Для выполнения этого задания я выбрала геном короновируса воробья
(AC: NC_016992) Sparrow coronavirus HKU17
С
NCBI я взяла upstream последовательности генов поздних белков
и orf1ab, и занесла данные в табл.1. Upstream я выбирала таким образом, чтобы было вероятно найти в ней CS, т.е. от -100н и до -1н от начала гена.
После этого я создала fasta-файл с последовательностям upstream (команды:
'seqret -sequence Sparrow_coronavirusHKU17_cg.fasta -sbegin * -send * -out *.fasta' и ' cat *.fasta > pr6.fasta')
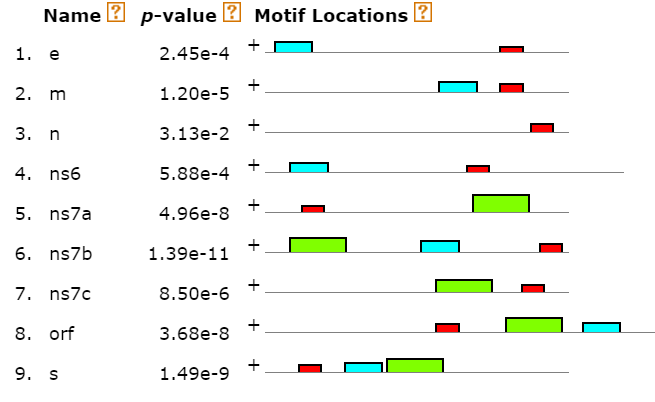
Далее с помощью сервиса
MEME я осуществила поиск мотивов в полученных последовательностям. С первого раза у меня
получилось найти мотив, который присутствовал в каждой upstream последовательности, и c e-value 1.4e-001. Длина этого мотифа была равна 8, но два последних
нуклеотида были не очень достоверные. Вывод MEME можно посмотреть
здесь.
Из
статьи я узнала, что для нескольких короновирусов (в основном птичьих), в число которых входит и выбранный мной
была найдена "putative transcription regulatory sequence of
ACACCA". Это придало мне уверенности для того, чтобы сказать, что найденный мной мотив - это
как раз то, что я искала.
После этого я добавила на 5'-конце некоторых последовательностей 100н, чтобы посмотреть, не найдется ли мотивов с большей степенью консервативности. Выдача MEME
здесь.
Но это не привело к значительному улучшению результатов, хотя длина мотива увеличилась до 11.
Подводя итог, могу сказать, что, видимо, в найденном мотиве 5'-GACGCCCTGCY-3' находится CS 5'-ACACCAA-3'