| Учебный сайт Саши Погорельской |

|
|
||||||
| Главная | Семестры | Скрипты | Обо мне | Ссылки | ||
|
|
EMBOSS С помощью поиска по сайту ENA я получила файл с записью D89965 банка EMBL. Он содержит последовательность гена серой крысы, вовлеченного в сигнальную трансдукцию посредством рецепторов серотонина. Программа getorf пакета EMBOSS выдает набор трансляций открытых рамок заданной последовательности. Нам нужно получить все, обладающие следующими
свойствами: При этом использовалась следующая команда:
Первые две опции заданы по умолчанию, опция find определяет границы открытой рамки. В результате работы программы было получено 9 фрагментов. Файл можно скачать здесь. По координате и последовательности больше всего похожа на аннотированную пятая. Запись EMBL ссылается на запись в Uniprot/Swissprot с идентификатором P0A7B8. Эта запись соответствует одной из субъединиц АТФ-зависимой протеазы бактерии Escherichia coli. При чем последовательность белка отличается от представленной в базе данный EMBL. Swissprot - база с проверенными белками, поэтому если есть ошибка, то она, вероятнее всего, в аннотации EMBL. Последовательность получена из желудка крысы, а EColi - кишечная палочка, значит, при исследовании последовательность белка бактерии могли принять за белок мыши. Но ошибка, видимо, была обнаружна и ссылка указывает на настоящий источник последовательности. Следующий объект работы - файлы-списки. С помощью программы seqret пакета EMBOSS был получен список всех последовательностей алкогольдегидрогеназ базы данных SqissProt. При этом использовалась следующая команда:
Результат в формате фаста можно посмотреть здесь. Файл с универсальными адресами последовательностей представлен здесь. Он был получен при выполнении команды:
После этого из него надо было выбрать все последовательности, относящиеся к следующим организмам: DROHA, DROGU, NAJNA, DROMY, GEOKN, MALDO, DROAD, с использованием команды grep. Чтобы получить фаста-файл с ними использовалась команда seqret:
Случайная модель для оценки качества выравнивания Для проверки этой модели я использовала выранивание двух белков из предыдущего задания: белки алкогольдегидрогеназы домашней яблони и плодовой мушки. С помощью программы shuffle, я получила 100 случайных перемешивания последовательности из дрозофилы. Веса выравниваний всех полученных последовательностей с белком яблони лежат в интервале от 29,5 до 70. На рисунке 1 представлена гистограмма распределения весов с шагом 2. Файл с расчетами можно скачать здесь. 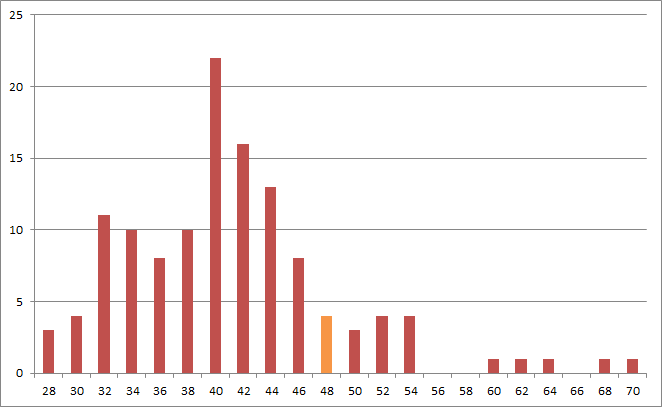
Рисунок 1. Распределение весов 101 выравнивания, одно из которых свяляется выравниванием двух алкогольдегидрогеназ. Столбик, содержащий это выравнивание выделен оранжевым цветом. Весанализируемого выравнивая близок 3 рандомным последовательностям, что видно из гистограммы на рисунке 1. Оно не входит в самые высокие столбцы (столбцы с наибольшим количеством выравниваний, близких по весу), что означает возможную гомологию последовательностей. Однако сходная ситуация у достаточно большого количества выравниваний. Это означает, что вероятность гомологии довольно низкая. Это можно объяснить большим различием таксономических групп, к которым относятся организмы. |
||||||||||||||||||
| © Pogorelskaya Sasha | Last modification date: 19.02.15 | |||||||||||||||||||