Домены и профили
Задание 2
Для выполнения задания был выбран домен изомеразы фосфоглюкозы. Он встречается в основном у бактерий, но также есть у эукариот, образует 54 различные доменные архитектуры, три из них встречаются более чем в 100 последовательностях. Вся информация об доменах, составляющих выбранную архитектуру, представлена в таблице 1.
| ID домена | AC домена | Название | Число последовательностей среди бактерий |
|---|---|---|---|
| PGI | PF00342 | Phosphoglucose isomerase | 7458 |
| TAL_FSA | PF00923 | Transaldolase/Fructose-6-phosphate aldolase | 8060 |

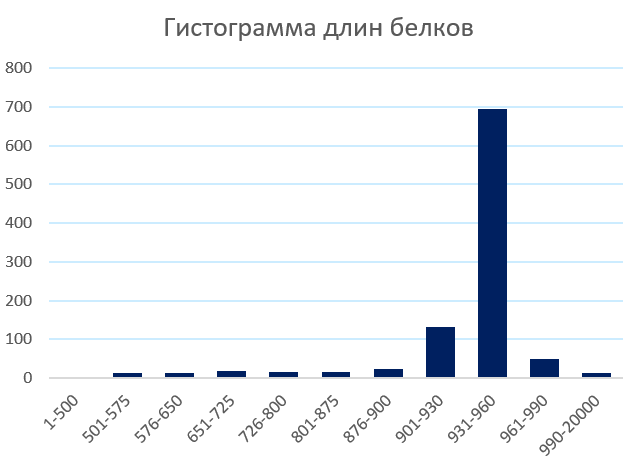
Так как в Uniprot представлена более свежая информация, то там был произведен поиск по бактериям, содержащим эти два домена. Всего было найдено 1003 последовательности (197 в Pfam0), которые я скачала в формате Excel. Сразу же были убраны все белки, содержащие больше этих двух доменов (их было 17). По длине оставшихся белков была построена гистограмма, ее можно увидеть на рисунке 2. По ней видно, чтобы характерная длина белков с такими доменами лежит между 931 и 960 аминокислотными остатками. Из белков такой длины из разных отделов и семейств было выбрано 64 белка, напротив них стоит YES в колонке Selected. Таблицу со всеми данными и гистограммой можно скачать по ссылке.
Задание 3. Проверка по HMM профилю
В выборку я брала белки длиной от 931 до 960 нуклеотидов из различных отделов (большинство из Proteobacteria, по одному-два представителя из Actinobacteria, Bacteroidetes, Ignavibacteriae, Chloroflexi, Cyanobacteria). Было взято по четыре пять представителя отдела Proteobacteria, семейств Acetobacteraceae, Bradyrhizobiaceae, Hyphomicrobiaceae. Всего было выбрано 64 белка (выбранные белки отмечены словом "yes" в колонке Selected в таблице выше). После загрузки их AC в Uniprot, были скачаны их последовательности и выравнены программой muscle:
muscle -in pr9prot.fasta -out pr9_align.fasta
Скачать файл с выравниванием белков.
Далее в программе Jalview были удалены 14 нуклеотидов до N-концевого консервативного блока и 7 нуклеотидов после С-концевого консервативного блока. На рисунке 3 можно увидеть фрагмент получившегося выравнивания после вырезания нуклеотидов.

Скачать файл с выравниванием белков после ревизии.
Из Uniprota были скачаны белки, содержащие домен изомеразы фосфоглюкозы (их оказалось 34740, для второго домена это число было немного больше). Скачать файл с последовательностями, содержащими этот домен. Для построения профиля HMM белков были использованы следующие команды:
hmm2build -g pr9_build pr9_alseq.fa для получения профиля по выравниванию.
hmm2calibrate pr9_build для откалибровки профиля. Скачать файл с откалиброванным профилем белков.
hmm2search --domE 0.1 pr9_build pr9_allseq.fasta > pr9_result3.txt для поиска среди всех белков, содержащих первый домен, тех, которые содержат данную доменную архитектуру с порогом E-value 0.1
В Excel был импортирована нужная таблица из получившегося файла (его можно скачать здесь) и там же производились все вычисления.
Скачать таблицу со всеми вычислениями и графиками.
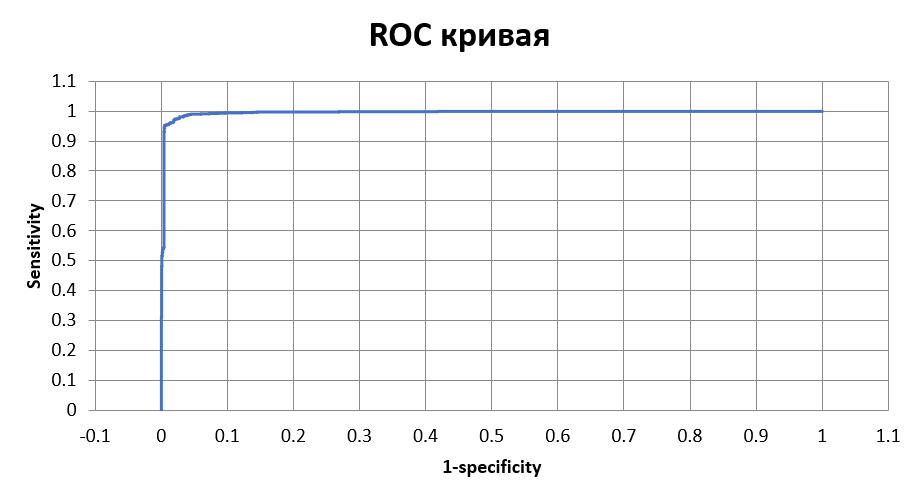
Чувствительность теста равняется 0,9615, а специфичность - 0,9852.
| True | False | |
|---|---|---|
| prof+ | 948 | 46 |
| prof- | 40 | 2998 |