Реконструкция доменной структуры. Задание 9.
1. Выбор домена, архитектур, таксонов.
Семейство: Secretin_N
Код домена: PF03958
Ссылка на Pfam:
http://pfam.sanger.ac.uk//family/PF03958#tabview=tab0
Краткое описание: короткий домен бактериальной секреторной системы II/III типа, иногда образует повторы.
Страница с архитектурами:
http://pfam.sanger.ac.uk//family/PF03958#tabview=tab1
Для рассмотрения выбраны две следующие архитектуры (N - без TraK, и T - с доменом TraK, в обозначениях далее):

Количество последовательностей для архитектур: N - 1278, T - 24.
Описание соседнего домена Secretin. Тоже является некоторым секреторным белком системы II/III типа.
Описание домена TraK. Белок, обнаруженный пока только у трех представителей Gammaproteobacteria Escherichia coli, Salmonella typhi и Salmonella typhimurium.
Необходим для формирования пили, но точная его роль неизвестна.
Для анализа был выбран класс Gammaproteobacteria (филума Proteobacteria надцарства Bacteria), так как архтектура T описана только в трех
его порядках (Enterobacteriales, Pseudomonadales, Vibrionales). Из представителей T изначально были взяты все последовательности,
из N - несколько представителей из тех же порядков и некоторых других. Такой выбор должен был помочь при анализе дерева,
но плохо сказаться на качестве выравнивания.
Файл Excel с полными данными о ходе работы по выбору последовательностей и первоначально выбранными последовательностями:
Книга Excel
2. Работа с выравниванием.
После получения вырванивания последовательностей домена Secretin_N из выбранных архитектур, названия сразу же были изменены:
[Код архитектуры]_[Порядок]_[Род]
Вначале было проведено простейшее редактирование вырванивания: удаление C- и N- концов, удаление ошибочных и очень похожих последовательностей.
У выравнивание есть некоторые особенности, представляющие трудности. Домен Secretin_N содержит две вставки. Одна приходится на
участок поворота (начало с позиции 35 выравнивания ниже), на выравнивании частично обозначен маленькими буквами, что говорит о том, что эта последовательность неконсервативна в домене.
Другая начинается с позиции 13 выравнивания, приходится на третий нуклеотид альфа-спирали.
К сожалению, 3D-структуры описаны только для Secretin_N из
белка C9R226_AGGAD, представителя архитектуры N далеких Pasteurellales (от представителей T).
Его структура плохо выравнивается с архитекутрой T, во многом из-за делеций в тех участках, где Secretin_N из T довольно консервативен.
Все похожие на C9R226_AGGAD последовательности
(с протяженными делециями) были исключены из выравнивания.
Ниже приведено выравнивание, в котором C9R226_AGGAD стоит особняком и нужен только для демонстрации 3D-структуры (2Y3M) и вставок:
Выравнивание в JalView
3. Филогенетическое дерево и возможный путь эволюции.
Деревья были построены с помощью алгоритма NJ и проверкой с помощью бутстрепа. Для анализа использовался встроенный сервис MEGA.
NJ - алгоритм, не подразумевающий молекулярные часы. Гипотеза молекулярных часов действена для последовательностей с равномерной скоростью замен, для которых снижено давление
естественного отбора (или, по крайней мере, равномерно во времени и по всем позициям). В моем же случае предполагается несколько дупликаций, которые могли послужить толчком для ускорения эволюции и отбора;
более того, в домене присутствует очень много конесрвативных позиций, к которым неприменима гипотеза молекулярных часов - значит, и такие методы реконструкции, как UPGMA.
Использование NJ влечет за собой то, что отсутствует укоренение. Укоренение можно произвести, зная реальную филогению организмов, из которых взяты последовательности.
В моем случае Pseudomonadaceae должны быть выделены в аутгруппу.
Для анализа было получено два выравнивания: одно с оставлеными вставками
(alignment.fasta),
другое - с удаленными
(alignment_with_gaps.fasta).
Вставки являются очень неконсервативными последовательностями. Для сравнения случаев с ними и без них работа проведена для двух выравниваний.
Полученное NJ дерево для последовательностей со вставками, алгоритм NJ:
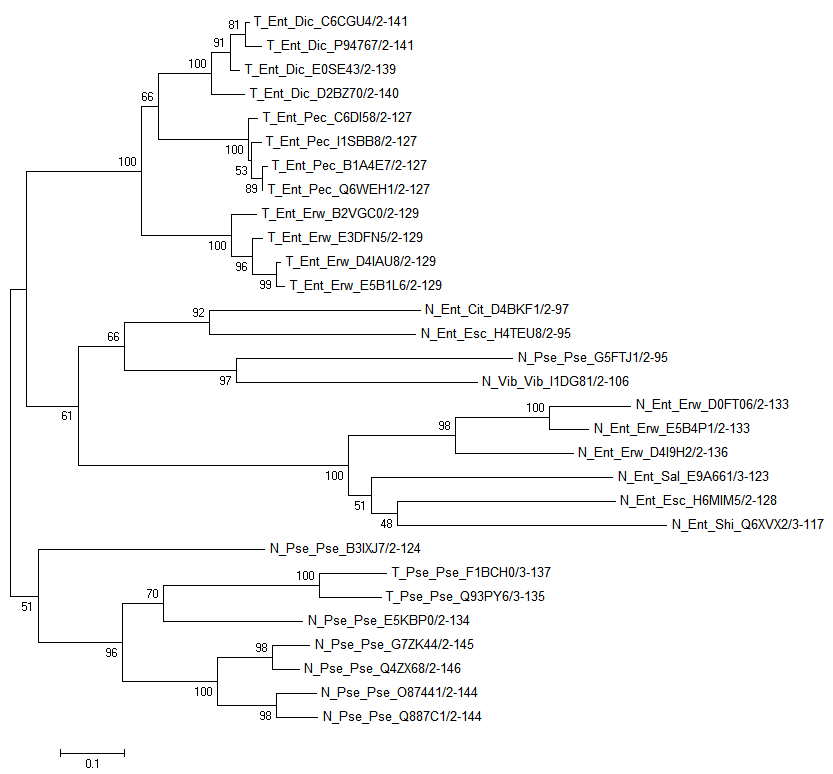
Укоренение произведено вручную так, чтобы последовательности Pseudomonadaceae выделялись в аутгруппу. Действительно, видно, что Secretin_N из T
гораздо ближе к N для группы Pseudomonadaceae. Для других групп, домен из T архитектуры четко выделяется в отдельное поддерево.
Ясно, что первоначальной архитектурой была N, без домена TraK.
Дерево свидетельствует о том, что домен TraK оказался около Secretin_N и Secretin у общего предка всех последовательностей выборки, возможно и всех Gammaproteobacteria.
Pseudomonadaceae является более древней группой, раньше ответвившейся от линии предка, из-за чего Secretin_N в архитектуре T всё ещё похож на таковой в
архитектуре N.
Полученное дерево NJ для последовательностей с удаленными вставками:
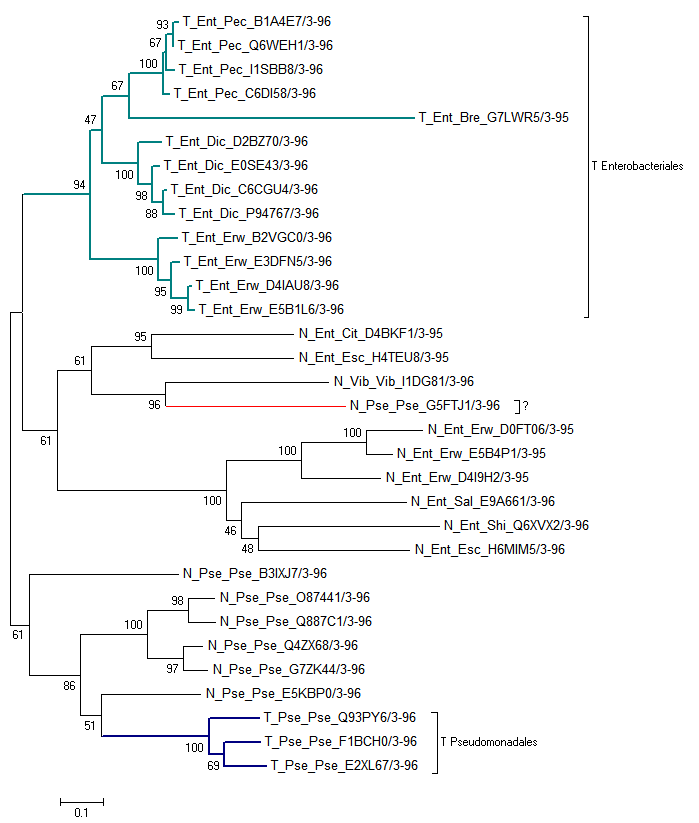
При удалении неконсервативных участков обнаруживается длинная ветвь среди T. Это указывает на быструю эволюцию домена этой ветви, которая до этого нивелировалась весом
различий между неконсервативными вставками.
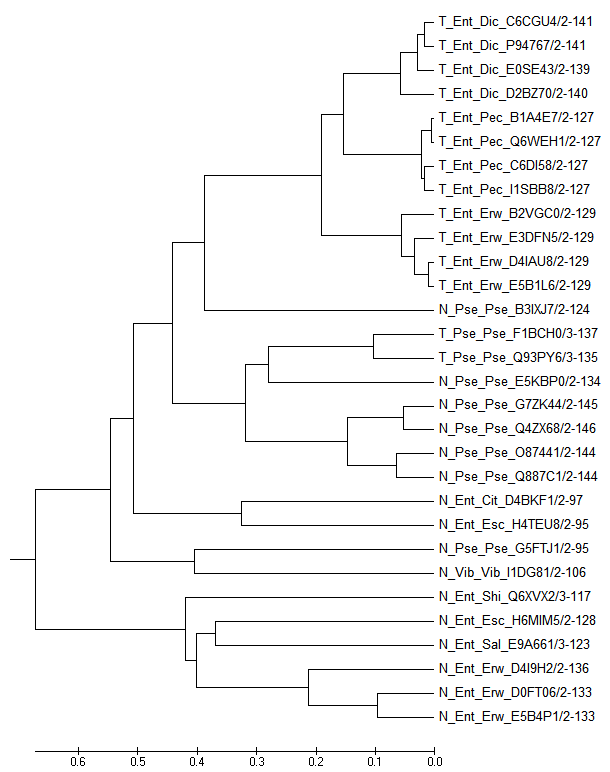
Дерево UPGMA без удаленных вставок демонстрирует укоренение, отличное от выбранного мною
(похоже на укоренение в среднюю точку методом средней связи NJ):
Ошибочное присоединение листа UPGMA для выравнивания с удаленными вставками:
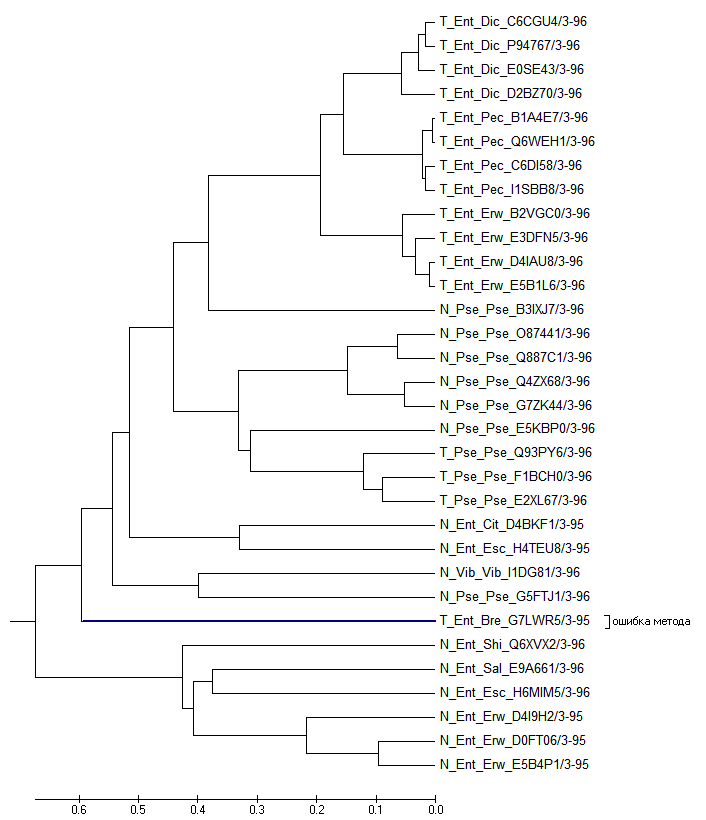
Причина такой ошибки - быстрая эволюция последовательности этой ветви. В итоге
UPGMA в данном случае неверно помещает длинную ветвь ближе к корню.
4. Поиск с помощью профиля.
Задание поиска с помощью профиля было выполнено для двух выравниваний: со вставками и без них (см. пред. задания). Фактически, больший смысл должен иметь поиск без удаления вставок, так как
в профиле будут предусмотрены неконсервативные участки с возможными гэпами. С другой стороны, эти участки должны увеличивать количество случайных незначащих находок.
За TP считались находки только совпадения длиной более 60 нуклеотидов (понятно, что короткие находки длиной 10-20 нт не являются последовательностями доменов, а случайные находки).
При этом из числа FN и TN не вычитались такие короткие последовательности (правильно ли это?).
Итак, результаты.
Ссылка на файл Excel. (Предупреждение! Большой файл. Представлены результаты поиска по выравниванию со вставками (gaps) и без них)
Гистограмма нормализованных весов находок, отсортированных по убыванию веса (порог -С 5.5):
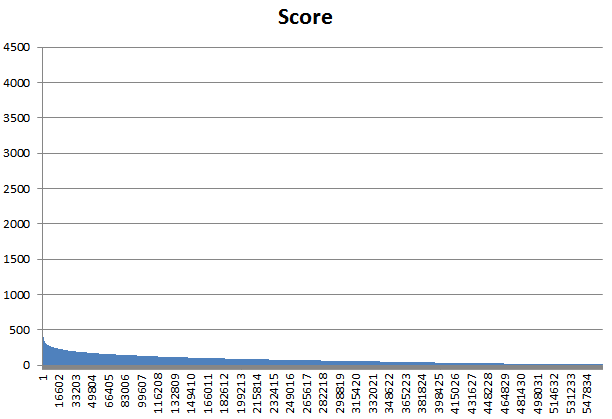
Видно, что ступени выделить очень трудно. Первым нескольким находкам соответствуют веса более 2000 - самая важная ступень.
Ради интереса была построена гистограмма длин находок:
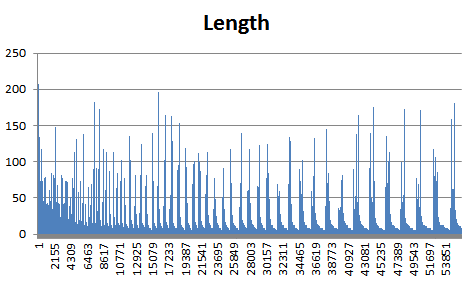
Я не могу объяснить, почему находки с короткой длиной оказываются с большиими весами, почему наблюдается некая периодичность в гитограмме. В идеале с самым большим весом должны
быть правильные длинные находки, а с малым весом - короткие находки.
Построенная ROC-кривая приведена ниже. По оси Y отложена сенситивность, равная TPR - True Positive Rate, TP/(TP+FP). По оси X отложена величина 1-специфичность, равная
FPR - False Positive Rate, FN/(FN+TN). TP - количество правильно найденных доменов, TN - количество правильно отброшенных доменов,
FP - количество неправильно найденных доменов, FN - количество неправильно отброшенных доменов (т.е. на самом деле доменами являются).
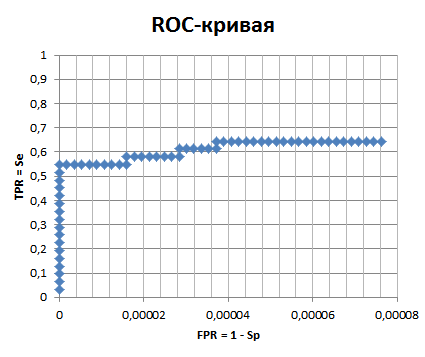
Примечание: кривая построена не полностью, так как значений слишком много из-за большого количества находок.
Для случая с оставленными вставками кривая лучше в том смысле, что перегиб отсекает
В случае с удаленными вставками пренебречь придется более чем находок
Порог для первого случая: , надено TP против FN и 0 TN
Для второго всё ещё хуже: , найдено TP против FN и TN
4. Анализ профилей.
Задание было выполнено как для выравнивания со вставками, так и для выравнивания без них.
Разбиение выравнивания было выбрано по доменной архитектуре. Профиль создавался по последовательности домена Secretin_N в архитектуре T (содержащей TraK), так
как на вид выравнивание только их последовательностей выглядит более консервативным (даже последовательности вставок одинаковой длины и довольно похожи).
Для поиска был получен fasta-файл с последовательностями всех белков, из которых взяты домены в общем выравнивании. (Для случая со вставками и без них количества последовательностей немного
отличались, но это было учтено в ходе работы.)
Поиск производиился с нулевым порогом, так что все находки попали в выдачу pfsearch. Этап нормализации был пропущен.
Результирующий файл:
Ссылка на файл Excel.
Результаты. Все результаты были лучше для поиска по выравниванию без удаленных вставок, чего и следовало ожидать: в реальном домене
присутствуют вставки и их необходимо учитывать. Далее рассмотрены только результаты для такого поиска, хотя в файле .xlsx можно найти все результаты.
Гистограмма весов находок, отсортированных по убыванию веса:
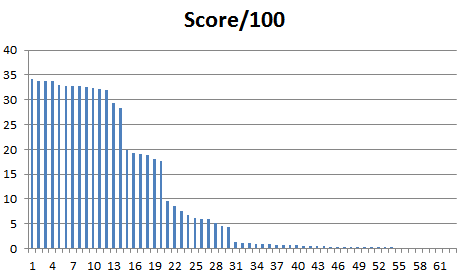
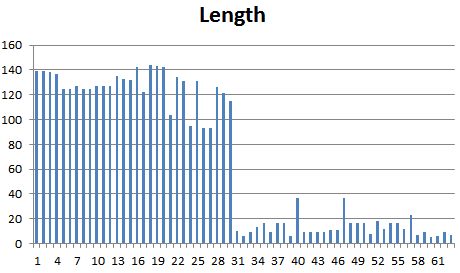
Можно выделить две четких ступени веса. Как видно далее, находки второй половины гистограммы (с низким весом) - очень короткой длины.
Гистограмма длин находок:
Построенная ROC-кривая "идеальная", точка перегиба отсекает 100% верных находок:
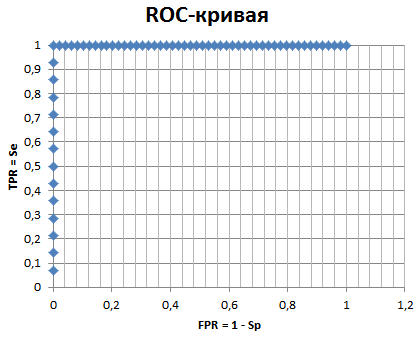
Вывод. Удалось построить профиль, по которому можно отличить последовательность домена Secretin_N из архитектуры с TraK от таковой из архитектуры только с Secretin и Secretin_N.
Главная страница
Страница семестра
© Галицына Александра, 2012