Я выбрал семейство NADH dehydrogenase (PF00146). Функция очевидна из
названия. Например, входит в состав субъединицы 1 NADH-убихинон редуктазы.
Всего белков 10659, в seed - 370. Подсемейством
были выбраны белки со следующей доменной структурой (Рис. 1.)
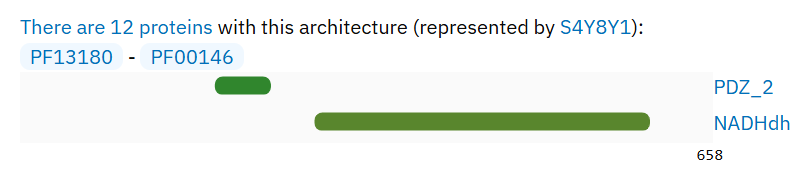
Рис. 1. Доменная архитектура выбранного мной подсемейства
из NADH dehydrogenase
Затем я выровнял эти последовательности (12 штук)
программой muscle с параметрами по-умолчанию в Jalview, а
из выравнивания оставил только участок с доменами.
При помощи этого выравнивания был построен HMM профиль с помощью программы hmm2build,
а впоследствии откалиброван hmm2calibrate. Затем были скачены
полные последовательности белков из данного семейства,
и с помощью программы hmm2search проведен поиск по только что построенному
профилю (результат). Я не представляю какой порог будет разумным,
так как при любом пороге результаты такие себе.
Но теоретически я бы счел разумным такой уровень порога = x,
при котором находки были наиболее близки к желаемому идеальному
результату (найти только белки моего подсемейства). В данном случае это порог = 7.
Если опустить порог ниже, то число находок выше порога не из подсемейства
увеличится.
Вот для него таблица численных характеристик:
Таблица. 1. Численные характеристики выделения подсемейства профилем
|
TRUE |
FALSE |
| Positive |
1 |
1 |
| Negative |
0 |
0 |
Думаю, профиль оценить нельзя. Возможно, выборка для поиска была не та.
Я скачал 10 тыс. поледовательностей со страницы семейства со вкладки full.
Но в любом случае практика была полезная!
Все необходимые файлы лежат на kodomo в директории ~/term4/pr11