
|
|
|
||||||||||||||||||
|
Задание 1. Предсказание генов X5 c помощью AUGUSTUS.
Для предсказания генов я выбрала запись unplaced_628.fasta из сборки генома X5(с помощью infoseq я посмотрела длины контигов, этот содержит 26327 нуклеотидов). Чтобы запустить AUGUSTUS, необходимо было выбрать "наиболее сходный" с данным контигом вид из списка организмов, на которых уже произведено обучение сервиса. Поэтому я запустила blast с алгоритмом blastx и определила, с продуктами генов каких организмов наиболее сходны продукты генов моего контига. Смотреть стоило именно по белкам, так как последовательности белков более консервативны, чем нуклеотидные, и в моем контиге могут быть некодирующие участки, последовательности которых сильно варьируются. Поиск бласт выдал много гипотетических и предсказанных белков растений, из подтвержденных был белок vacuolar serine protease Isp6 из Schizosaccharomyces japonicus. 
Я испытывала некоторые сомнения, и поэтому запустила еще и алгорим blastn. Он выдал наибольшее сходство с последовательностью Schizosaccharomyces octosporus yFS286 vacuolar serine protease Isp6. 
Поэтому я использовала Schizosaccharomyces pombe для работы с AUGUSTUS. Архив с результатом работы программы содержал 5 файлов: 1)augustus.aa - аминокислотные последовательности белков, полученные с найденных генов(в моем случае 16) 2)augustus.cdsexons - нуклеотидные последовательности экзонов 3)augustus.codingseq - полные транслируемые последоваетльности 4)augustus.gbrowse - информация о найденных генах и участких структуры в формате, воспринимаемом геномным браузером GBrowse 5)augustus.gff - предсказание генов в виде таблицы. Даны координаты разных участков генов(экзонов и интронов, старт- и стопкодонов), последовательности гена и его продукта. 5)augustus.gtf - вся та же информация, только в виде единой табдицы и без последовательностей В табличку excel я собрала данные об экзон-интронной структуре генов(ее html вариант) Проверка предсказаний с помощью blastp Для проверки предсказания я выбрала пять генов: g1, g2, g3, g4, g5. Поиск blastp я ограничивала таксоном Fungi. G1: поиск алгоритмом blastp выдал достаточно большое сходство с той самой сериновой протеазой Schizosaccharomyces japonicus, по которой я определяла организм для настроек: 
Низкое e-value, query cover 88% и ident 40% - параметры для белкового выравнивания неплохие. Посмотрим на само выравнивание. 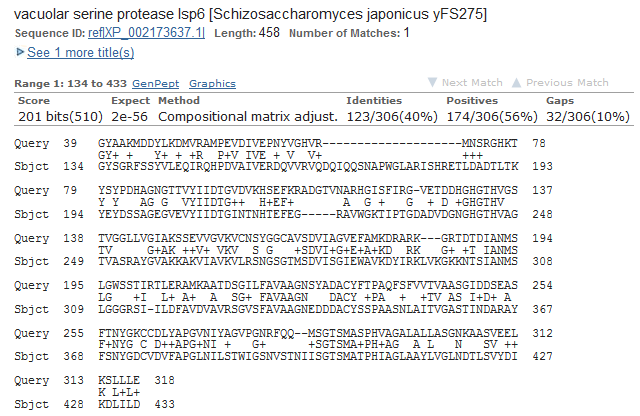 Видно, что в первой строчке содержится длинная гэповая область, и номера первых аминокислот отлтчаются почти на 100. Из этого можно заключить, что, хотя в целом ген предсказан верно, возможна ошибка в предсказании экзонов(augustus предсказал 2, а на ncbi указан только 1). G2: результат поиска гомологов этого белка стал для меня неожиданностью, наилучшей находкой опять оказалась эта сериновая протеаза. 
Возможность подобной находки объяснятеся тем, что g1 находится на обратной цепи, а g2 на прямой. E-value тут выше, чем для g1, но выравнивания не содержат гэпов. 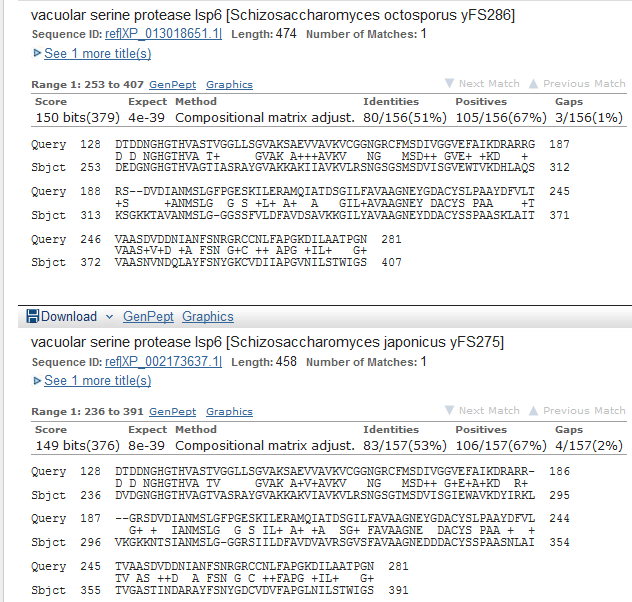 С экзон-интронной структурой AUGUSTUS ошибся - выдал 3 экзона, а на самом деле в этом гене сериновой протеазы экзон только один. G3: находки blast по этому гену были хуже предыдущих, но все равно приемлемые. Лучшая - целлюлаза или экспансин у Rasamsonia emersonii. Предсказание гена можно засчитать, количество предсказанных экзонов совпадает с указанным в Gene.
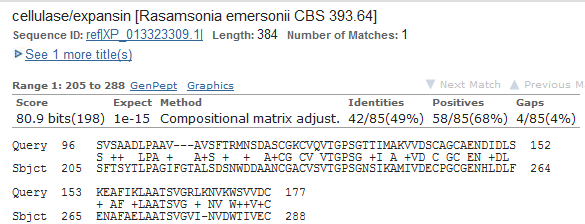 G4: g4 - самый короткий из выбранных мною для проверки генов. Для него E-value лучшей находки был 6е-16, довольно высокое значение. Query cover - 47%. Сама лучшая находка - субъединица процессомного комплекса, участвующая в формировании 18S рРНК у Lachancea lanzarotensis. Находку засчитываю, в базе Gene данных о экзон-интронной структуре не нашла. G5: с g5 AUGUSTUS, похоже, ошибся. В выдаче присутствовали только гипотетические белки, только у двух лучших находок e-value был меньше 0.001. Query cover лучшей находки был 28. 
Поэтому делаю вывод, что достоверных гомологов у этого гена нет.
Задание 2. Сравнение аннотаций Refseq и AUGUSTUS одного гена человека Для сравнения аннотаций я выбрала относительно короткий ген щелочной фосфатазы ALPL. Он закодирован в первой хромосоме, на участке с 21508982 по 21578412 нуклеотиды, на прямой цепи. 
Скриншот окна геномного браузера Сравнение аннотаций привожу в таблице excel. Видно, что AUGUSTUS плохо справился с предсказанием экзон-интронной структуры данного гена, он выделил в три раза больше экзонов, чем содержится в аннотации refSeq. |
|||||||||||||||||||
© Шугаева Т.Е. 2015