IC. FIMO.
- Задание 1. Информационное содержание.
Я работал с последовательностями из 2 варианта задания. Для них посчитал встречаемость букв в кажной позиции, вычислил частоту. Excel - файл с построенной матрицей PWM без псевдокаунтеров и матрицей IC (Рисунок 1). Организм - D. rerio. GC - состав - 38.6%. Формула для расчета Information content: наблюдаемая частота буквы в позиции i * логарифм по основанию 2 отношения наблюдаемой частоты к ожидаемой.
IC(b,j) = f(b,j)*log2[f(b,j)/p(b)].
Далее с помощью сервиса webLOGO получил изображение (Рисунок 2), где выделены буквы, которые, скорее всего, не являются случайными и несут какой-то сигнал. В соответствующих колонках суммарное IC также велико. В первой позиции LOGO не показывает буквы, так как в этой колонке мало информации, исходя из данного выравнивания. Суммарное информационное содержание 10,445.

Рисунок 1. IC матрица.

Рисунок 2. LOGO.
- Задание 2. FIMO.
В данном задании я использовал мотивы, найденные в предыдущем практикуме, чтобы отыскать их в геноме как моего вируса Bat Hp-betacoronavirus/Zhejiang2013 , так и двух родственных ему: Zaria bat coronavirus из одного "подрода", SARS-CoV-2 из одного рода.
Программа FIMO запускалась следующим образом для трех полных геномов:fimo --o result_gen --motif 1 --norc meme.txt genus_sars.fasta
Полученные выдачи FIMO (для первого мотива из MEME): Bat Hp-betacoronavirus, Zaria bat coronavirus, SARS-CoV-2.
Также для моего вируса были найдены 1, 2, 3, 5 мотивы, при этом первого найдено больше остальных, эти находки демонстрируют низкий false discovery rate. Для другого коронавируса летучей мыши три лучшие находки - первый мотив, при этом они найден в upstream областях генов. В геноме SARS-CoV-2 (всего на Genbank указано 11 CDS) первый мотив также относится к лучшим находкам, 6 из них находятся в upstream областях генов. Я не могу сделать вывод, что этот мотив действительно представляет собой сигнал регуляции транскрипции у моего вируса. Однако если сделать такое предположение, результаты не позволяют сказать, что данный мотив является специфичным исключительно для моего штамма. Возможно, поиск по части этого мотива дал бы более достоверные результаты.
Далее я построил LOGO последовательности Козак поздних генов моего коронавируса. Я воспользовался сервисом webLOGO, куда загрузил вырезанные из нуклеотидных последовательностей участки. Я вырезал для кажого гена 9 позиций слева от ATG и две справа. LOGO для моего вируса (Рисунок 3) похожи с LOGO для человека (Рисунок 4) по позициям -2 (С), -3 (А) и +3 (G). Это может быть случайным совпадением, так как информационное содержание не высоко, но, с другой стороны, эти позиции могут вносить свой небольшой вклад в узнавание сайта начала трансляции человеческой рибосомой.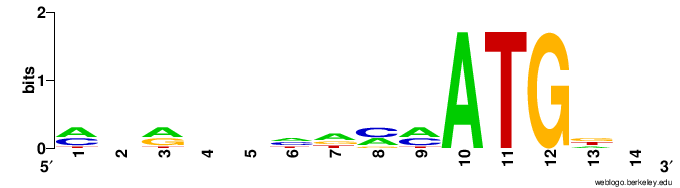
Рисунок 3. LOGO последовательности Козак моего вируса.
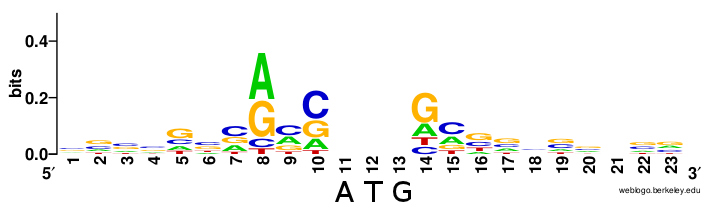
Рисунок 4. LOGO последовательности Козак человека Wiki .