Визуализация деревьев по гомологам белка
Поиск гомологов ClpX
Из данных протеомов бактерий отдела Pseudomonadota я выбрал 8 (+ протеом E.coli):
PSEMY.fasta
AROAE.fasta
YERPE.fasta
PARDP.fasta
SHEDO.fasta
SERP5.fasta
ACICJ.fasta
NEIMA.fasta
Сначала я объединил протеомы в один fasta:
cat PSEMY.fasta AROAE.fasta YERPE.fasta PARDP.fasta SHEDO.fasta SERP5.fasta ACICJ.fasta NEIMA.fasta ECOLI.fasta> all_proteomes.fasta
Затем создал базу данных:
makeblastdb -in all_proteomes.fasta -out proteomes.db -dbtype prot
После осуществил поиск гомологов CLPX_ECOLI по моей базе данныз:
blastp -query CLPX_ECOLI.fasta -out blastp.out -evalue 0.0000000001 -db proteomes.db
И получил следующий файл с выравниваниями.
Использовав на выдаче команду:
grep '>' blastp.out > findings.txt
я получил список с названиями нужных генов
Затем я использовал следующий код на Python, чтобы получить fasta с генами-гомологами
Для того, чтобы изменить название генов в fasta-файле использовал две команды sed:
sed 's/ .*//g' genes.fasta > genes1
sed 's/^>[^|]*|[^|]*|/>/' genes1 > genes2
Благодаря чему длинные названия последовательностей сменились на короткие мнемоники, это можно увидеть в итоговом Fasta
Затем при помощи алгоритма Muscle осуществил множественное выравнивание белковых последовательностей, получив следующий файл выравнивания.
Затем при помощи phy.py перевёл FASTA-формат в Phylip-формат.
После, использовав программу следующую команду:
iqtree -s muscle.phy -bb 1000
Я осуществил построение филогенетического дерева (Newick) программой iqtree (алгоритм максимального правдоподобия) с бутстрепом в 1000 реплик.
Затем использовал 2 файлы для покраски и изменения текста, получив следующее изображение:
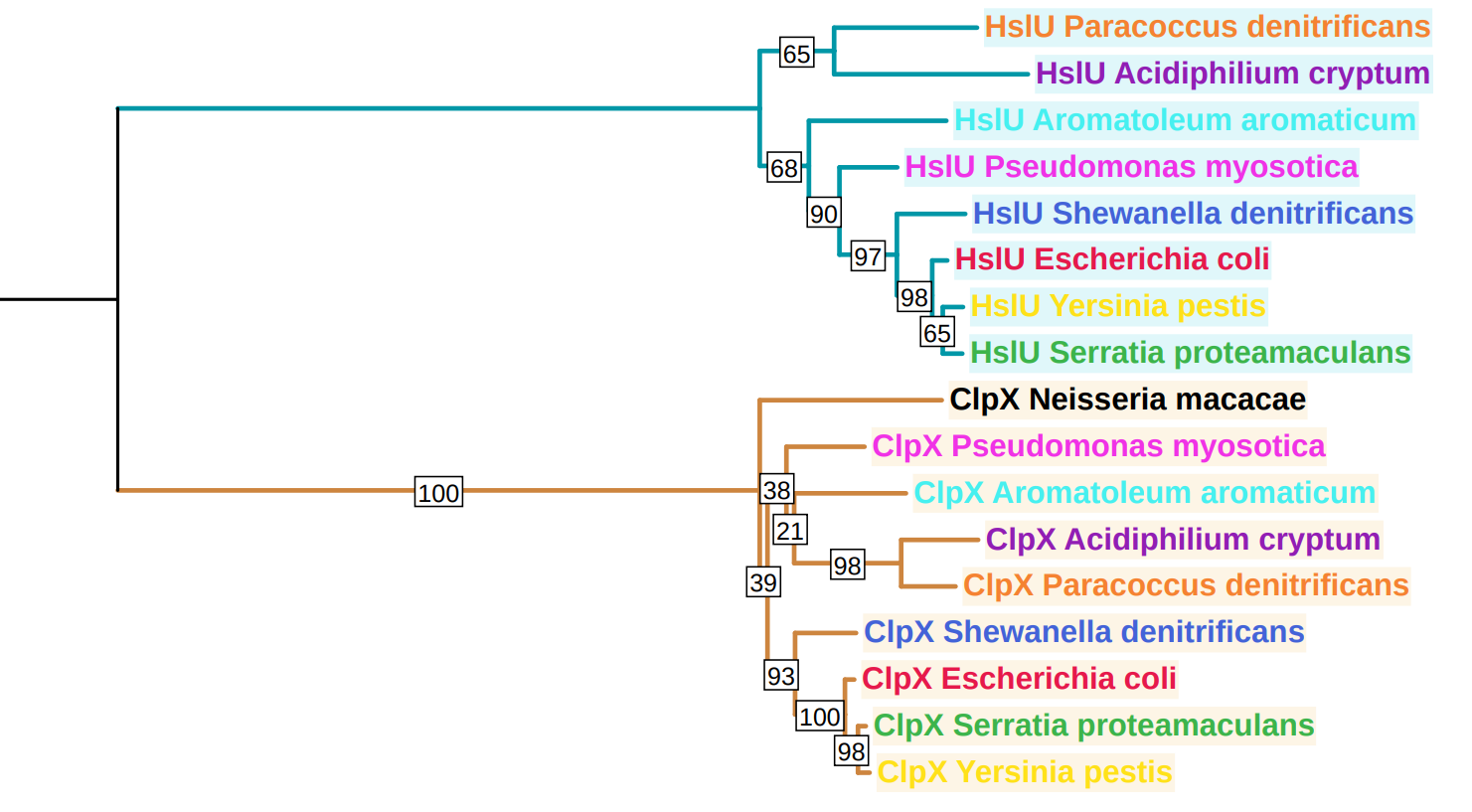
Из полученного изображения очевидно существование двух белков паралогов - шаперонов: HSLU и CLPX. Они образуют две ортологические группы.
Пример 3-ёх белков паралогов:
CLPX и HSLU у Pseudomonas myosotica (PSEMY)
CLPX и HSLU у Acidiphilium cryptum (ACICJ)
CLPX и HSLU у Yersinia pestis (YERPE)
Пример 3-ёх белков ортологов:
HSLU у Paracoccus denitrificans (PARDP) и Acidiphilium cryptum (ACICJ)
CPLX у Serratia proteamaculans (SERP5) и Yersinia pestis (YERPE)
CLPX у Pseudomonas myosotica (PSEMY) и Aromatoleum aromaticum (AROAE)
Затем я схлопнул ортологические группы, получив такое дерево:
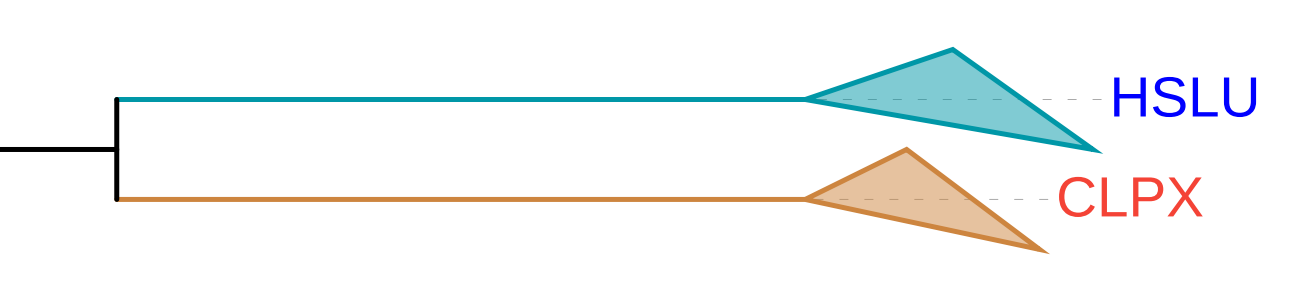
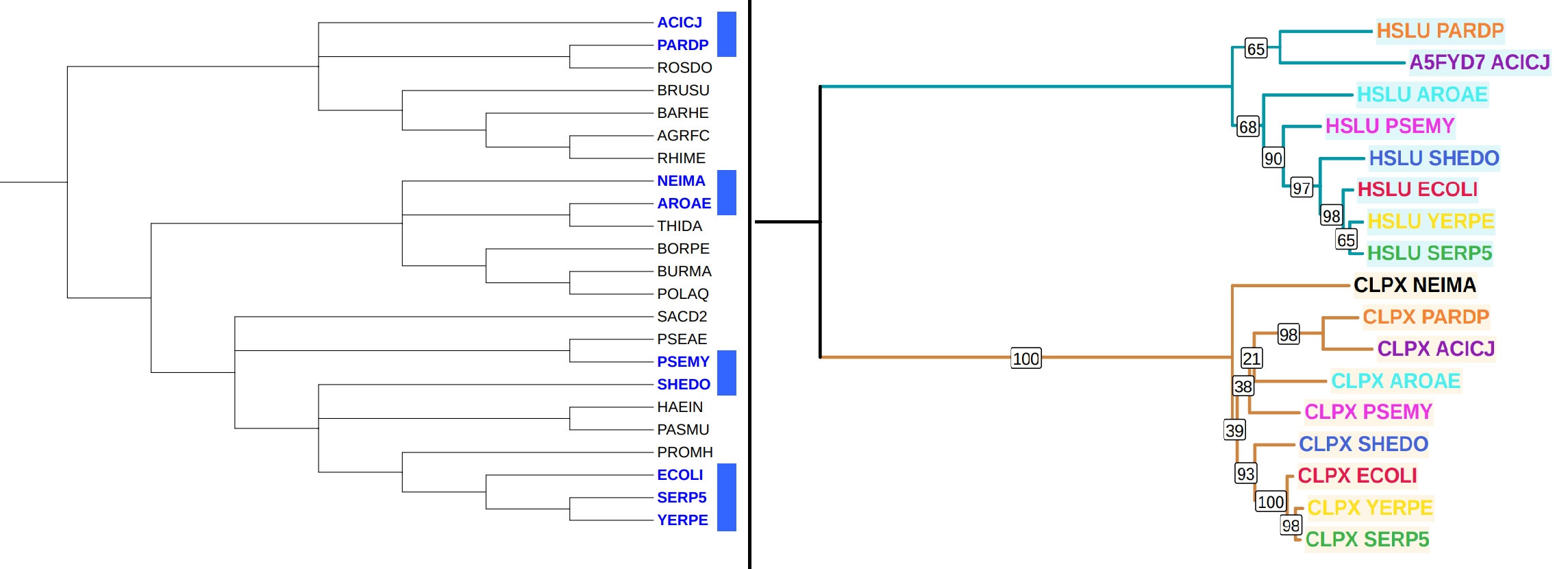
Из рисунка 3 видно, что так как мы брали гомологичные CPLX_ECOLI белки, то в ортологической группе CPLX оказалось больше организмов - на 1 ( есть белок от организма с мнемоникой NEIMA). Кстати, интересно, что несмотря на то, что организм с мнемоникой NEIMA не самый генетически удалёный от E. coli, его белки - шапероны CLPX и HSLU - оказались наименее схожими с CPLX_ECOLI. Белки организмов с мнемониками ACICJ и PARDP, несмотря на генетическую удалённость от E. coli, оказались более похожи на их гомолог, принадлежащий E. coli
Из примечательного, в обеих ортологических группах дерево смогло правильно определить кладу Энтеробактерий, состоящую из SERP5, YERPE и ECOLI. Также в обеих ортологических группах смогли правильно определить принадлежность к одной кладе Альфа-протеобактерий организмов с мнемониками ACICJ и PARDP
Из различий: в обеих ортологических группах не смогли правильно определить кладу Бета-протеобактерий, включающую в себя организмы NEIMA и AROAE. Также в ортологической группе HSLU смогли правильно определить положение организмов SHEDO, PSEMU и AROAE; И вообще ортологическое дерево по HSLU очень точно отражает настоящее положение дел. Единственным минусом остаётся отсутствие NEIMA среди ортологов. У ортологической группы CPLX, напротив, всё достаточно паршиво: дерево сблизило PSEMU и AROAE с Альфа-протеобактериями в лице ACICJ и PARDP, что противоречит таксономии; так к тому же так ужасно вставило CLPX NEIMA к себе, что лучше уж вообще не добавляла