Создание и описание HMM-профиля для поиска двудоменной структуры в белках
Выбор объекта
В данной работе предлагается выбрать эволюционный домен с известной двудоменной структурой. Для поиска использовалась база данных Pfam. Я остановил свой выбор на домене с интересным названием - Carot_N (PF09150)
Этот домен ответственен за связывание белком своего каротиноидного хромофора и, что интересно, является единственным доменом с такой функцией у растворимых белков (остальные аналогичные белки являются мембранными). [1]
Основные характеристики записи данного домена в Pfam приведены ниже:
| ID | Name | seed | full | Uniprot | Avg. length | Avg. identity | Avg. coverage | Длина HMM-профиля |
|---|---|---|---|---|---|---|---|---|
| PF09150 | Carot_N | 49 | 49 | 1143 | 145.6 | 40 | 67.1 | 151 |
Как видно из таблицы, данный домен по большинству параметров удовлетворяет рекомендациям к выбору домена для выполнения задания. Перейдем к выбору архитектуры.
Для данного домена известно всего 3 архитектуры (link), причем в большинстве белков (204/347) он был единственным присутствующим доменом. Однако в 131 белке в направлении к С-концу от данного домена присутствовал еще один домен - NTF-2 (Nuclear transport factor 2 domain) с ID PF02136. Именно это сочетание было выбрано в качестве изучаемой двудоменной архитектуры.
Подготовка данных к работе
Значительная часть данных и результатов собрана в таблице
Последовательности белков с исследуемой архитектурой были извлечены из Pfam по их ID с помощью скрипта. С полученным файлом можно ознакомиться по ссылке, идентификаторы белков с архитектурой собраны в отдельный файл.

В таблице Excel (приложена выше) была создана таблица, где для каждого белка, содержащего домен Carot_N, было указано, содержит ли он нужную архитектуру и был ли включен в выборку для построения HMM-профиля (подробнее ниже). Более того, в столбце 4 указаны длины белков, по которым был построен barplot.
По диаграмме заметно, что все белки хорошо можно поделить на 3 группы по их длине. На самом деле, как было установлено позже, эти 3 группы соответствуют доменным архитектурам, указанным в Pfam (самые длинные белки, как раз, имеют нужную нам двухдоменную архитектуру).
Эти последовательности в дальнейшем загружались в Jalview и выравнивались с помощью алгоритма Muscle с настройками по умолчанию. Выравнивание доступно по ссылке.
Следующим этапом являлось редактирование выравнивания. Для этого избыточно похожие последовательности были удалены с помощью порога на Redundancy в 83 ед, а края, не входящие в двудоменною архитектуру удалялись мной вручную. Я удалил области 1-14 позицию и 311-... (по левой и правой границам, указанных в Pfam для доменов Carot_N и NTF-2 соответственно). Полученное выравнивание можно увидеть по ссылке.
Отредактированное выравнивание передавалось программам пакета HMMER, установленном на kodomo. Для получения данных использовались следующие команды:
- hmm2build HMM car_ali.fa - этой командой мы создали HMM профиль для поиска этой архитектуры
- hmm2calibrate HMM - этой командой мы откалибровали профиль, рассчитав коэффициенты пересчета весов
- hmm2search -E 0.1 --cpu 1 HMM Carot_N.fasta > HMM_res.txt - этой командой мы осуществили поиск архитектуры во всех белках, содержащих домен Carot_N.(файл)
На выходе был получен файл HMM_res.txt.
Сам HMM-профиль можно увидеть по ссылке. Его длина составляет 285
Анализ HMM-профиля
Для анализа профиля с помощью Excel и скрипта на Python был создан лист Result (в таблице, которая приложена выше), где для каждого белка с доменом указан score и E-value. Для дальнейшей работы с помощью Excel-формул были рассчитаны specificity и 1 - sensitivity для нашего "теста" (тест, в данном случае, это HMM-профиль, позволяющий предсказать, содержит ли белок нужную архитектуру).
По полученным значениям были построены 3 важных графика:
График 1: score для всех белков, отсортированные по убыванию. Эта диаграмма называется Score decrease и показывает, как распределены находки HMM-профиля по их score (довольно логично :) ). Уже на данном этапе можно заметить, что на уровне score <= 600 наблюдается резкое падение, которое в дальнейшем, проявится не очень красивыми результатами.

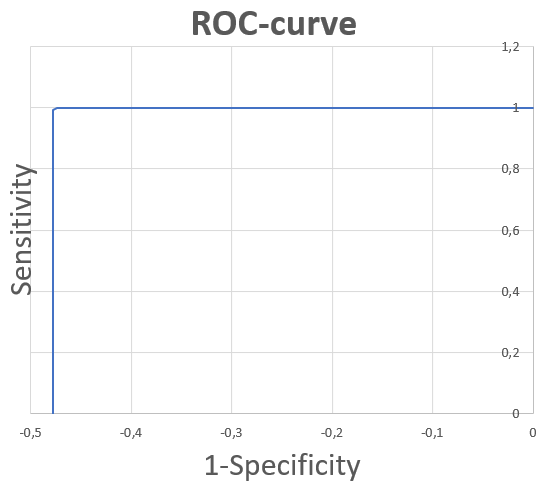
График 2: ROC-кривая, построенная по созданному HMM-профилю. К сожалению, построенная ROC-кривая имеет очень резкий скачок, объясняемый значительной разницей в score находок, содержащий выбранную архитектуру или нет. По такой ROC-кривой трудно подобрать порог, чтобы достичь нужных sensitivity и specificity.
График 3: График функции F1, что и ожидалось после неудачной ROC-кривой, также имеет разрыв в области, соответствующей скачку score между белками с архитектурой и без нее. Глобальный минимум этой функции, что логично, находится в областях наибольших весов находок (чем выше вес, тем более вероятно, что она содержит архитектуру, по которой строился HMM-профиль), однако, возможно, в области разрыва мог находиться локальный минимум, соответствующий переходу весов между находками с архитектурой и без нее.
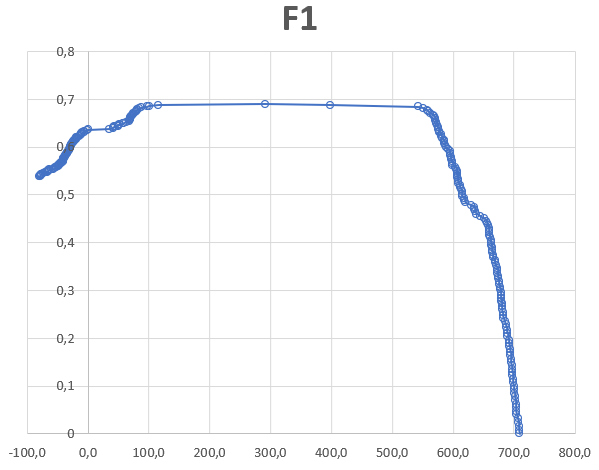
Подводя итоги, хочу сказать, что скорее всего мной была совершена ошибка при выборе объекта исследования. Я предполагаю, что хоть белки с доменом Carot_N и имеют identity только 40%, но сами домные архитектуры крайне консервативны и мало отличаются у разных организмов. Возможно, что наиболее эффективным порогом для такого случая будет значение score, соответствующее наихудшей находке с выбранной архитектурой. По таблице этот score составляет 398 ед.
На самом деле, было довольно сложно найти подходящий под рекомендуемые параметры домен, тем более входящий в состав нескольких архитектур. :(
References
- Orange carotenoid N-terminal domain // Wikipedia