Комплексы ДНК-белок
Задание 1
С помощью программы einverted из пакета EMBOSS были найдены инвертированные участки в нуклеотидных последовательностях. У данной программы есть несколько параметров:
С помощью программы einverted из пакета EMBOSS были найдены инвертированные участки в нуклеотидных последовательностях. У данной программы есть несколько параметров:
С помощью web-сервиса RNAfold был реализован алгоритм Зукера. Результаты предсказания приведениы в табл.1. Изображение полученной структуры приведено на рис.1. Разными цветами обозначена энтропия остатка в данной позиции.
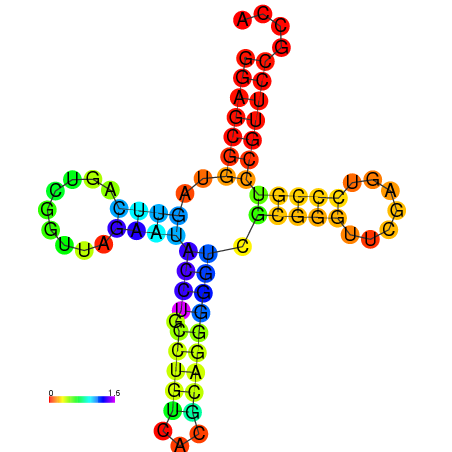
В табл.1 представлена результаты предсказаний структуры тРНК. Можно заметить, что по алгоритму Зукера полученная структура имеет на 2 канонических пары больше, чем реальная структура. Это отличие наблюдается в антикодоновом стебле. В предсказанной структуре на рис.1 имеется выпетливание, а рядом с ним - остаток уридина, который на этом рисунке отмечен фиолетовым цветом. Это говорит о том, что он находится в очень неустойчивом положении, его энтропия достаточно высока. Возможно в реальной структуре именно из-за этого неусточивого положения уридина более выгодной считается структура с меньшим количеством канонических пар.
| Участок структуры тРНК | Позиции в структуре (по результатам find_pair) | Результаты предсказания с помощью einverted | Результаты предсказания по алгоритму Зукера |
| Акцепторный стебель | 5'-601-607-3' 5'-666-672-3' Всего 7 пар | Предсказано 6/7 пар | Предсказано 7/7 пар |
| D-стебель | 5'-610-613-3' 5'-622-625-3' Всего 4 пары | Предсказано 1/4 пар | Предсказано 4/4 пар |
| Антикодоновый стебель | 5'-626-632-3' 5'-638-644-3' Всего 7 пар | Предсказано 4/7 пар | Предсказано 9/7 пар |
| T-стебель | 5'-649-653-3' 5'-661-665-3' Всего 5 пар | Предсказано 0/5 пар | Предсказано 5/5 пар |
| Общее число канонических пар нуклеотидов | 23 | 11 | 25 |
Исходный ДНК-белковый комплекс - PDB ID: 1LQ1
Это задание выполнялось с помощью JMol. Вначале был создан скрипт, который в JMol последовательно дает изображение всей структуры, только ДНК в проволочной модели, той же модели но с выделенными шариками множеством атомов set1, затем set2 и set3. Обозначения:
set 1 - множество атомов кислорода 2'-дезоксирибозы
set 2- множество атомов кислорода в остатке фосфорной кислоты
set 3 - множество атомов азота в азотистых основаниях
Cсылка на скрипт: script1.txt
Далее перейдем непосредственно к описанию ДНК-белковых контактов в заданной структуре. Будем считать полярными атомы кислорода и азота, а неполярными - атомы углерода, фосфора и серы. Назовем полярным контактом ситуацию, в которой расстояние между полярным атомом белка и полярным атомом ДНК меньше 3.5A. Аналогично, неполярным контактом будем считать пару неполярных атомов на расстоянии меньше 4.5A. Напишем срипт, который будет учитывать все наши пожелания.
Итак, результаты представлены в табл.2:
| Контакты атомов белка(цепь D) с | Полярные | Неполярные | Всего |
| остатками 2'-дезоксирибозы | 1 | 8 | 9 |
| остатками фосфорной кислоты | 7 | 5 | 12 |
| остатками азотистых оснований со стороны большой бороздки | 2 | 12 | 14 |
| остатками азотистых оснований со стороны малой бороздки | 0 | 0 | 0 |
Анализируя данную таблицу, можно сделать вывод о том что в образовании ДНК-белковых контактах преимущественно участвуют неполярные атомы 2'-дезоксирибозы, полярные атомы фосфорной кислоты и неполярные атомы азотистых оснований со стороны большой бороздки. Атомы азотистых оснований со стороны малой бороздки вообще не принимают участия в образовании ДНК-белковых контактов.
Cхема ДНК-белковых контактов
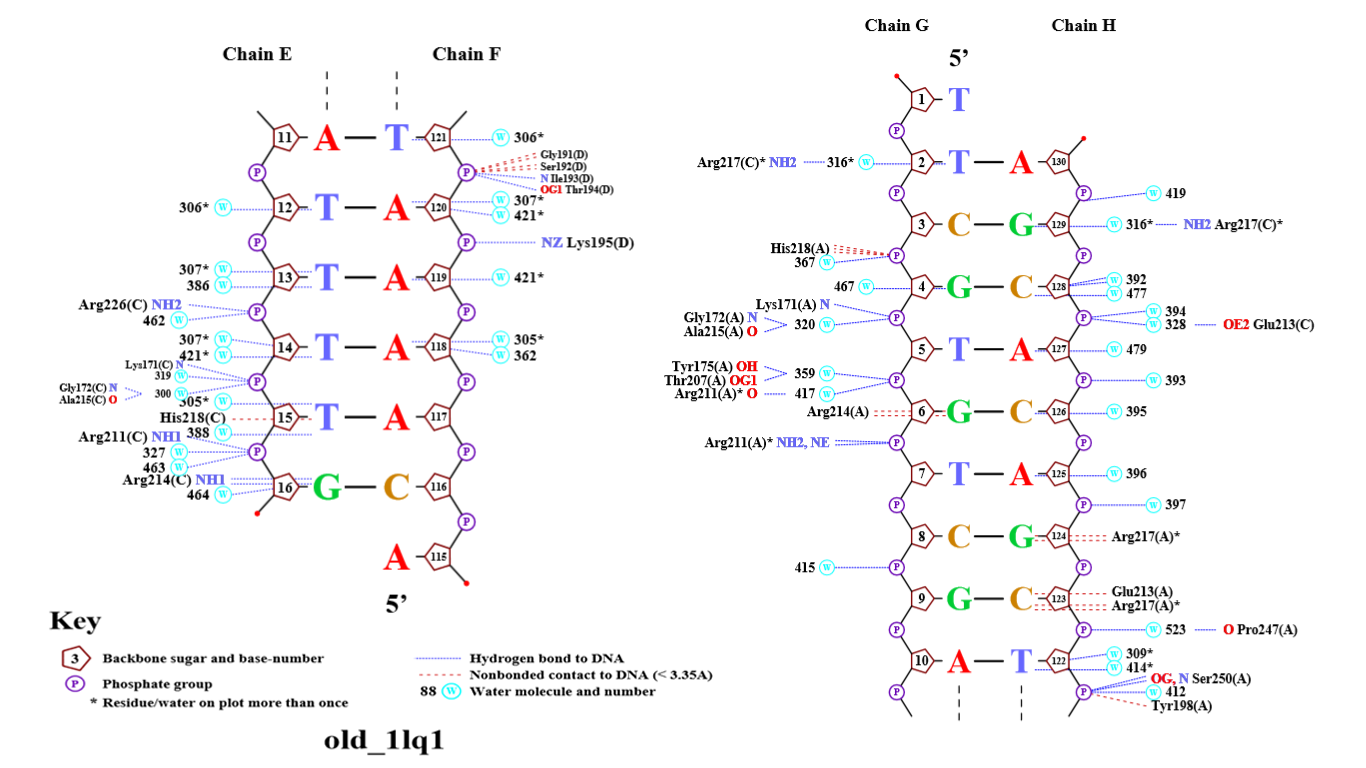
Для получения популярной схемы ДНК-белковых контактов была использована программа nuclpot. В результате были получены рис.2 - рис.3.
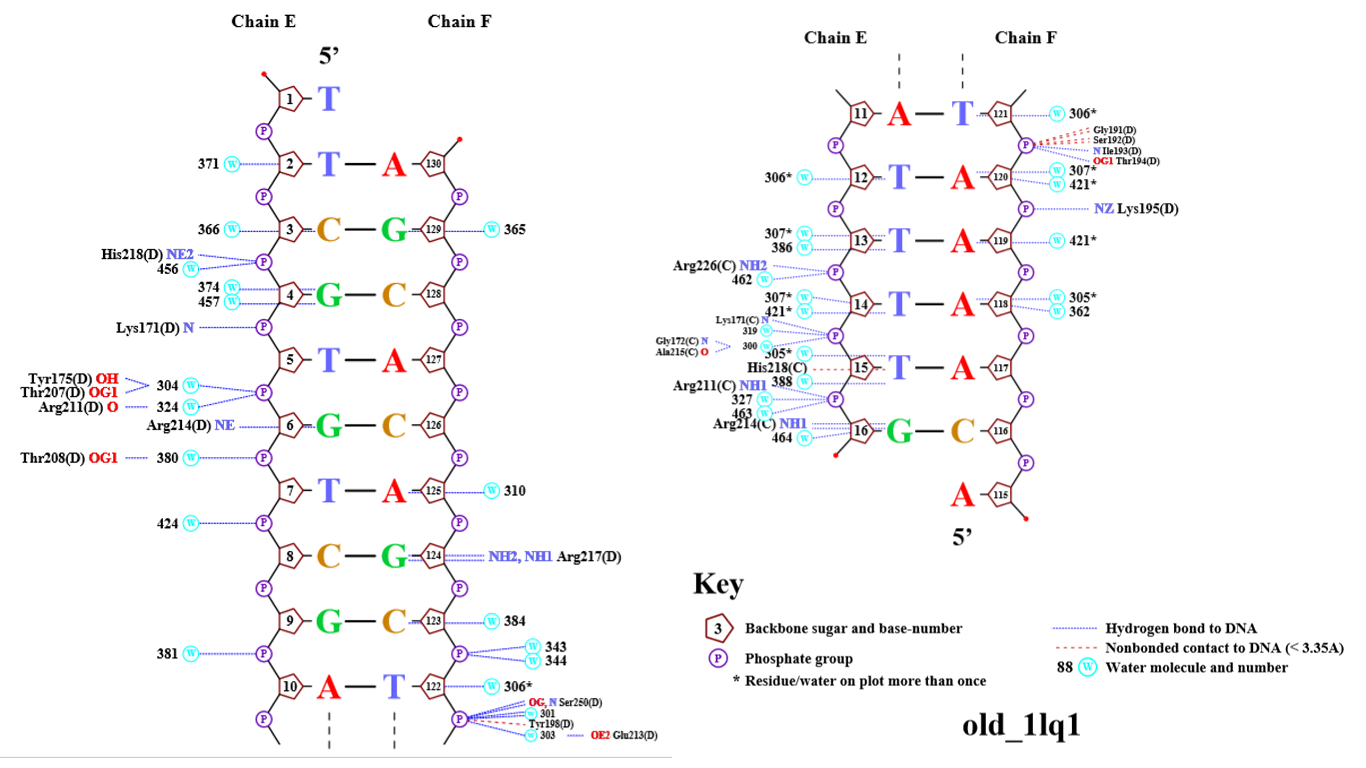
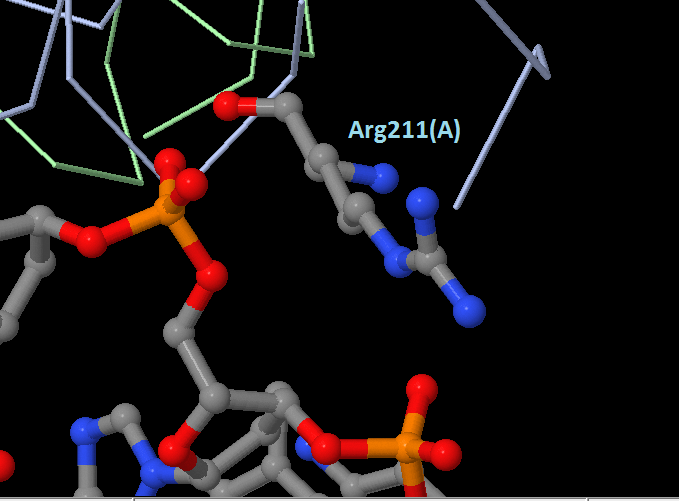
Аминокиcлотный остаток с наибольшим числом указанных на схеме контактов - Arg211(A). Он образует 3 водородные связи с двумя остатками фосфорной кислоты ДНК.
Наиболее важным для распознавания последовательности ДНК я считаю остаток Arg217(C), так как он образует водородные связи сразу с двумя цепями ДНК (H и G), причем связывается непосредственно с азотистым основанием.
 |
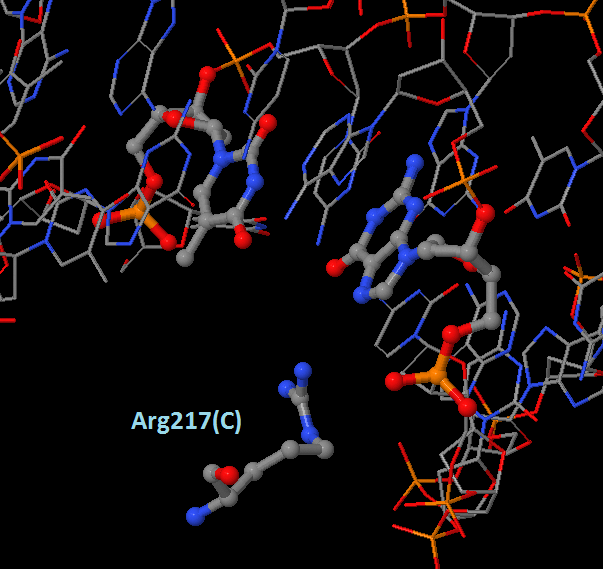 |
| Рис. 4.Arg211(A) - аминокислотный остаток с наибольшим числом контактов | Рис. 5.Arg217(С) - наиболее важный остаток для распознавания последовательности ДНК |
© Васильева Елена, 2015