Взял выравнивание из 2 варианта. Для выравнивания посчитал количество нуклеотидов в каждой позиции и наблюдаемые частоты встречаемости нуклеотидов.
Матрицу PMW не считал, сразу подставлял в формулу для подсчета IC (но считал без псевдокаунтов).
Базовые частоты встречаемости нуклеотидов взял из данных по Danio Rerio.
Формула, которая использовалась для расчета IC:
IC(b,j) = f(b,j)*log2[f(b,j)/p(b)]
С помощью сервиса http://weblogo.berkeley.edu/logo.cgi получил лого-картинку.
В каждой позиции каждая буква изображается прямоугольником высоты, равной её информационному содержанию. Судя по всему, LOGO не нравятся позиции для которых мало информации, так как в первой позиции ничего нет.
fimo --o pr7_res --motif 1 --norc meme.txt pr_7_fullseq.fasta
Для других геномов fimo запускалось с аналогичными параметрами. Результат работы fimo можно скачать:
Middle East respiratory syndrome coronavirus
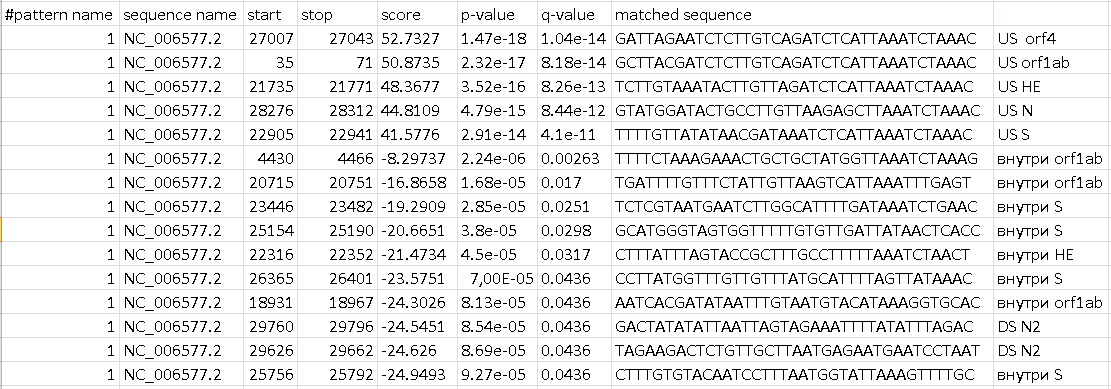
Также находки fimo для исходного генома представлены на рисунке ниже. Можно увидеть, что с хорошими e-value fimo нашел мотив как раз в upstream областях генов.
Возможно я допустил какую-то фатальную ошибку при выполнении 6 практикума, однако находки из генома другого штамма уж очень хороши и очень похожи на находки из изначального генома (генома Human coronavirus HKU1).
Из минусов выделенного мотива могу выделить его длинну (уж очень длинный получился), далеко не самый консервативный левый хвост (однако правый хвост очень консервативен и встречается в US области практически каждого гена).
Из генома Human coronavirus HKU1 были вырезаны последовательности с -9 до 4 позиции для всех генов, там где должны быть последовательности Козак. Было получено Logo этих последовательностей.

Logo последовательности Козак человека
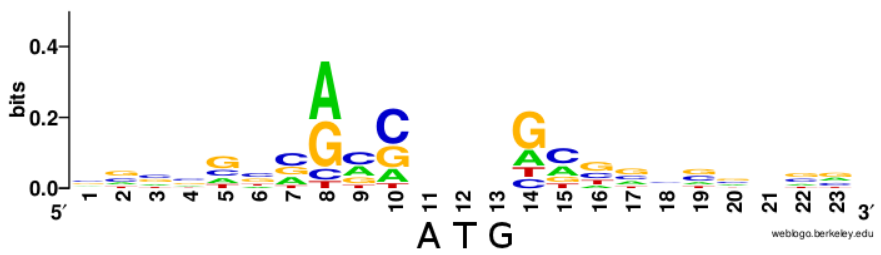
LOGO для моего вируса похожи с LOGO для человека по позициям -3 (А), -4 (С) и +2 (А). Однако это может оказаться простым совпадением, так как информационное содержание не высоко.