAGTACAATCT AAAAACTTTCACGAGGAACAATTGGAGGGCAAGTCTGGTGCCAGCAGCCGCGGTAATTCCAGCTCCAATA GCGTATATTAAAGCTGTTGCAGTTAAAAAGCTCGTAGCTGAATCTCGGGTCCAGGCGGGCGGTCCGCCTC GCGGCGAGAACTGCCCGTTTCCTGACCCAACTGCCGGTATTCCCGGGGTGCTCTTGGTTGAGTGTCTCGG GTGGCCGGTGCTTTTACTTTGAAAAAATTAGAGTGCTCAAAGCAGGCTCGGCACGCCTGGATACTATAGC ATGGAATAATGGAATAGGACCTCGGTTCTATTCTGTTGGTCTCCGGAACTCGAGGTAATGATTAAGAGGG ACGGACGGGGGCATTCGTATTGCGGGGCGAGAGGTGAAATTCTTGGACCCTCGCAAGaCGA
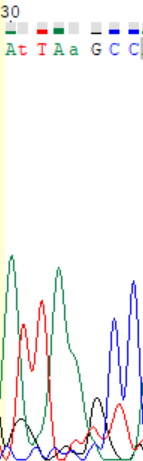
Проблемные нуклеотиды встречаются на 3'- и 5'-концах последовательности, что вполне логично, ведь в этих местах одна из цепей становилась уже абсолютно нечитаемой, во второй же начинали возникать неоднозначные участки. На 5'-конце, восстановленном по хроматограмме прямой цепи, для двух проблемных нуклеотидов можно понять, что это T и А. На 3'-конце, восстановленном по обратной цепи, можно видеть пик аденина там, где программа не смогла определить нуклеотид.
 |
 |
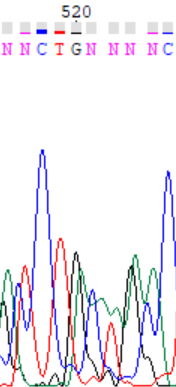
При том, что в консенсусной последовательности проблемных нуклеотидов практически нет, их можно рассмотреть отдельно для прямой цепи. Например, в 520 позиции в ней виден пик гуанина, который программа вполне справедливо интерпретировала, как гуанин. За ним видно несколько подряд идущих пиков аденина, которые программа не смогла интерпретировать. В обратной же цепи нет и намека на гуанин на этом участке (соответствует 539 нуклеотиду на хроматограмме обратной цепи). Либо в данном случае имеет место пара A-G (или на прямой цепи есть выпетливание гуанина, поскольку количество аденинов после него на хроматограмме посчитать сложно), что, на мой взгляд, крайне маловероятно, либо наличие пика является дефектом хроматограммы. Последний вариант кажется более вероятным в виду низкого качества этого участка.
 |
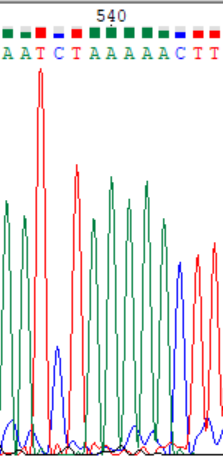 |
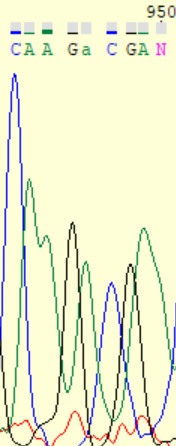
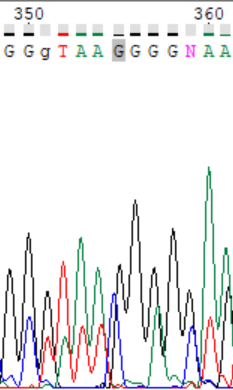
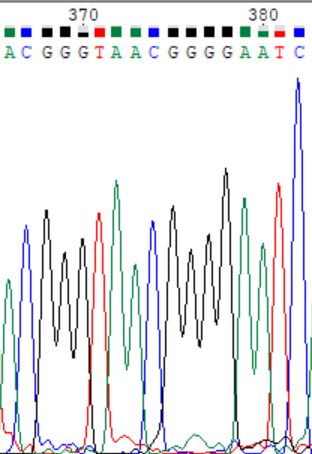
Так же при расшифровке прямой цепи встретился и попуск нуклеотида. После 354 нуклеотида на хроматограмме прямой цепи виден никак не интерпретированный пик цитозинаа, по обратной цепи же отчетливо видно, что в этом месте, действительно стоит цитозин (соответствует 374 нуклеотиду). Так же на приведенном на изображении участке на прямой цепи можно выявить пики гуанина в 531 и 359 позициях, не выявленных программой (первый на изображении уже исправлен). На хроматограмме обратной цепи они распознаны правильно.
 |
 |
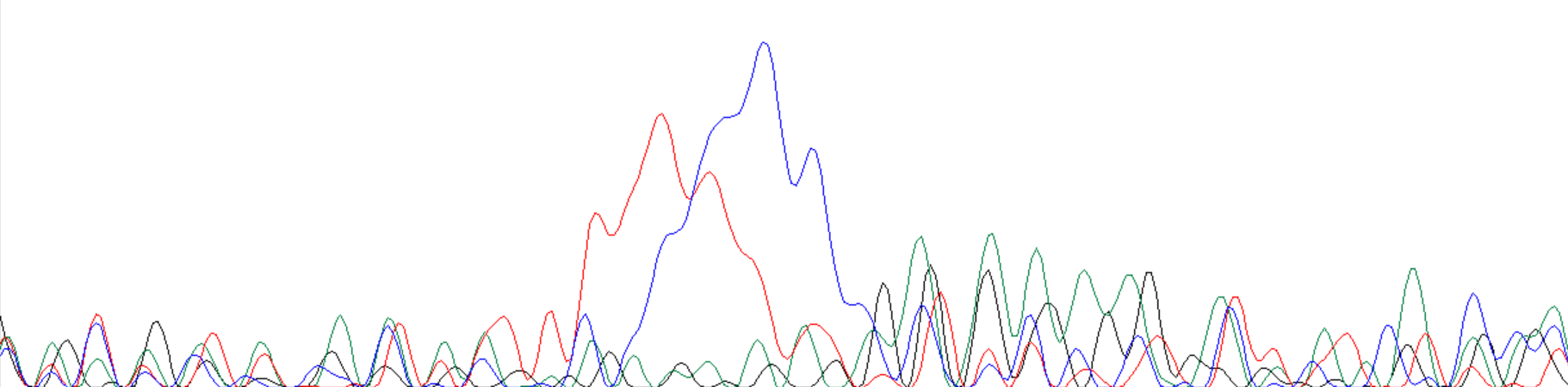
Плохая хроматограмма
На изображении ниже представлен пример нечитаемой хроматограммы: уровень шума на ней таков, что большинство пиков наложены друг на друга, что, скорее всего, свидетельствует о загрязненности материала образцами других ДНК, а также имеется пятно краски, отобразившееся в виде очень высоких и широких пиков.