Практикум 8. Сигналы и мотивы
1. В рамках этого практикума для описания мотива в белках паттерном была выбрана мнемоника Swiss-prot - DSBA, соответствующая тиол-дисульфидной оксидоредуктазе. Она необходима для образования дисульфидных связей в некоторых периплазматических белках бактерий. Действует путём переноса своей дисульфидной связи на другие белки, восстанавливаясь в процессе этого. DsbA окисляется заново за счёт DsbB.
Из базе Uniprot были выбраны и скачаны 9 последовательностей бактериальных белков с данной мнемоникой: DSBA_ECOLI, DSBA_VIBCH, DSBA_SALEN, DSBA_LEGPN, DSBA_SHIFL, DSBA_BUCAI, DSBA_PSEAB, DSBA_AZOVI, DSBA_YERPE. Последовательности выровнены программой Muscle c параметрами по умолчанию, выравнивание визуализировано в программе Jalview. В качестве мотива был выбран участок 56-69 выравнивания (рис. 1)

2. Программа fuzzpro
По файлу со всеми бактериальными белками из базы Swiss-Prot (файл /P/y24/term4/bacteria-sw.fasta) был проведён поиск белков, содержащих составленный по выравниванию мотив 'E-[FL]-F-[SW]-[FY]-[YGF]-C-P-[HYW]-C-Y'
fuzzpro -sequence /P/y24/term4/bacteria-sw.fasta -pattern 'E-[FL]-F-[SW]-[FY]-[YGF]-C-P-[HYW]-C-Y' -outfile fuzzppro_dsba.out
С помощью команды grep нашлось 19 белков, и все они с нужной мнемоникой - DBSA. Количество предполагаемых найденных находок в файле с бактериальными белками было найдено с помощью следующей команды и составило 26.
grep -c '|DSBA_' /P/y24/term4/bacteria-sw.fasta
Значит количество находок, которые должны были найтись, но не нашлись (ложноотрицательные результаты) составляет 26 - 19 = 7.
Неплохо, но постараюсь улучшить паттерн, заменив [YGF] и [HYW] на x, то есть ослабив его. Теперь программа fuzzpro уловила еще один подходящий белок (всего 20 белков), не добавив ложноположительных результатов.Ещё ради любопытства я решила сократить количество аминокислот в паттерне, включив только самые консерватвные позиции, например, 'C-P-[HYW]-C'. Научные источники указывают на то, что этот мотив является консервативных для семейства оксиредуктаз, так как оответствует цистеиновому узлу, связанному с координацией металлов в активном центре фермента. Поэтому при поиске программой fuzzpro нашлось аж 720 белков, включая все 26 белков с нужной мнемоникой. Таким образом, меняя силу паттерна, мы можем улучшать количество нужных находок, но в то же время увеличивать долю ложноположительных результатов. Поиск белков таким способом проблематичен, так как программа никак не учитывает частоты аминокислот в паттерне.
Поиск программами MEME и MAST
С помощью программы MEME были найдены мотивы исследуемых белков. Была использована команда:
meme dsba.fasta -protein -mod oops -nmotifs 3 -minw 8 -maxw 15 -o memedir
Пояснения:
-protein — подаем на вход белковые последовательности;
-mod oops — "One Occurrence Per Sequence" — по одному представителю мотива на последовательность;
-nmotifs 3 — искать до трех различных мотивов;
-minw 8 и -maxw 15 — минимальная длина мотива 8 аминокислот, максимальная длина мотива — 15.
В выходе из программы мы создали папку memedir, в которой находится файл выдачи в формате html. Ссылка на html-файл. В верхней части показаны 3 мотива, которые MEME нашла в файле с выравненными последовательностями dsba.fasta. Три найденных мотива находятся во всех девяти исследуемых белках.
Далее проведем поиск по всей базе данных с помощью программы MAST, подавая на вход html-файл выдачи программы MEME:
mast meme.html /P/y24/term4/bacteria-sw.fasta -o mastout
Ссылка на html-файл выдачи программы MAST.. Суммарно было найдено 49 последовательностей с E-value меньше 10. Абсолютное большинство надежных находок (с очень маленьким E-value) составляли исследуемые белки DSBA. Также были найдены белки с мнемониками DSBL, NHAA*, YME3 и другие.
Поиск последовательности Шайна-Дальгарно в геноме
В первом семестре я работала с геномом бактерии Brucella canis (идентификатор сборки генома: GCF_000018525.1), с файлами этого же генома будем работать в этом практикуме.
Будем искать последовательность Шайна — Дальгарно в геноме моего прокариота. Последовательность Шайна — Дальгарно (ПШД)— это участок мРНК прокариот, который служит сигналом для связывания рибосомы перед началом синтеза белка. Она комплементарно взаимодействует с 16S рРНК, физически ориентируя рибосому на правильном расстоянии от старт-кодона для точной инициации трансляции. Считается, что ПШД консервативна и консенсусом является последовательность из 6 нуклеотидов, её и выбрали в качестве паттерна - AGGAGG. Последовательности Шайна-Дальгарно найдены в геноме бактерии при помощи следующей команды:
fuzznuc ~/term1/genome/GCF_000018525.1_ASM1852v1_genomic.fna. -pattern 'A-G-G-A-G-G' -complement Y -outfile SD.fuzznuc
Опции:
~/term1/genome/GCF_000018525.1_ASM1852v1_genomic.fna - путь к файлу с геномом
-pattern 'A-G-G-A-G-G' - паттерн
-complement Y - поиск и на прямой цепи, и на обратной
-outfile SD.fuzznuc - выходной файл.
В результате всего было обнаружено 1010 находок (622 - на I хромосоме, 388 - на II, как на +, так и на - цепях).
Найдем число находок, ожидаемое по случайным причинам. GC-состав генома был определён в 1 семестре - 57.3%. Отсюда частоты нуклеотидов: p(G)=p(C)=0.3, p(A)=p(T)=0.2. Тогда вероятность появления паттерна AGGAGG:
P(AGGAGG) = p(A)*p(G)*p(G)*p(A)*p(G)*p(G) = 3.24*10^-4
Тогда ожидаемое число находок: E = L*P*2 = 2147, где L- длина генома в нуклеотидах (3 312 769), а 2 - учет прямой и обратной цепей.
Для определения статистической значимости различия применим z-тест. Он показывает, на сколько стандартных отклонений реальное число находок (O) удалено от ожидаемого среднего (E). Будем считать, что случайная величина (число находок последовательности Шайна-Дальгарно) распределена по Пуассону (длина генома большая, вероятность паттерна маленькая). Тогда Z-статистика имеет следующий вид:
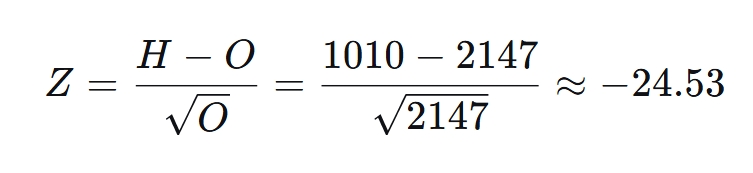
В результате получаем, что |z| = 24.5 > 1.96, а значит, нулевая гипотеза о случайном распределении паттерна в геноме отвергается. Так как z-статистика оказалась отрицательной, можно сделать вывод, что распространенность последовательности Шайна-Дальгарно значительно ниже ожидаемого количества. Это может быть связано с тем, что в регуляторных зонах перед генами ПШД представляет собой усредненный паттерн, получаемый из-за того, что консенсус может быть модифицирован для более тонкой регуляции трансляции.