

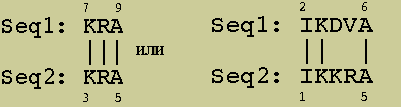
вес оптимального выравнивания-2
Вес субоптимального выравнивания-4
Вес оптимального выравнивания-6
Глобальное и локальное вырывнивания аимнокислотных последовательностей
Работа с программами пакета EMBOSS: needle, water и matcher
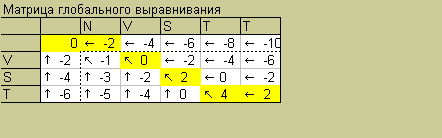
Матрица переходов
Последовательности, использованные для построения выравниваний:
для глобального - TIKDVAKRA
для локального - IKKRA
При построении матриц я использовал следующие параметры:
вес совпадения: 2
вес замены: -1
штраф за делецию: -2
|
|
|
|
|
|
|
вес оптимального выравнивания-2 |
Вес субоптимального выравнивания-4 |
Поиск участков локальной гомологии
Программа matcher выравнивала последовательности белка PurR (AC=P15039) и искуственно созданную последовательность из двух кусков первой:
1-й участок - остатки с 6 по 15
2-й участок - остатки с 323 по 332
Локальные выравнивания, найденные программой matcher
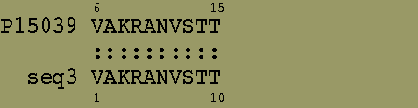
|
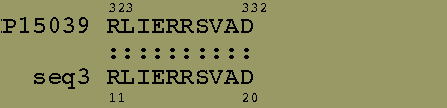
|
Влияние параметров на глобальное выравнивание
Параметры, на которых были построены выравнивания:
матрица-EBLOSUM62, gapopen=10 gapextend=1
матрица-EBLOSUM62, gapopen=1 gapextend=1
матрица-EBLOSUM80, gapopen=1 gapextend=1
матрица-EBLOSUM40, gapopen=1 gapextend=1

|

|

|

|
Параметры выравнивания:
процент идентичных остатков-растет от BLOSUM40 к BLOSUM80
процент остатков со схожими свойствами-то же.
Вес ведет себя непонятно (нерегулярен), ибо зависит и от сходящихся аминокислот, и от числа\длины гэпов.
Два наиболее сильно различающихся локальных выравнивания:
У них различаются как матрица замен, так и параметр штрафа за открытие гэпа. Очевидно, что в первом выравнивании меньше гэпов (точнее, он только один) и ниже процент сходства по сравнению со вторым выравниванием. Причина, очевидно, в том, что при работе с матрицей замен BLOSUM на основе белков с высокой степенью гомологии программа ищет выравнивание с как можно большим числом совпадающих остатков, меньше обращая внимание на гэпы (особенно хорошо это заметно на примере запроса с gapopen=1 - гэпов получается несколько, что ,как мне кажется, не совсем корректно. При gapopen=10 гэп получился один, но большой, что логично, т. к. при большем числе гэпов сильно страдает вес. Но в этом случае в выравнивании меньше схожих остатков.