Предсказание генов прокариот
Сравнение предсказаний генов в GenBank и по данным Prodigal для плазмиды CP014885
В качестве исходной плазмиды была дана плазмида CP014885 (к слову сиквенс опубликован в марте 16 года в Германии, далее об этом будет появляться инфа), принадлежащая Lactobacillus backii, бактерии, портящей пиво! В этой статье (август 16 года, Германия) описывается неплохой эксперимент по выяснению причины такой неприятной (для человека) способности, расти в пиве. Было выяснено, что в плазмиде L. backii закодирован путь биосинтеза жирных кислот, которые позволяют расти на данном субстрате, как и бактерии Pediococcus damnosus. Собственно, в выданной плазмиде есть гены, которые причастны к этому.
Размер же самой плазмиды небольшой - 52.539 bp. В ней закодированы 61 CDS и столько же генов.
P.S.: теперь понятно, почему этой бактерией занялись именно немцы :)
Первым шагом стало получение предсказания Prodigal и сравнение его с данными из GenBank.
Чтобы получить предсказание необходимо было использовать следующую команду (для Windows):
prodigal.windows.exe -i cp.fasta -p meta -f sco -o cp.sco, где cp.fasta - это fasta-файл с плазмидой, а -p meta - дополнительный параметр, использующий иной алгоритм (в help говорится что этот флажок следует использовать, если длина последовательности меньше 50.000bp). После этого с помощью команды seqret в putty (seqret embl:CP014885 -feature -osformat2 gff cp.gff) была получена gff-таблица feature, которая в последующем бралась за основу.
{файл с предсказанием}
{файл с gff-таблицей}
Собственно вторым шагом стало составление нескольких команд в Excel (можно посмотреть на них в итоговой таблице) для сравнения предсказания и данных в GenBank. На диаграмме ниже показано пересечение результатов (совпадение обоих концов - 77%, совпадение N-конца - 12%, С-конца - 5%):
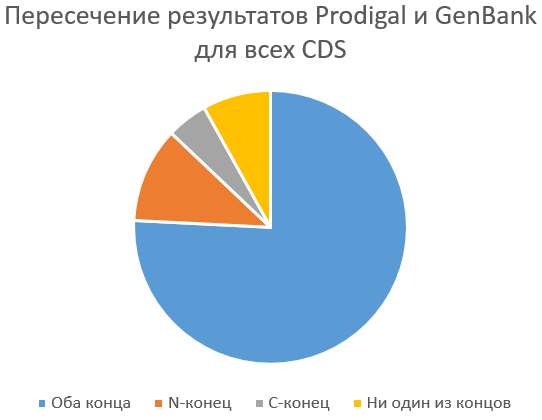
Видно, что предсказание хорошее: более трёх четвертей совпадение абсолютное, полных несовпадений - всего 8%. Также, чтобы посмотреть на конкретные ошибки предсказания, я воспользовался геномным браузером. Ниже показаны на мой взгляд интересные случаи:
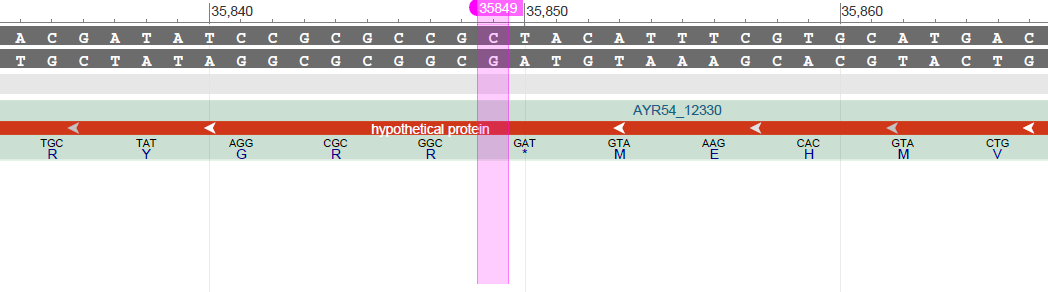
Первый случай не самый интересный, но зато хорошо иллюстрирует возможный проскок кодона. Это может возникать из-за того, что кодоны обладают в геноме 'разной силой', поэтому во время трансляции не происходит терминации, и элонгация продолжается. Кроме того в этой статье описываются возможные замены стоп-кодонов на кодоны пирролизина и селеноцистеина (селеноцистеин будет использоваться дальше). Для E.coli показано, что кодон UAG может заменяться на пирролизин, к сожалению для Lactobacillus такого не показано, однако не исключено, что такое может быть. Если это так, то становится понятно, почему программа неправильно предсказала конец белка.
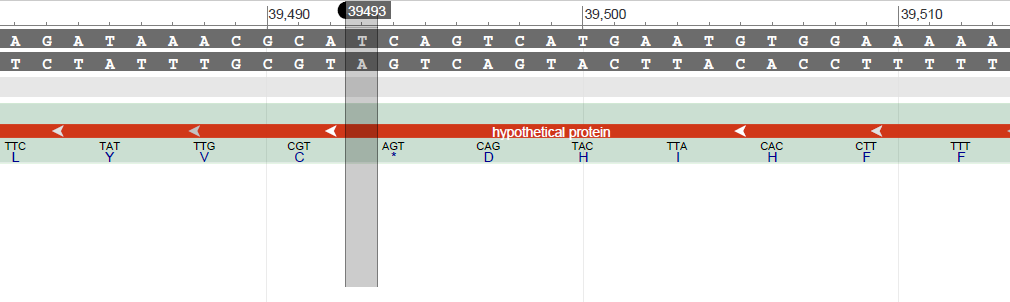
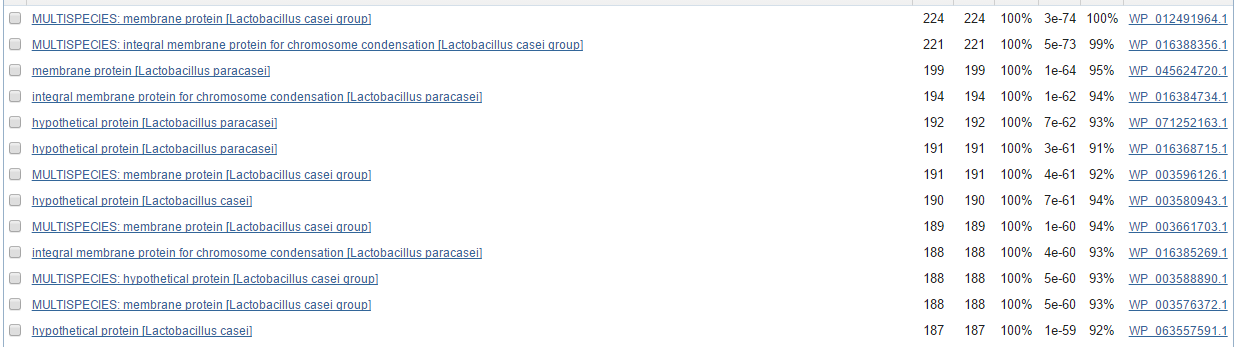
Второй случай показался мне очень интересным из-за последовательности стоп-кодона (UGA). По этой ссылке можно прочитать интересную информацию о том, что для бактерий рода Lactobacillus доказано, что UGA может выступать не только стоп-кодоном, но и кодоном для селеноцистеина. Белок, изображенный сверху, вообще-то говоря является frameshift/pseudo белком (ссылка). Функция этого белка на самом деле известна - интегральный мембранный протеин, который аггрегирует хромосомы (проверено с помощью blastp). Собственно исходя из вышенаписанного можно понять, почему prodigal ошибся, приняв UGA за стоп-кодон.
P.S.: также не исключен и проскок кодона.
Сравнение предсказаний генов в базе данных GenBank и по данным Prodigal для геномной записи
Для этого задания был написан скрипт, так как объём данных, которые нужно посчитать возрос довольно сильно, по сравнению с прошлым заданием.
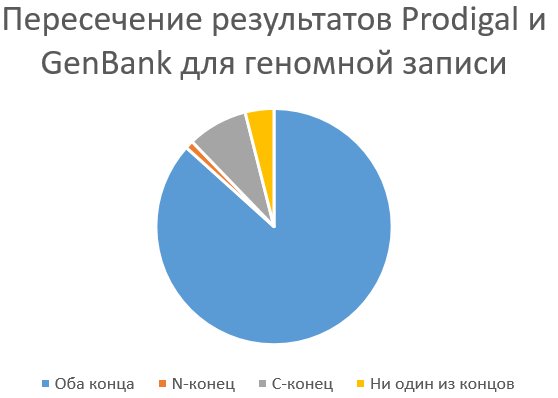
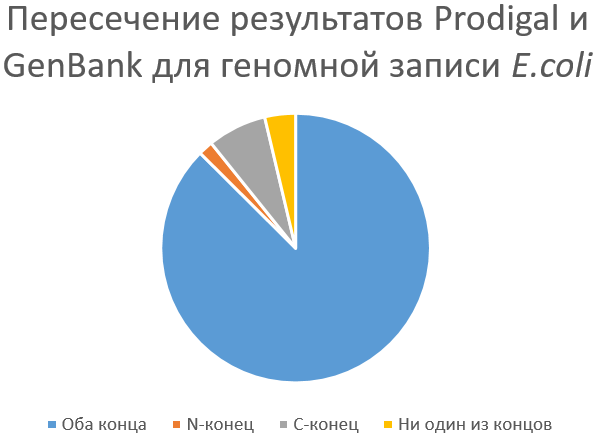
Сравнивались два файла: gff-таблица и sco-файл. В итоге после получения конкретных процентов была построена диаграмма (картинка слева):
 |
 |
Видно, что предсказание хорошее: оба конца совпадают - 86.67%, только N-конец - 1.12%, только С-конец - 8.27%, ничего не совпадает - 3.94%. Объяснить такую хорошую выдачу легко: размер геномной записи невелик, следовательно вероятность ошибится у Prodigal ниже, кроме того Leuconostoc citreum KM20 изучена хуже, чем E.coli, поэтому границы многих генов не подтверждены экспериментально, значит никаких серьёзных исправлений относительно предсказания не было.
На картинке сверху справа видно пересечение для E.coli: оба конца совпадают - 87.46%, только N-конец - 1.72%, только С-конец - 7.1%, ничего не совпадает - 3.7%. Как и для моей бактерии, для E.coli программа сработала очень хорошо, видимо из-за того, что множество границ генов действительно уже подтверждено экспериментально, так как это модельный организм и множество неочевидных стартов и стопов уже известны и предсказываемы программой (возможно перед 'мокрой' работой в Prodigal уже прогонялась эта бактерия и каким-то образом ошибки, допущенные ей уже испправлены).
⌘
© Emir Radkevich, 2016