Знакомство со структурой банка RefSeq посредством поисковой системы SRS
Через SRS вывела список хромосом дрожжей Saccharomyces cerevisiae.
REFSEQ_DNA:NC_001133 NC_001133 Saccharomyces cerevisiae S288c chromosome I, complete sequence. 230218 REFSEQ_DNA:NC_001134 NC_001134 Saccharomyces cerevisiae S288c chromosome II, complete sequence. 813184 REFSEQ_DNA:NC_001135 NC_001135 Saccharomyces cerevisiae S288c chromosome III, complete sequence. 316620 REFSEQ_DNA:NC_001136 NC_001136 Saccharomyces cerevisiae S288c chromosome IV, complete sequence. 1531933 REFSEQ_DNA:NC_001137 NC_001137 Saccharomyces cerevisiae S288c chromosome V, complete sequence. 576874 REFSEQ_DNA:NC_001138 NC_001138 Saccharomyces cerevisiae S288c chromosome VI, complete sequence. 270161 REFSEQ_DNA:NC_001139 NC_001139 Saccharomyces cerevisiae S288c chromosome VII, complete sequence. 1090940 REFSEQ_DNA:NC_001140 NC_001140 Saccharomyces cerevisiae S288c chromosome VIII, complete sequence. 562643 REFSEQ_DNA:NC_001141 NC_001141 Saccharomyces cerevisiae S288c chromosome IX, complete sequence. 439888 REFSEQ_DNA:NC_001142 NC_001142 Saccharomyces cerevisiae S288c chromosome X, complete sequence. 745751 REFSEQ_DNA:NC_001143 NC_001143 Saccharomyces cerevisiae S288c chromosome XI, complete sequence. 666816 REFSEQ_DNA:NC_001144 NC_001144 Saccharomyces cerevisiae S288c chromosome XII, complete sequence. 1078177 REFSEQ_DNA:NC_001145 NC_001145 Saccharomyces cerevisiae S288c chromosome XIII, complete sequence. 924431 REFSEQ_DNA:NC_001146 NC_001146 Saccharomyces cerevisiae S288c chromosome XIV, complete sequence. 784333 REFSEQ_DNA:NC_001147 NC_001147 Saccharomyces cerevisiae S288c chromosome XV, complete sequence. 1091291 REFSEQ_DNA:NC_001148 NC_001148 Saccharomyces cerevisiae S288c chromosome XVI, complete sequence. 948066
Мне была задана восьмая хромосома. Ее длина 562643, количество генов и тРНК в ней - 297 и 11 соответственно.Для нее я привожу примеры четырёх генов на заданной хромосоме, а именно:
– гена, который находится на прямой цепи и не имеет интронов;
gene 6401..7546
/gene="COS8"
/locus_tag="YHL048W"
/db_xref="GeneID:856337"
mRNA 6401..7546
/gene="COS8"
/locus_tag="YHL048W"
/product="Cos8p"
/transcript_id="NM_001179128.1"
/db_xref="GI:296145324"
/db_xref="GeneID:856337"
CDS 6401..7546
/gene="COS8"
/locus_tag="YHL048W"
/note="Nuclear membrane protein, member of the DUP380
subfamily of conserved, often subtelomerically-encoded
proteins; regulation suggests a potential role in the
unfolded protein response"
/codon_start=1
/product="Cos8p"
/protein_id="NP_011815.1"
/db_xref="GI:6321739"
/db_xref="SGD:S000001040"
/db_xref="GeneID:856337"
/translation="MKENEVKDEKSVDVLSFKQLEFQKTVLPQDVFRNELTWFCYEIY
KSLAFRIWMLLWLPLSVWWKLSSNWIHPLIVSLLVLFLGPFFVLVICGLSRKRSLSKQ
LIQFCKEITEDTPSSDPHDWEVVAANLNSYFYENKTWNTKYFFFNAMSCQKAFKTTLL
EPFSLKKDESAKVKSFKDSVPYIEEALQVYAAGFDKEWKLFNTEKEESPFDLEDIQLP
KEAYRFKLTWILKRIFNLRCLPLFLYYFLIVYTSGNADLISRFLFPVVMFFIMTRDFQ
NMRMIVLSVKMEHKMQFLSTIINEQESGANGWDEIAKKMNRYLFEKKVWNNEEFFYDG
LDCEWFFRRFFYRLLSLKKPMWFASLNVELWPYIKEAQSARNEKPLK"
– гена, который находится на обратной цепи и не имеет интронов;
gene complement(3726..4541)
/locus_tag="YHL049C"
/db_xref="GeneID:856336"
mRNA complement(3726..4541)
/locus_tag="YHL049C"
/product="hypothetical protein"
/transcript_id="NM_001179129.1"
/db_xref="GI:296145322"
/db_xref="GeneID:856336"
CDS complement(3726..4541)
/locus_tag="YHL049C"
/codon_start=1
/product="hypothetical protein"
/protein_id="NP_011814.1"
/db_xref="GI:6321738"
/db_xref="SGD:S000001041"
/db_xref="GeneID:856336"
/translation="MKVSDRRKFEKANFDEFESALNNKNDLVHCPSITLFESIPTEVR
SFYEDEKSGLIKVVKFRTGAMDRKRSFEKIVVSVMVGKNVQKFLTFVEDEPDFQGGPI
PSKYLIPKKINLMVYTLFQVHTLKFNRKDYDTLSLFYLNRGYYNELSFRVLERCHEIA
SARPNDSSTMRTFTDFVSGAPIVRSLQKSTIRKYGYNLAPHMFLLLHVDELSIFSAYQ
ASLPGEKKVDTERLKRDLCPRKPTEIKYFSQICNDMMNKKDRLGDVLHVCCPS"
– гена, который находится на прямой цепи и имеет хотя бы один интрон;
gene 85909..91318
/locus_tag="YHL009W-B"
/db_xref="GeneID:856380"
mRNA join(<85909..86994,86996..>91318)
/locus_tag="YHL009W-B"
/product="gag-pol fusion protein"
/transcript_id="NM_001184404.1"
/db_xref="GI:296145363"
/db_xref="GeneID:856380"
CDS join(85909..86994,86996..91318)
/locus_tag="YHL009W-B"
/EC_number="2.7.7.49"
/EC_number="2.7.7.7"
/EC_number="3.4.23.-"
/EC_number="3.1.26.4"
/ribosomal_slippage
/note="Retrotransposon TYA Gag and TYB Pol genes;
transcribed/translated as one unit; polyprotein is
processed to make a nucleocapsid-like protein (Gag),
reverse transcriptase (RT), protease (PR), and integrase
(IN); similar to retroviral genes"
/codon_start=1
/product="gag-pol fusion protein"
/protein_id="NP_058133.1"
/db_xref="GI:7839180"
/db_xref="SGD:S000007372"
/db_xref="GeneID:856380"
/translation="MATPVRDETRNVIDDNISARIQSKVKTNDTVRQTPSSLRKVSIK
DEQVKQYQRNLNRFKTILNGLKAEEEKLSETDDIQMLAEKLLKLGETIDKVENRIVDL
VEKIQLLETNENNNILHEHIDATGTYYLFDTLTSTNKRFYPKDCVFDYRTNNVENIPI
LLNNFKKFIKKYQFDDVFENDIIEIDPRENEILCKIIKEGLGESLDIMNTNTTDIFRI
IDGLKNKYRSLHGRDVRIRAWEKVLVDTTCRNSALLMNKLQKLVLMEKWIFSKCCQDC
PNLKDYLQEAIMGTLHESLRNSVKQRLYNIPHNVGINHEEFLINTVIETVIDLSPIAD
DQIENSCMYCKSVFHCSINCKKKPNRELGLTRPISQKPIIYKVHRDNNNLSPVQNEQK
SWNKTQKKSNKVYNSKKLVIIDTGSGVNITNDKTLLHNYEDSNRSTRFFGIGKNSSVS
VKGYGYIKIKNGHNNTDNKCLLTYYVPEEESTIISCYDLAKKTKMVLSRKYTRLGNKI
IKIKTKIVNGVIHVKMNELIERPSDDSKINAIKPTSSPGFKLNKRSITLEDAHKRMGH
TGIQQIENSIKHNHYEESLDLIKEPNEFWCQTCKISKATKRNHYTGSMNNHSTDHEPG
SSWCMDIFGPVSSSNADTKRYMLIMVDNNTRYCMTSTHFNKNAETILAQIRKNIQYVE
TQFDRKVREINSDRGTEFTNDQIEEYFISKGIHHILTSTQDHAANGRAERYIRTIVTD
ATTLLRQSNLRVKFWEYAVTSATNIRNCLEHKSTGKLPLKAISRQPVTVRLMSFLPFG
EKGIIWNHNHKKLKPSGLPSIILCKDPNSYGYKFFIPSKNKIVTSDNYTIPNYTMDGR
VRNTQNIYKSHQFSSHNDNEEDQIETVTNLCEALENYEDDNKPITRLEDLFTEEELSQ
IDSNAKYPSPSNNLEGDLDYVFSDVEESGDYDVESELSTTNTSISTDKNKILSNKDFN
SELASTEISISEIDKKGLINTSHIDEDKYDEKVHRIPSIIQEKLVGSKNTIKINDENR
ISDRIRSKNIGSILNTGLSRCVDITDESITNKDESMHNAKPELIQEQFNKTNHETSFP
KEGSIGTNVKFRNTDNEISLKTGDTSLPIKTLESINNHHSNDYSTNKVEKFEKENHHP
PPIEDIVDMSDQTDMESNCQDGNNLKELKVTDKNVPTDNGTNVSPRLEQNIEASGSPV
QTVNKSAFLNKEFSSLNMKRKRKRHDKNNSLTSYELERDKKRSKRNRVKLIPDNMETV
SAQKIRAIYYNEAISKNPDLKEKHEYKQAYHKELQNLKDMKVFDVDVKYSRSEIPDNL
IVPTNTIFTKKRNGIYKARIVCRGDTQSPDTYSVITTESLNHNHIKIFLMIANNRNMF
MKTLDINHAFLYAKLEEEIYIPHPHDRRCVVKLNKALYGLKQSPKEWNDHLRQYLNGI
GLKDNSYTPGLYQTEDKNLMIAVYVDDCVIAASNEQRLDEFINKLKSNFELKITGTLI
DDVLDTDILGMDLVYNKRLGTIDLTLKSFINRMDKKYNEELKKIRKSSIPHMSTYKID
PKKDVLQMSEEEFRQGVLKLQQLLGELNYVRHKCRYDINFAVKKVARLVNYPHERVFY
MIYKIIQYLVRYKDIGIHYDRDCNKDKKVIAITDASVGSEYDAQSRIGVILWYGMNIF
NVYSNKSTNRCVSSTEAELHAIYEGYADSETLKVTLKELGEGDNNDIVMITDSKPAIQ
GLNRSYQQPKEKFTWIKTEIIKEKIKEKSIKLLKITGKGNIADLLTKPVSASDFKRFI
QVLKNKITSQDILASTDY"
– гена, который находится на обратной цепи и имеет хотя бы один интрон.
gene complement(445..3311)
/locus_tag="YHL050C"
/db_xref="GeneID:856335"
mRNA complement(join(445..1897,2671..3311))
/locus_tag="YHL050C"
/product="hypothetical protein"
/transcript_id="NM_001179130.1"
/db_xref="GI:296145321"
/db_xref="GeneID:856335"
CDS complement(join(445..1897,2671..3311))
/locus_tag="YHL050C"
/note="hypothetical protein, potential Cdc28p substrate"
/codon_start=1
/product="hypothetical protein"
/protein_id="NP_011813.1"
/db_xref="GI:6321737"
/db_xref="SGD:S000001042"
/db_xref="GeneID:856335"
/translation="MADTPSVAVQAPPGYGKTELFHLPLIALASKGDVEYVSFLFVPY
TVLLANCMIRLGRCGCLNVAPVRNFIEEGCDGVTDLYVGIYDDLASTNFTDRIAAWEN
IVECTFRTNNVKLGYLIVDELHNFETEVYRQSQFGGITNLDFDAFEKAIFLSGTAPEA
VADAALQRIGLTGLAKKSMDINELKRSEDLSRGLSSYPTRMFNLIKEKSKVPLGTNAT
TTASTNVRTSATTTASINVRTSATTTASINVRTSATTTESTNSNTNATTTESTNSSTN
ATTTASTNSSTNATTTESTNASAKEDANKDGNAEDNRFHPVTDINKEPYKRKGSQMVL
LERKKLKAQFPNTSENMNVLQFLGFRSDEIKHLFLYGIDIYFCPEGVFTQYGLCKGCQ
KMFELCVCWAGQKVSYRRMAWEALAVERMLRNDEEYKEYLEDIEPYHGDPVGYLKFFS
VKRREIYSQIQRNYAWYLAITRRRETISVLDSTRGKQGSQVFRMSGRQIKELYYKVWS
NLRESKTEVLQYFLNWDEKKCQEEWEAKDDTVFVEALEKVGVFQRLRSMTSAGLQGPQ
YVKLQFSRHHRQLRSRYELSLGMHLRDQLALGVTPSKVPHWTAFLSMLIGLFYNKTFR
QKLEYLLEQISEVWLLPHWLDLANVEVLAADNTRVPLYMLMVAVHKELDSDDVPDGRF
DIILLCRDSSREVGE"
Получение последовательности, кодирующей заданный белок
На kodomo выполнила команду entret sw:4ot_bacsu, где 4ot_bacsu – AC моего белка в Swiss-Prot. В полученном файле нашла строки, начинающуюся с "DR EMBL", сразу после "EMBL" идёт AC записи EMBL.
DR EMBL; Z80360; CAB02512.1; -; Genomic_DNA. DR EMBL; AL009126; CAB15781.1; -; Genomic_DNA.
К моему белку относится запись
FT CDS complement(2388..2576) FT /transl_table=11 FT /gene="ywhB" FT /product="Unknown, highly similar to Pseudomonas putida FT 4-oxalocrotonate tautomerase" FT /db_xref="GOA:P70994" FT /db_xref="InterPro:IPR004370" FT /db_xref="InterPro:IPR014347" FT /db_xref="InterPro:IPR018191" FT /db_xref="PDB:2OP8" FT /db_xref="PDB:2OPA" FT /db_xref="UniProtKB/Swiss-Prot:P70994" FT /protein_id="CAB02512.1" FT /translation="MPYVTVKMLEGRTDEQKRNLVEKVTEAVKETTGASEEKIVVFIEE FT MRKDHYAVAGKRLSDME" FT RBS complement(2588..2594) FT /note="label:ywhB"
Понятно, что кодирующая последовательность находится на обратной цепи с 2388 по 2576 знак. Воспользовалась командой seqret с опцией -sask и получила последовательность гена.
>Z80360 Z80360.1 B.subtilis thrZ downstream chromosomal region. atgccatacgtaactgtcaaaatgctcgaaggccgtacagacgagcaaaaacgcaatctt gtcgagaaagtaacagaagccgtaaaggaaacaaccggtgcttctgaagaaaaaattgtt gtctttatagaagaaatgagaaaagaccattatgccgtcgcaggcaaacgcctgagcgat atggaataa
Выравнивание белков и их генов
Для своего белка и одного из его гомологов создала (во всех приведенных ниже выравниваниях верхняя последовательность - мой белок YWHB_BACSU, а нижняя - его гомолог 4OT_COMTE):
а) выравнивание последовательностей белков программой needle:
P70994 1 MPYVTVKMLEGRTDEQKRNLVEKVTEAVKETTGASEEKIVVFIEEMRKDH 50
||:..:.|||||::|||:.::||||.|:.|..||....:.|:|.::.|::
4ot_comte 1 MPFAQIYMLEGRSEEQKKAVIEKVTRALVEAVGAPSANVRVWIHDVPKEN 50
P70994 51 YAVAGKRLSDME- 62
:.:||....::.
4ot_comte 51 WGIAGVSAKELGR 63
б) выравнивание последовательностей их генов программой needle:
Z80360 1 atgccatacgtaactgtcaaa-----atgctcgaaggccgtacagacgag 45
|||||||.||.| |||| |||||.||||||||.|..||.||.
AB029044 1 atgccattcgca-----caaatctacatgctggaaggccgcagcgaggaa 45
Z80360 46 c--aaaaacgcaatcttg----tcgagaaagtaac------------aga 77
| |||||.|| | ||||.||.||.|| .||
AB029044 46 cagaaaaaggc------ggtgatcgaaaaggttacccgggccctggtcga 89
Z80360 78 agccgtaaaggaaacaaccggtgcttctg--aagaaaaaattgt---tgt 122
.||||| .|| ||.|.|.||.| || ||| .||
AB029044 90 ggccgt--tgg-------cgctccctccgccaa--------tgtgcgggt 122
Z80360 123 ctttatagaaga-------aatgagaaaagac-----cattatgccgtcg 160
||..|||.|.|| ||.|||| || ||| |||||.||
AB029044 123 ctggatacacgatgtgcccaaggaga----actggggcat--tgccggcg 166
Z80360 161 -cag-gcaaa----------cgcctgagcgatatggaataa 189
||| ||.|| || ||||
AB029044 167 tcagtgccaaagaactggggcg-ctga-------------- 192
в) выравнивание последовательностей их генов программой tranalign (эта программа очень милая - она просто сделала в нуклеотидных последовательностях гэпы на месте гэпов в выровненных белках).
>Z80360 atgccatacgtaactgtcaaaatgctcgaaggccgtacagacgagcaaaaacgcaatctt gtcgagaaagtaacagaagccgtaaaggaaacaaccggtgcttctgaagaaaaaattgtt gtctttatagaagaaatgagaaaagaccattatgccgtcgcaggcaaacgcctgagcgat atggaa--- >AB029044 atgccattcgcacaaatctacatgctggaaggccgcagcgaggaacagaaaaaggcggtg atcgaaaaggttacccgggccctggtcgaggccgttggcgctccctccgccaatgtgcgg gtctggatacacgatgtgcccaaggagaactggggcattgccggcgtcagtgccaaagaa ctggggcgc
Выравнивание последовательностей генов программой needle мне кажется наименее биологически осмысленным: здесь нет никакого учета триплетности, что ведет к неправильным выводам - гомологами могут оказаться последовательности, имеющие совершенно разный аминокислотный состав. Наиболее логичным кажется выравнивание последовательности белков по белку.
Поиск в нуклеотидном банке NCBI по имени гена
Для поиска в нуклеотидном банке я взяла ген дрожжей YHL009W-B. По данному запросу в NCBI у меня нашлись три последовательности: матричная РНК данного белка длиной 5,409 пар нуклеотидов и две "разные" восьмые хромосомы Saccharomyces cerevisiae длиной 562643 пары оснований. Радует то, что результата всего три - здесь есть некоторая однозначность (рисунок 1). Порадовали две восьмые хромосомы; они, видимо, были получены разными людьми. У третьей записи есть кнопочка Related sequences. По ней можно просмотреть еще 1475 последовательностей, которые представляют собой кусочки восьмой хромосомы различной длины.
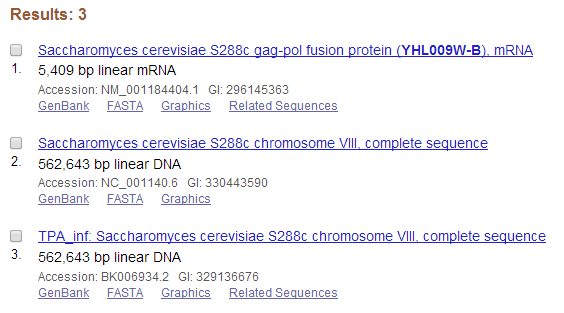
Рисунок 1. Результаты поиска по нуклеотидному банку.
Итак, что можно сказать по поводу моих ощущений от поиска: во-первых, оно ищется; во-вторых, поиски по названию гена дают не так много результатов, что дает надежду на точность результатов поиска; в-третьих, по Related sequences можно найти информацию о других генах, находящихся в той же хромосоме.