Практикум 6
0. Описание данных
Данный практикум выполнялся с испоользованием списка ID генов человека. Всего в списке 67 наименования генов. В данном практикуме для начала был проведен анализ обогощения терминами, основная цель которого определить, какие биологические процессы, молекулярные функции или клеточные компоненты могут быть значимыми для установления связи между предложенными генами. Кроме того, был проведен анализ участия отдельных участников в различных метаболических путях. После суммации данных, полученных из нескольких баз данных, была построена последовательность участия продуктов предложенных генов в опредленном клеточном процессе.
1. Обогощение терминами GO
Для начала, чтобы понять есть ли какой-то объединяющий признак (клеточный компартмент, общий метаболичсекий путь, схожие функции) была использована база данных GO. База данных Gene Ontology (GO) представляет собой биоинформатический ресурс, который предоставляет информацию о функциях генов и их продуктов. GO разработана для обеспечения единого описания характеристик генов и их продуктов. Она состоит из трех основных категорий: 1. Молекулярные функции: что делают продукты генов на молекулярном уровне, например, каталитическая активность или связывание с лигандами. 2. Биологические процессы: паттерны изменений, которые происходят в результате работы одного или нескольких генов, например, метаболические пути. 3. Клеточные компоненты: положение продуктов генов в клетке, например, в ядре или цитоплазме. GO работает на основе словаря терминов, которые используются для аннотирования генов и их продуктов. Эти аннотации основаны на экспериментальных данных или например на вычислительных анализах. На основе терминов GO работает множество инструментов классификации, которые помогают исследователям анализировать и интерпретировать данные о функциях генов и белков. Например, GOrilla (Gene Ontology enRIchment anaLysis and visuaLizAtion tool). При использовании посика списка генов на сайте GO происходит перенаправление на страницу одного из таких инструментов - PANTHER. PANTHER (Protein ANalysis THrough Evolutionary Relationships) классифицирует белки в эволюционные семейства и аннотирует их с помощью GO-терминов, что позволяет связать эволюционные данные с функциональными характеристиками. Для обогощения термминами были использованы три запроса в PANTHER по соответвующим категориям терминов GO. На рисунке 1 показаны настройки запуска для одного из запросов. Для отсальных двух запросов менялись значения Annotation Data Set: на: GO cellular component complete и GO molecular function complete.
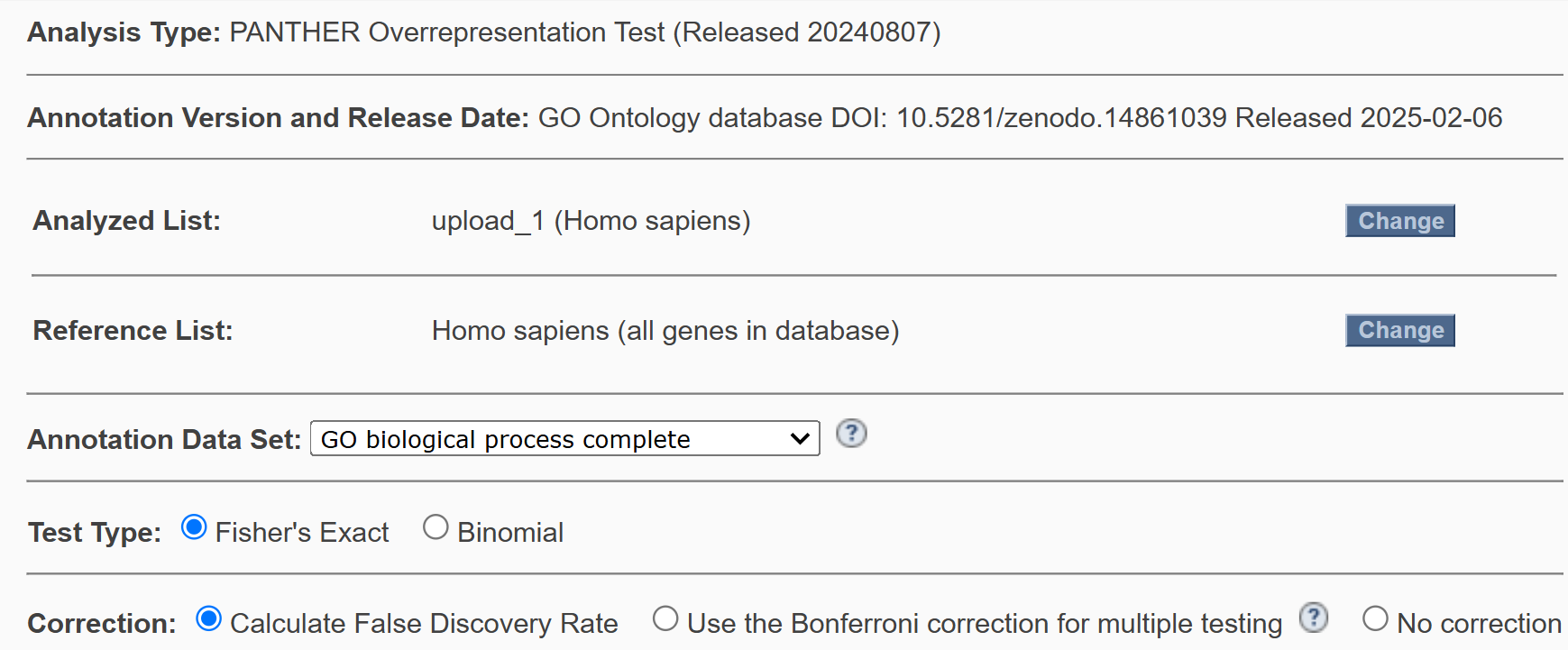
Рис.1 Параметры для проведения обогощения терминами GO
Как видно на риснке использовались тест Фишера для статистики и FDR (False Discovery Rate) для поправки на множественно тестирование. Табличную выдачу статистически значимых находок можно посмотреть: GO biological process, GO cellular component, GO molecular function.
Наиболее значимые находки при поиске по биологическому процессу показаны на рисунке 2.
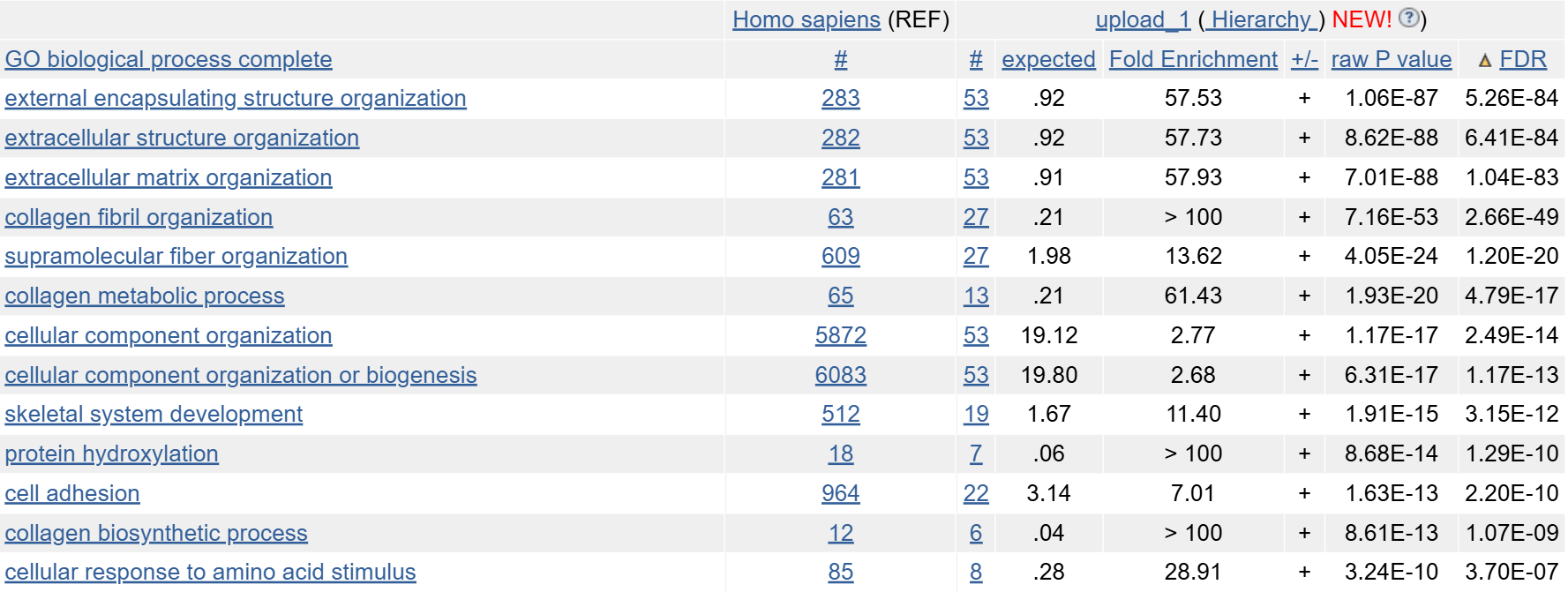
Рис.2 Значимые находки в категории GO biological process
Заметно, что встречается много упоминаний участия продуктов данных генов в структурной организации клеточных и субклеточных структур. Также встречаются упоминания коллагена, в частности его синтеза. Можно сделать вывод, что, по крайней мере, некоторые белки явялются структурными, но представлены и ферменты синтеза коллагена, который и является таким структурным белком.
Наиболее значимые находки при поиске по молекулярной функции показаны на рисунке 3.
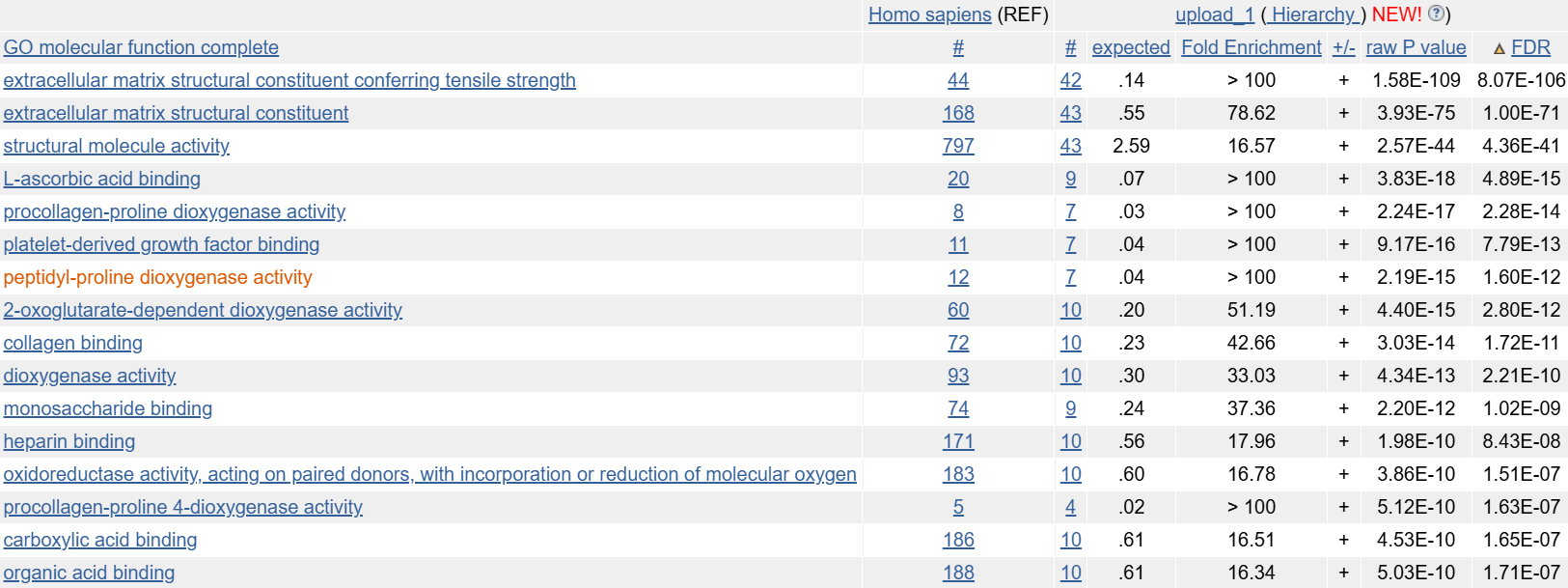
Рис.3 Значимые находки в категории GO molecular function
Здесь также заметно, что упомянуты именно структурные функции, например extracellular matrix structural constituent. Однако, здесь уже больше информации о каталитичсекой активности неокоторых находок, например oxidoreductase activity, acting on paired donors, with incorporation or reduction of molecular oxygen. И точно так же неоднократно встречаются функции, сопряженные с коллагеном или его синтезом.
В случае клеточных компонентов немного удобнее рассмотреть порядок не по статистиччсекой значимости, а по сопряженным и вложенным терминам. Такие находки показаны на рисунке 4.
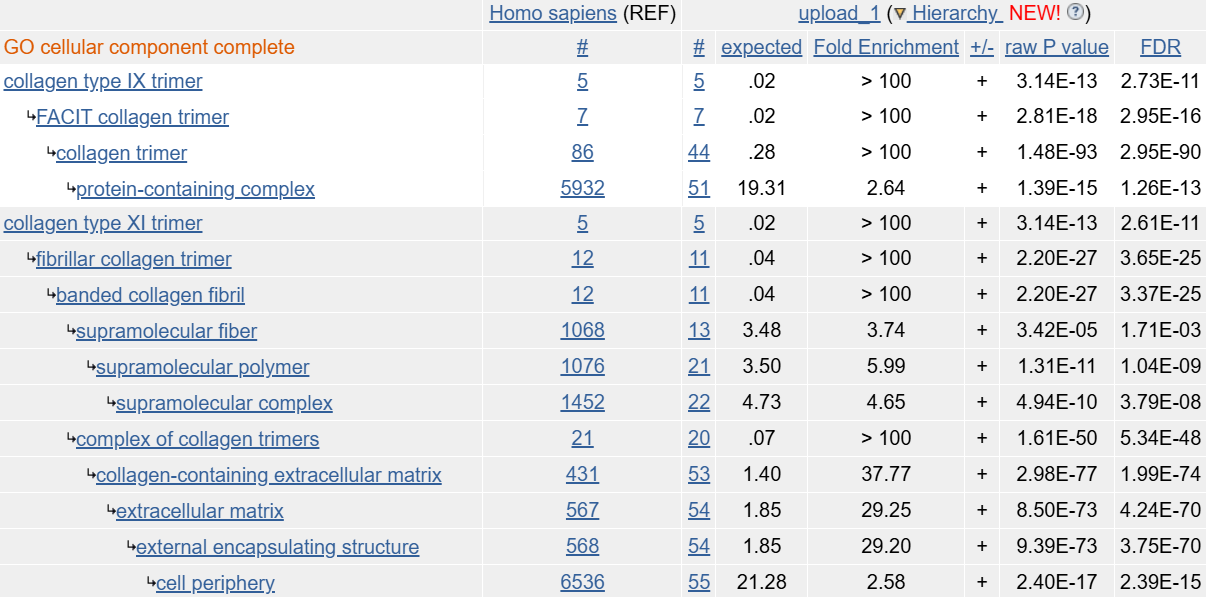
Рис.4 Находки в категории GO cellular component
Здесь уже в явном виде прослеживается принадлежность генов из списка к пути синтеза коллагена и самого коллагена. Встречается упоминание диоксигеназного комплекса, учавствующего в синтезе и созревании коллагена. Так же есть указания на сами структурные белки цепей коллагена.
При трех запросах в базе данных GO получены структуры белков, связанных с коллагеном, а также ферменты, участвующие в его синтезе, значит, по всей видимости, результаты отражают участие продуктов генов из списка в различных этапах синтеза и созревания коллагена. Коллаген — это сложный белок, который проходит через несколько стадий обработки и модификации, прежде чем стать функциональным компонентом соединительной ткани.
2. База данных KEGG
KEGG (Kyoto Encyclopedia of Genes and Genomes) — это интегрированная база данных, предоставляющая информацию о геномах, биологических путях, болезнях, лекарствах и химических веществах. KEGG организует биологическую информацию в виде путей — сетей молекулярных взаимодействий, описывающих функционирование генов и молекул в клетке. Данная база данных включает множество разделов. Некоторые из них: KEGG PATHWAY: Графические представления биологических путей. KEGG GENES: Каталог генов и геномов, аннотированных с использованием KEGG Orthology (KO). KEGG LIGAND: Информация о химических веществах, реакциях и ферментах. По полученным терминам и возможным путям участия был проведен подробный анализ некотрых из продуктов предложенных генов. Понятно, что набор ID связан с коллагеном. Коллаген — это структурный белок, состоящий из трех полипептидных цепей, которые образуют тройную спираль. Коллаген богат глицином, пролином и гидроксипролином, которые стабилизируют структуру. Ковалентные связи между цепями усиливают структуру, обеспечивая механическую прочность. Начать я решила с белков, входящях в состав procollagen-proline 4-dioxygenase complex. В него входят из данных ID P3H3, P3H2, P3H1, P4HA3 и P4HB. Начать я решила с P4HB. В KEGG PATHWAY для этого белка было определено участие в Protein processing in endoplasmic reticulum. На рисунке 5 показан обобщенный путь созревания белков в ЭПР:
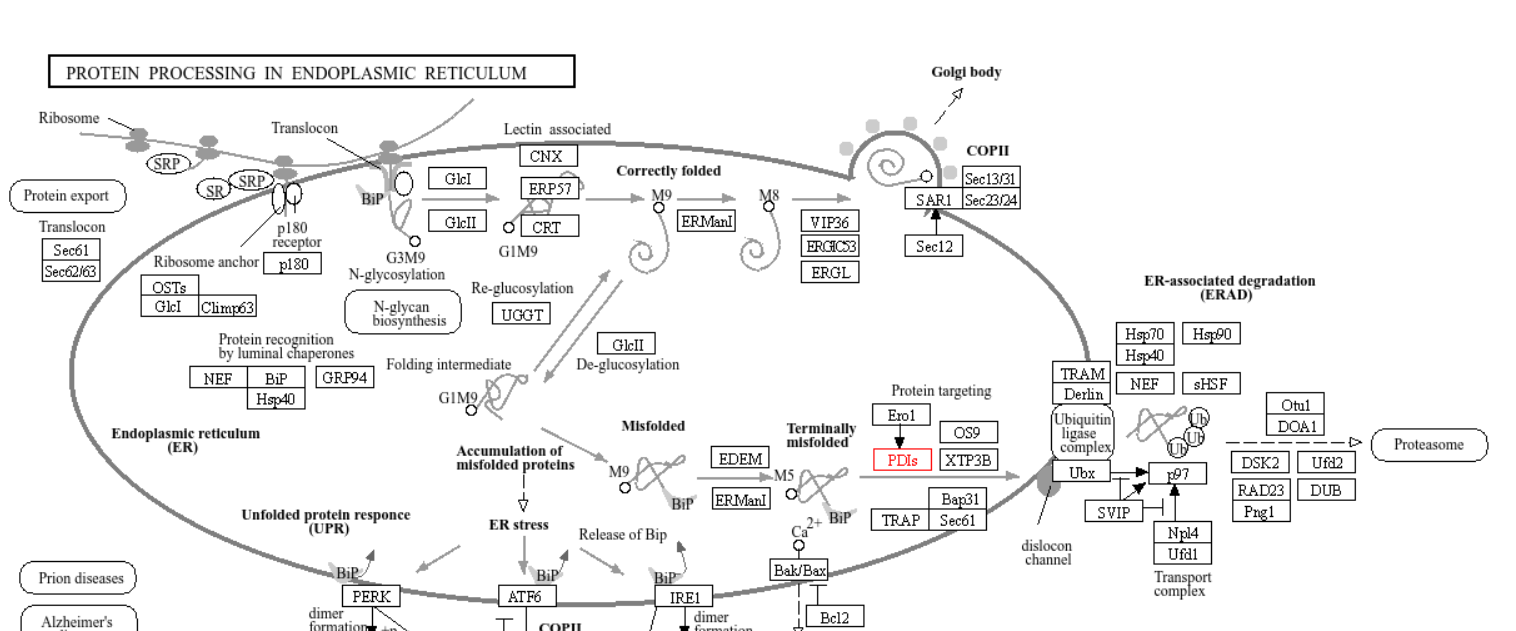
Рис.5 Созревание белков в ЭПР c участием продукта P4HB
На нем красным цветом выделен фермент, в состав которого входит продукт гена P4HB. Сам по себе он является дисульфид-изомеразой и производит реакцию по механизму показанному на рисунке 6 (на рисунке показан фермент это класса под названием PDIA1).
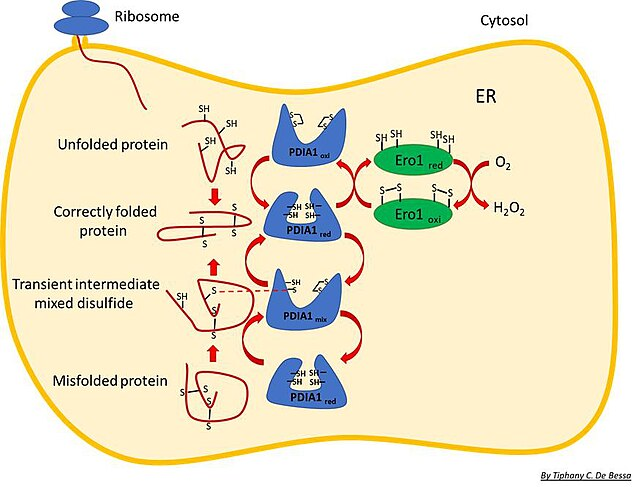
Рис.6 Механизм реакции дисульфид-изомеразы
PDI катализирует образование и изомеризацию дисульфидных связей между цистеиновыми остатками в проколлагене. Эти связи стабилизируют третичную структуру белка и способствуют правильному сворачиванию коллагеновых цепей. Продкуты остальных генов, кодирующих белки в составе комлекса, кодируют белки с пролил-гидроксилазной активностью. В аннотиациях в KEGG указаны как procollagen-proline 3-dioxygenase. Ферменты данного класса производят реакцию гидроксилирования пролина в 3-й позиции. Из сторонних источников опредлено, что самая распростаненная из них это гидроксилаза, кодируемая P3H1. Другие две могут иметь разные субстратные специфичности и выполнять различные функции в зависимости от типа ткани или клетки.
Еще одна группа белков, для которой был подробный анализ - белки, кодируемые семеством генов PLOD. В моем списке их три: PLOD1, PLOD2, PLOD3. В KEGG они аннотированы как procollagen-lysine,2-oxoglutarate 5-dioxygenase и находятся в пути модификации лизина. На рисунке 6 показаны исходные вещества и продукты.
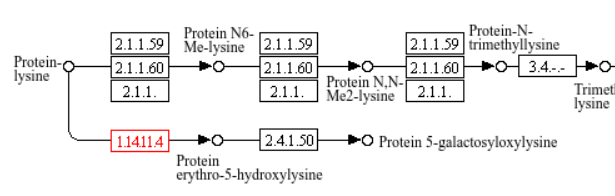
Рис.6 Механизм реакции дисульфид-изомеразы
Проколлаген-лизин,2-оксоглутарат 5-диоксигеназа — это фермент, который катализирует гидроксилирование остатков лизина в коллагене. PLOD катализирует гидроксилирование определенных остатков лизина в молекуле проколлагена, превращая их в гидроксилизин. Этот процесс происходит в эндоплазматическом ретикулуме и требует наличия кофакторов, таких как аскорбат (витамин C), железо (Fe²⁺) и альфа-кетоглутарат. Если обратиться к терминам GO, как раз функция связывания таких субстратов и была найдена.
Для разных типов здесь так же выделяют наиболее распростаненный тип PLOD1, а экпрессия двух других тканеспецифична. Например, PLOD3 активно экпрессируется в эндотелии сосудов.
Кроме того в списке генов очень много названий, которые выглядят как COLXAY, где X и Y различные цифры. По аннотациям KEGG можно понять что это белки, кодирующие цепи предшественников коллагена. Причем, X - номер коллагена, Y - номер цепи. Например, для COL4A4: collagen type IV alpha 4 chain. Таких генов в моем списке 41. В KEGG гены разных цепей коллагена можно найти в разных путях, например в интеграции экстрацеллюлярных рецепторов, схема показана на рисунке 7.
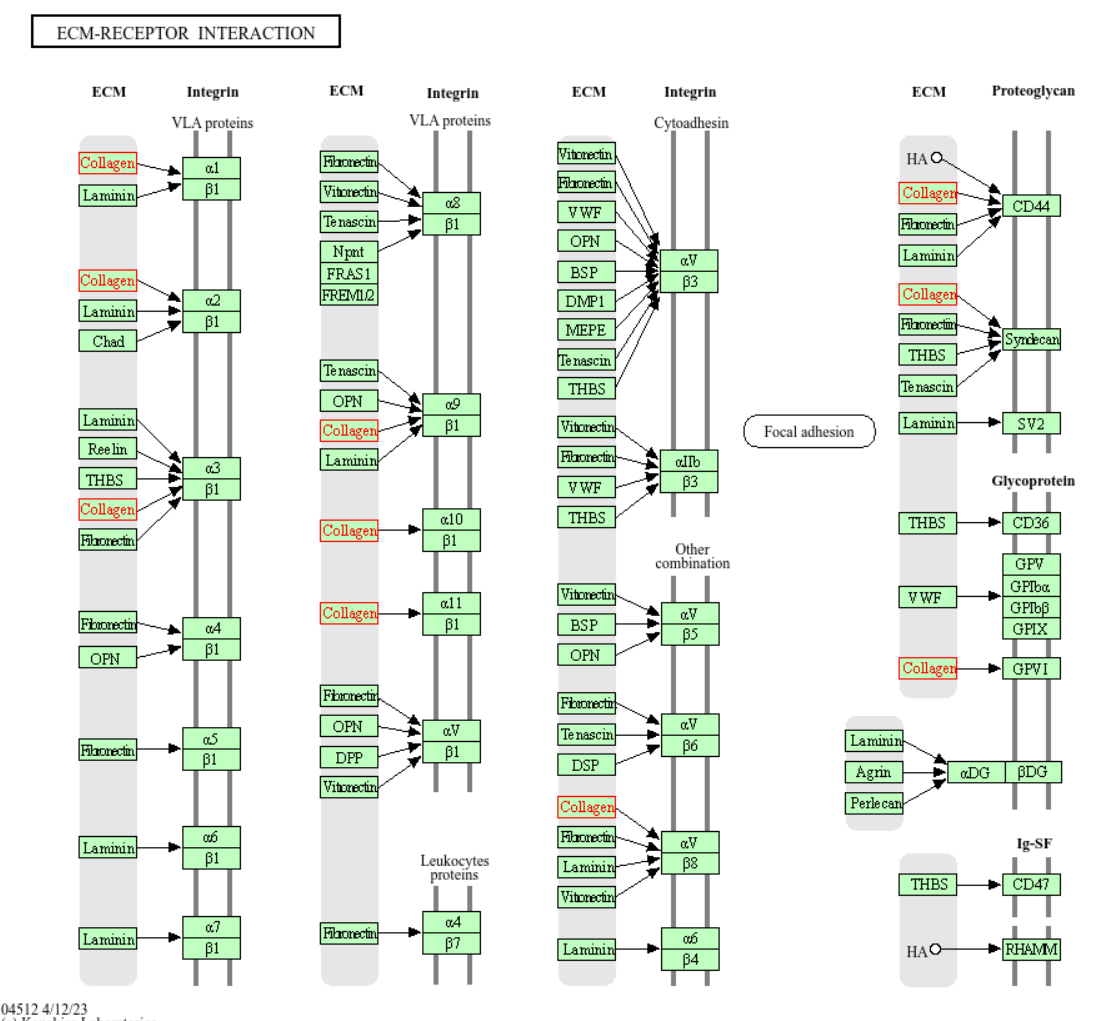
Рис.6Коллаген в интеграции рецепторов
Еще одними очень интерсной группой генов являются ADAMTS2, ADAMTS3, ADAMTS14. Оказалось, что они кодируют белки с названием metalloproteinase with thrombospondin motifs 3, то есть являются протеазами. Известно, что коллаген образовывается из проколлагена, и один из конечных этапов его созревания - обрезание N-концов. Вероятней всего, что белки данного семейства в этом и учавствуют.
Похож на них BMP1. Для него указана procollagen C-endopeptidase. То есть он отрезает от проколлагена чать C-конца.
Последняя группа генов, на которую у меня хватило сил - гены PPIB и SERPINH1. Общим для них является участие в правильном фолдинге белка. Для них описана активность: Chaperones and folding catalysts.
Итого, набор данных ID являются участниками синтеза и созревания коллагена. Приближенный путь выглядит следующим образом: Синтез коллагена начинается с транскрипции и трансляции коллагеновых генов, таких как COL1A1, COL1A2, COL3A1 и других, которые кодируют различные типы коллагеновых цепей. Эти цепи затем модифицируются и собираются в тройные спирали с помощью ферментов, таких как пролил-4-гидроксилазы (P4HA1, P4HA2, P4HA3) и лизилгидроксилазы (PLOD1, PLOD2, PLOD3). Эти ферменты катализируют гидроксилирование остатков пролина и лизина соответственно, что необходимо для стабильности коллагеновой тройной спирали. Сборка коллагеновых фибрилл далее регулируется белками, такими как BMP1, который расщепляет C-конец проколлагена и ферментами ADAMTS (ADAMTS2, ADAMTS3, ADAMTS14), которые обрабатывают N-пропептиды проколлагена. Кроме того, белки, такие как PPIB и SERPINH1, помогают в складывании молекул коллагена внутри клетки.